本文主要是介绍【IR 论文】HyDE:让 LLM 对 query 做查询改写来改进 Dense Retrieval,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:Precise Zero-Shot Dense Retrieval without Relevance Labels
⭐⭐⭐⭐
CMU, ACL 2023, arXiv:2212.10496
Code: github.com/texttron/hyde
文章目录
- 论文速读
- 总结
论文速读
在以往的 dense retrieval 思路中,需要对 input query 做 encode 来得到 vector,并于 passages 的 vector 做相似度计算实现检索。这里面的 dense encoder 需要把有相关性的 query 和 docs 映射到相近的位置,这就存在两个缺点:
- dense encoder 需要大量的数据去 learn
- Hard to generalize when definition of relevance changes
但在现实世界中:
- 可以用于 train 的具有相关性关联的 data 并不多
- 检索的需求是多种多样的:
- 不同的企业或机构有不同的需求
- 用户的需求也在随着时间发生改变
这就导致了以往的 dense retrieval 的思路并不好用。
本文提出的 HyDE 的思路如下:
HyDE 框架中,没有训练或微调任何 LLM
- 给定一个 user query,通过 LLM 的 instruction-following 的能力,让 LLM 先生成一个对于这个 query 的杜撰的 document:“Hypothetical Document”
- 使用一个 dense encoder 将这个 Hypothetical Document 编码为 vector:“Hypothetical Document Embedding”
- 在 document embedding space 中进行检索
其中,denser encoder 可以是一个非常 weak 的模型,仅仅通过无监督的对比学习就可以完成训练。
HyDE 的特点是,不再需要做 query - document 的 mapping,而是让 LLM 先生成一个伪文档,然后通过这个伪文档来完成检索。从而弥补了 input query 与 corpus 之间的 gap。
HyDE 的整体示例如下图所示:
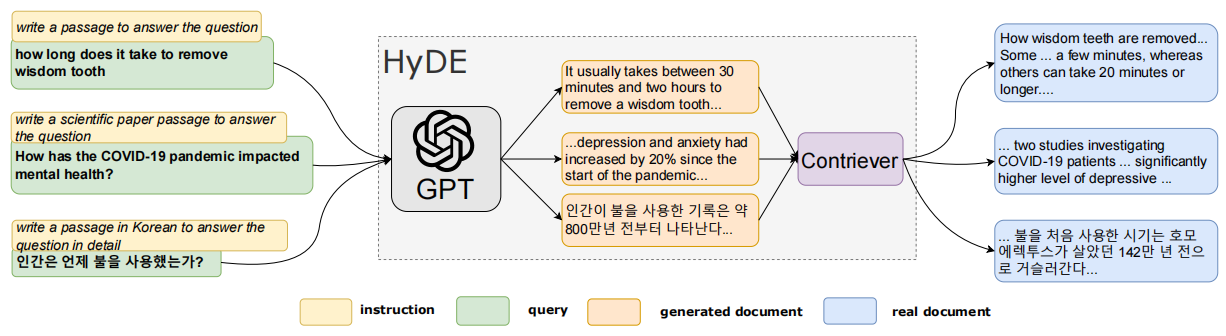
总结
HyDE 提供了一种以完全无监督的方式来构建有效的 dense retriever 的新思路,他的训练不需要任何相关联的 query-doc pair 作为训练资料。
论文指出,HyDE 主要用于搜索系统的部署前期,这时候缺少可用的训练素材,HyDE 可以提供与微调模型相当的表现。随着搜索系统的使用,搜索日志和相关性数据逐渐积累, 就可以逐步训练并推出有监督的 dense retriever 来提供其 in-domain 的专业能力。
这篇关于【IR 论文】HyDE:让 LLM 对 query 做查询改写来改进 Dense Retrieval的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




