本文主要是介绍Elasticsearch中【文档查询】DSL语句以及对应的Java实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
全文检索查询
精准查询
布尔查询
排序、分页查询
高亮
地理查询
复合查询
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
查询所有:查询出所有数据,一般测试用。例如:match_all
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
match_query
multi_match_query
精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
ids
range
term
地理(geo)查询:根据经纬度查询。例如:
geo_distance
geo_bounding_box
复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
bool
function_score
全文检索查询
单字段查询DSL:
GET /indexName/_search
{"query": {"match": {"字段名": "查询内容"}}
}例子:
多字段查询DSL:(搜索字段越多,对查询性能影响越大 ,所以建议在创建索引时使用copy_to字段约束,将需要参与搜索的字段复制到all字段中)
例如创建索引时,"name"字段设置了"copy_to"参数,将其值复制到"all"字段中。这意味着当你在Elasticsearch中索引一个文档时,文档的"name"字段的值会被同时复制到"all"字段中。这样一来,如果你想要在文档的所有字段中进行全文本搜索,只需要搜索"all"单个字段即可,而不需要分别搜索每个字段。
这样对all进行单字段查询,性能也有很大提高。

GET /indexName/_search
{"query": {"multi_match": {"query": "搜索内容","fields": ["字段名1", " 字段名2"]}}
}Java实现全文查询:
依赖引入可查看我另一张博文第三部分:
//1.准备RequestSearchRequest request = new SearchRequest("hotel");//2.准备DSLrequest.source().query(QueryBuilders.matchAllQuery());//3.发生请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);
对SearchResponse返回结果进行处理:
//获取最外层的hitsSearchHits hits = response.getHits();//获取总条数TotalHits totalHits = hits.getTotalHits();//获取里层的hitsSearchHit[] searchHits = hits.getHits();//遍历每条数据for (SearchHit hit : searchHits) {//获取文档 _idString docId = hit.getId();//获取每条数据的_source部分(json数据),获取后做下一步处理String sourceAsString = hit.getSourceAsString();}返回数据格式
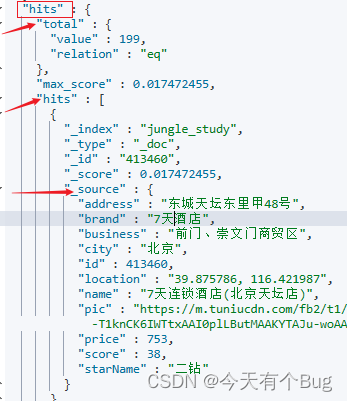
各种查询主要不同的 是query()中构建的是何种查询,例如这里是match_all查询
构建match查询
QueryBuilders.matchQuery("name","酒店")精准查询
DSL语句:
GET /jungle_study/_search
{"query": {"term": {"city": {"value": "北京"}}}
}构建精确查询
QueryBuilders.termQuery("city","北京")布尔查询
复合查询的一种
bool查询中的逻辑关系:
must:必须匹配的条件,可以理解为“与”
should:选择性匹配的条件,可以理解为“或”
must_not:必须不匹配的条件,不参与打分
filter:必须匹配的条件,不参与打分
DSL:(查询name字段有酒店,并且价格范围在100-500之间的数据)
GET /jungle_study/_search
{"query": {"bool": {"must": [{"term": {"city": "北京"}},{"range": {"price": {"gte": 100,"lte": 500}}}]}}
}
gte : >= 大于或等于
lte : <= 小于或等于
gt : > 大于
lt : < 小于
构建布尔查询
QueryBuilders.boolQuery();
//添加查询条件
boolQuery.must(QueryBuilders.termQuery("city","上海")); //精确查询,添加city精确匹配条件
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(100).lte(500)); //范围查询 ,添加条件价格在100-250之间
排序、分页查询
DSL:(排序和分页与query同级)

from :从哪条数据开始查
size :查询条数
sort :根据price(价格)倒叙排列查询结果
对应Java代码
// 页码,每页大小int page = 1, size = 5;// 准备RequestSearchRequest request = new SearchRequest("jungle_study");// 准备DSLrequest.source().query(QueryBuilders.matchAllQuery());// 排序 sortrequest.source().sort("price", SortOrder.ASC);// 分页 计算from 和 sizerequest.source().from((page - 1) * size).size(size);从DSL可以看出query和sort、from、size是同级,所以也是request.source()去点
高亮
根据搜索关键词对结果做高亮,就是在关键词中添加 <em></em> html标签
DSL:(也是与query同级)
对查询内容 “酒店” 做高亮,高亮结果是与原数据 _source 同级的 highlight

当我们是使用 all 字段(对所有做过copy_to约束的字段)去做搜索时,需要配置require_field_match属性为false,表示不与查询字段 all 做匹配

Java代码:
//用request.source()去点,进行配置高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));获取高亮结果:
// 根据字段名获取高亮结果HighlightField highlightField = highlightFields.get("name");//不为空时才做下一步处理,if (highlightField != null) { // 获取高亮值String name = highlightField.getFragments()[0].string();//可以覆盖原来的值}地理查询
矩形范围查询DSL:
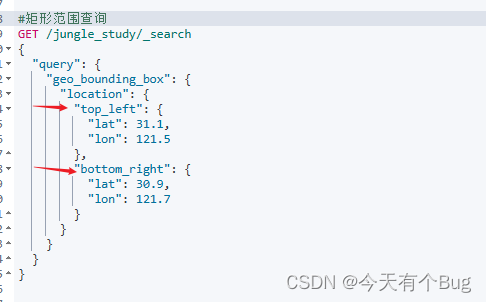
top_left : 左上坐标点
bottom_right :右下坐标点
范围查询
查询一个坐标点的五公里范围内的数据
#根据中心点做范围查询
GET /jungle_study/_search
{"query": {"geo_distance": {"distance": "5km", "location": "31.21,121.5" }}
}"121.5" 是经度(longitude)
"31.21" 是纬度(latitude)
Java中实现:
构建矩形范围查询条件
GeoBoundingBoxQueryBuilder location = QueryBuilders.geoBoundingBoxQuery("location");
//左上坐标点
GeoPoint geoPoint = location.topLeft();
geoPoint.resetLat(31.21);
geoPoint.resetLon(121.5);
//右下坐标点
GeoPoint bottomRight = location.bottomRight();
bottomRight.resetLat(31.21);
bottomRight.resetLon(121.5);构建距离范围查询条件
QueryBuilders.geoDistanceQuery("location").distance("5km");复合查询
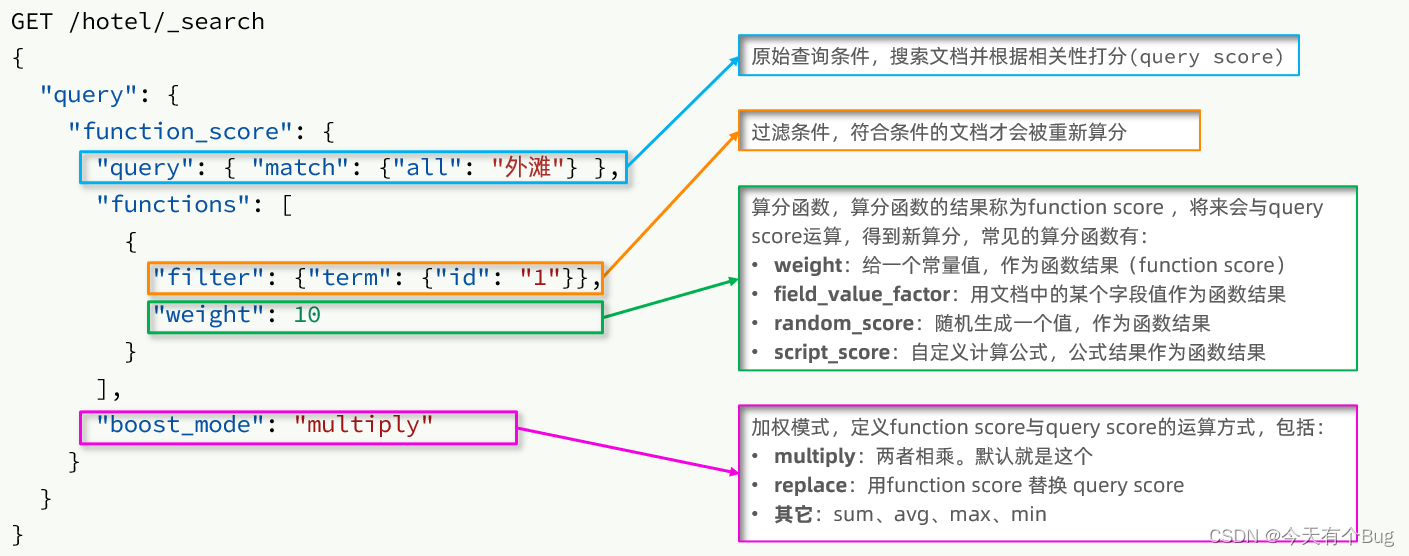
常见的有两种 布尔查询 和 算分函数查询
查询结果中有 _score 代表与搜索词条的关联度打分,结果按照分值降序排列,分越高则排在最前
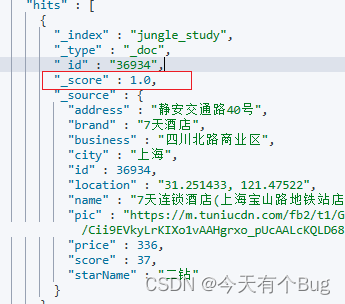
ES中使用BM25算法进行词条和文档的相关度做打分。
DSL:
GET /jungle_study/_search
{"query": {"constant_score": {"filter": {"term": { "user.id": "kimchy" }},"boost": 1.2}}
}
有关复合查询的官方文档地址:Constant score query | Elasticsearch Guide [7.16] | Elastic
这篇关于Elasticsearch中【文档查询】DSL语句以及对应的Java实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







