本文主要是介绍Kafka客户端工具:Offset Explorer 使用指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Kafka作为一个分布式流处理平台,在大数据处理和实时数据流应用中扮演着至关重要的角色。管理Kafka的topics及其offsets对于维护系统稳定性和数据一致性至关重要。Offset Explorer是一个强大的桌面应用程序,它使得管理和监控Kafka集群变得简单直观。本文将引导您如何下载、安装并使用Offset Explorer 3.0来探索Kafka的世界,包括连接Kafka集群、查看主题、消息以及如何新建主题和添加消息。
1. 下载与安装
下载链接
- Offset Explorer 3.0 (推荐): 点击下载
- Offset Explorer 2.3.5: 点击下载
安装步骤
- 从上述链接中选择合适的版本下载安装包。
- 双击下载的
.exe文件,按照安装向导的指示完成安装过程。 - 安装完成后,桌面上会出现
Offset Explorer的快捷方式。
2. 连接Kafka集群
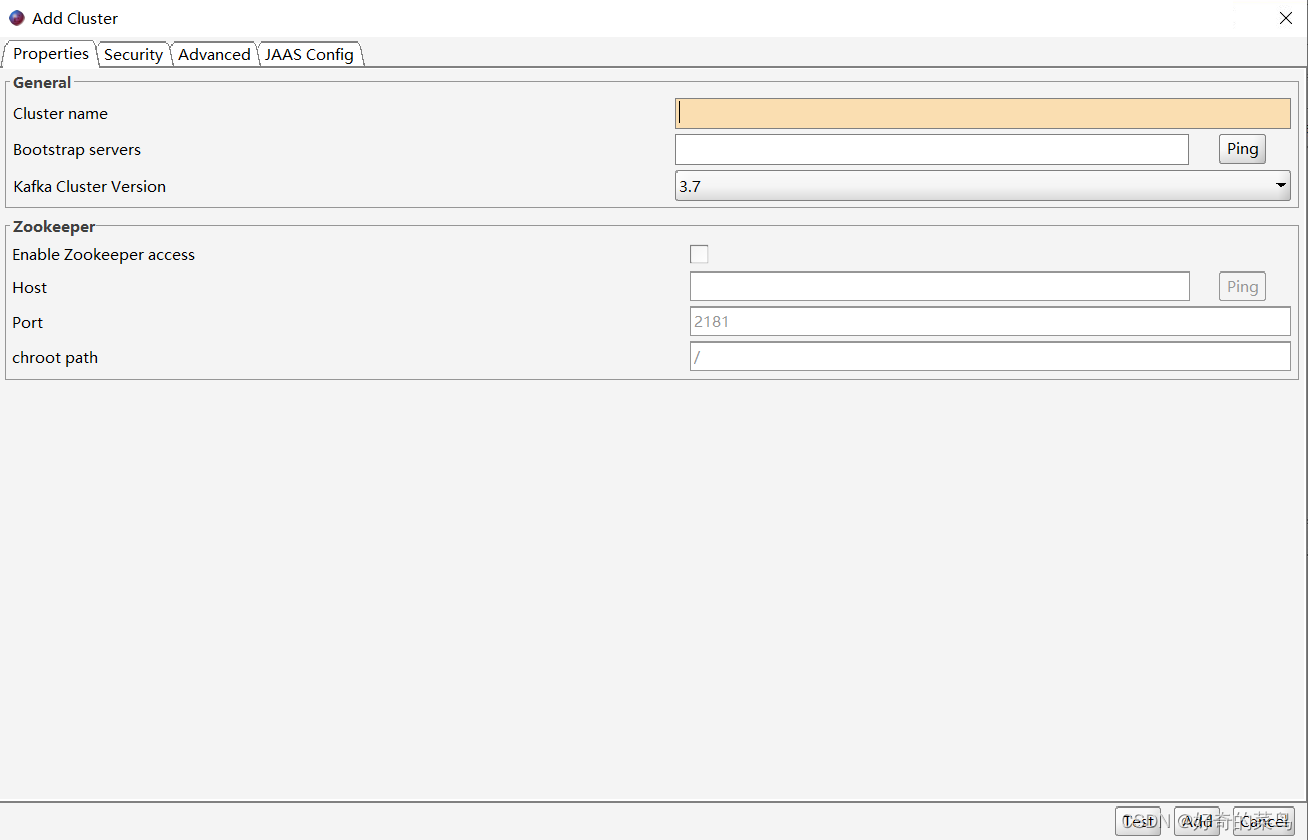
启动Offset Explorer后,首先需要配置连接到您的Kafka集群:
- 打开
File菜单,选择New Connection...或直接点击界面中的+按钮。 - 在弹出的对话框中输入Kafka集群的相关信息,包括:
- Name: 给这个连接起一个易于识别的名字。
- Bootstrap Servers: Kafka集群的地址,格式如
host1:port1,host2:port2。 - Security Settings: 如有安全设置(如SASL认证),在此处配置。
- 点击
Test Connection测试是否成功连接,无误后点击Save保存连接配置。
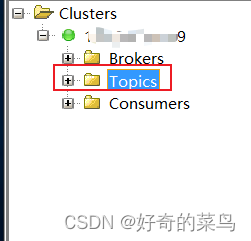
3. 查看主题
成功连接后,Kafka的所有主题将会显示在左侧导航栏:
- 点击任一主题,右侧会列出该主题的所有分区及每个分区的offset信息。
- 可以通过搜索框快速查找特定主题。
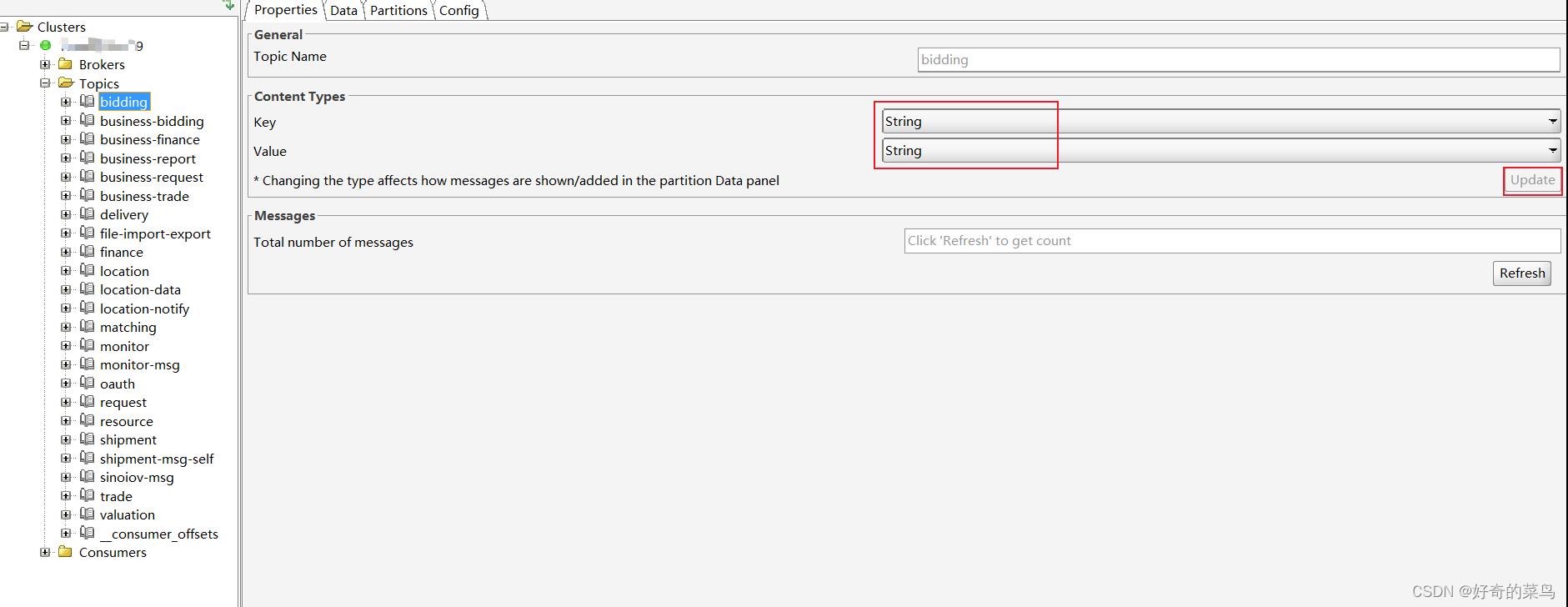
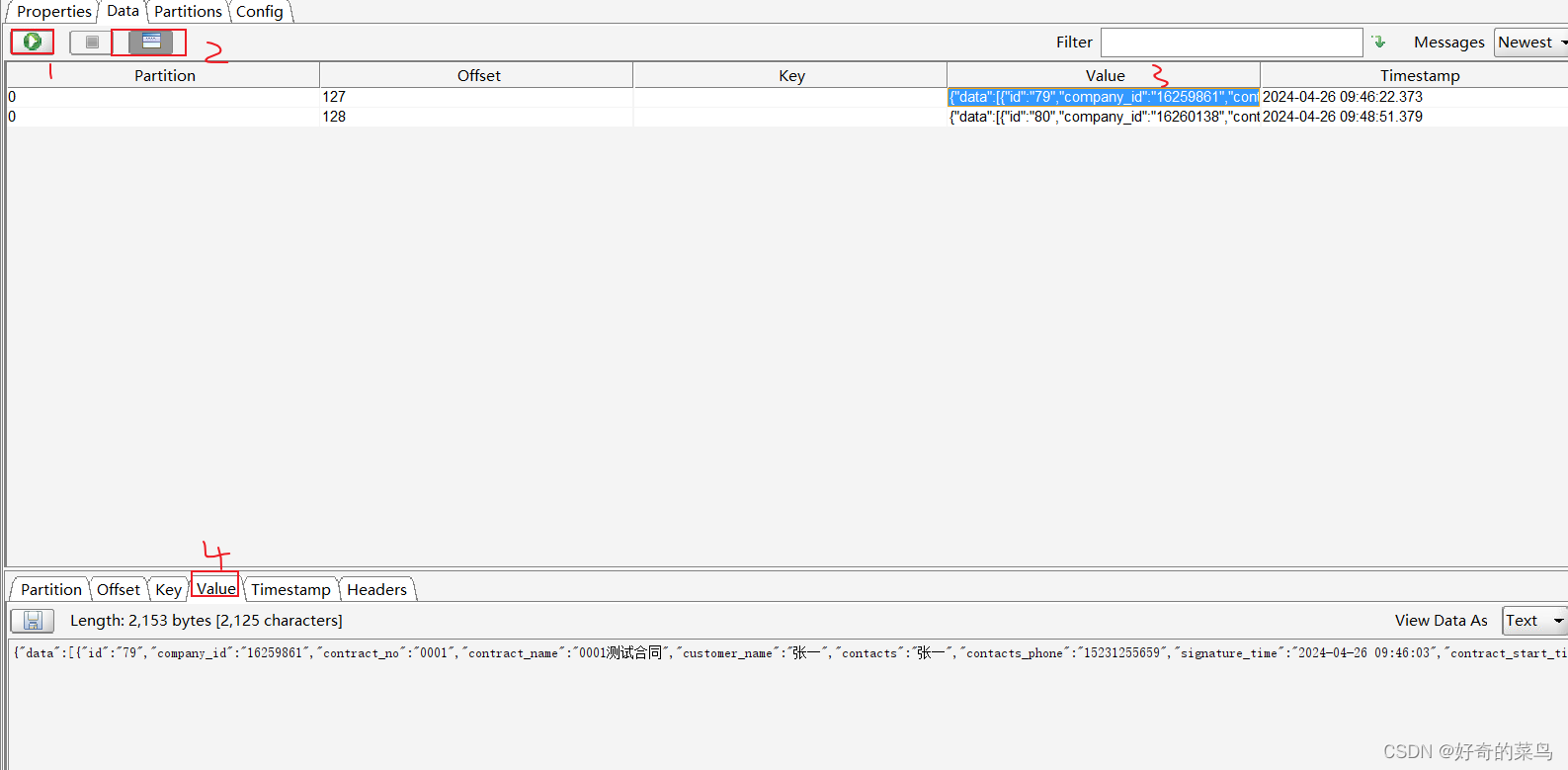
4. 查看消息
要查看某个主题的消息内容:
- 在左侧选择想要查看的主题。
5. 新建主题
Offset Explorer也支持创建新的Kafka主题:
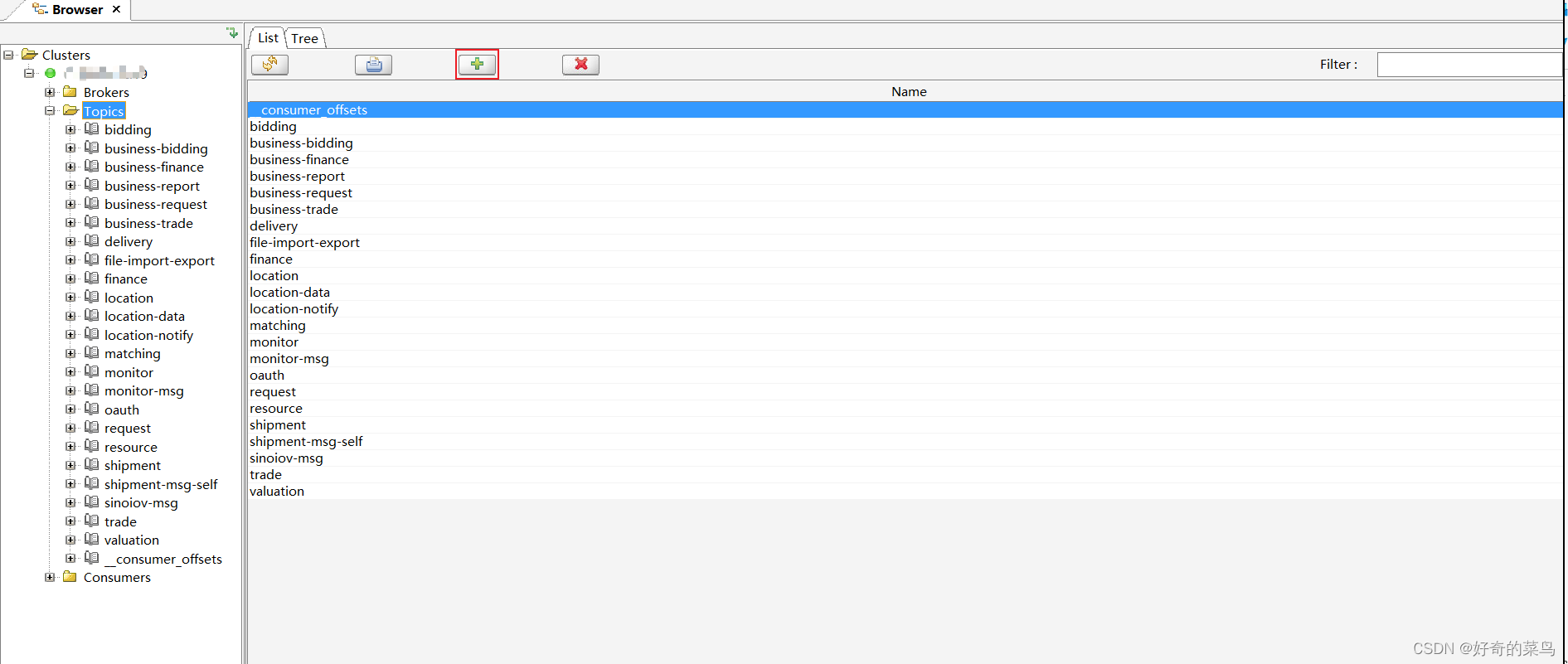
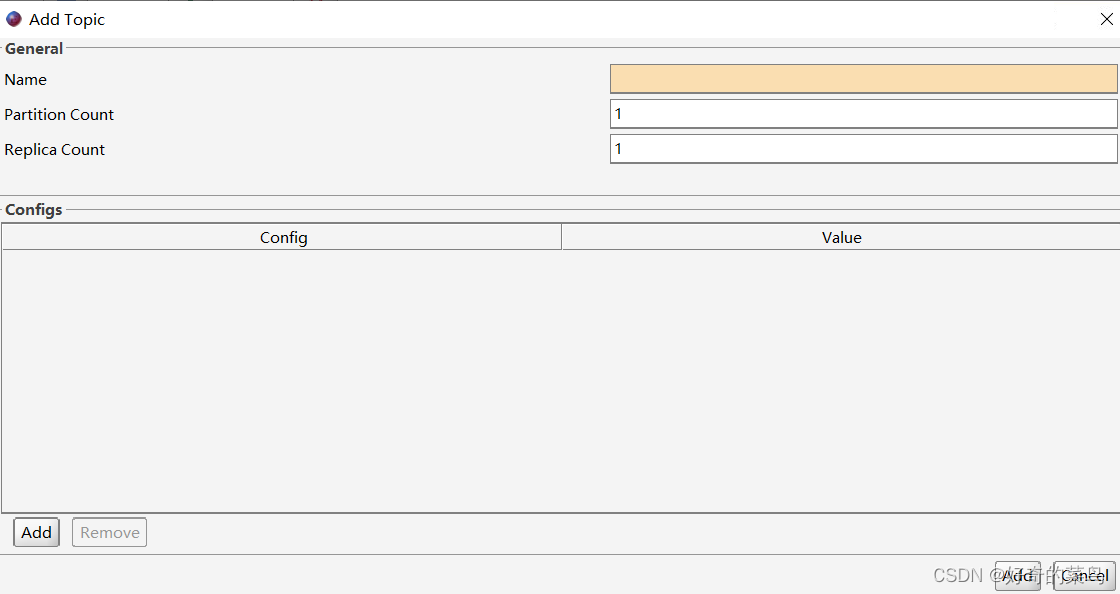
6. 添加消息
目前,Offset Explorer主要用于查看和管理offset,直接在界面中添加消息的功能并不直接提供。但您可以使用Kafka的命令行工具kafka-console-producer.sh或集成的生产者工具(如许多开发环境中的生产者示例)来发送消息至指定主题。
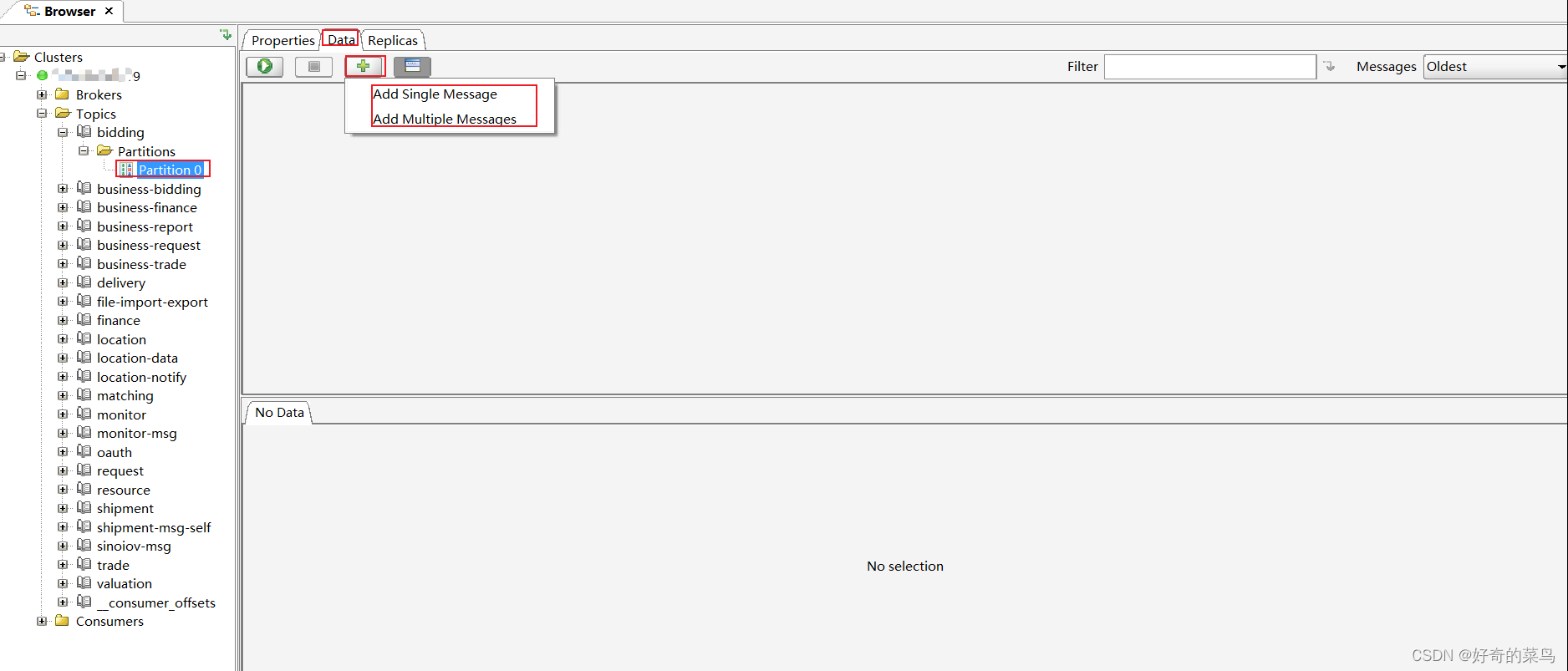
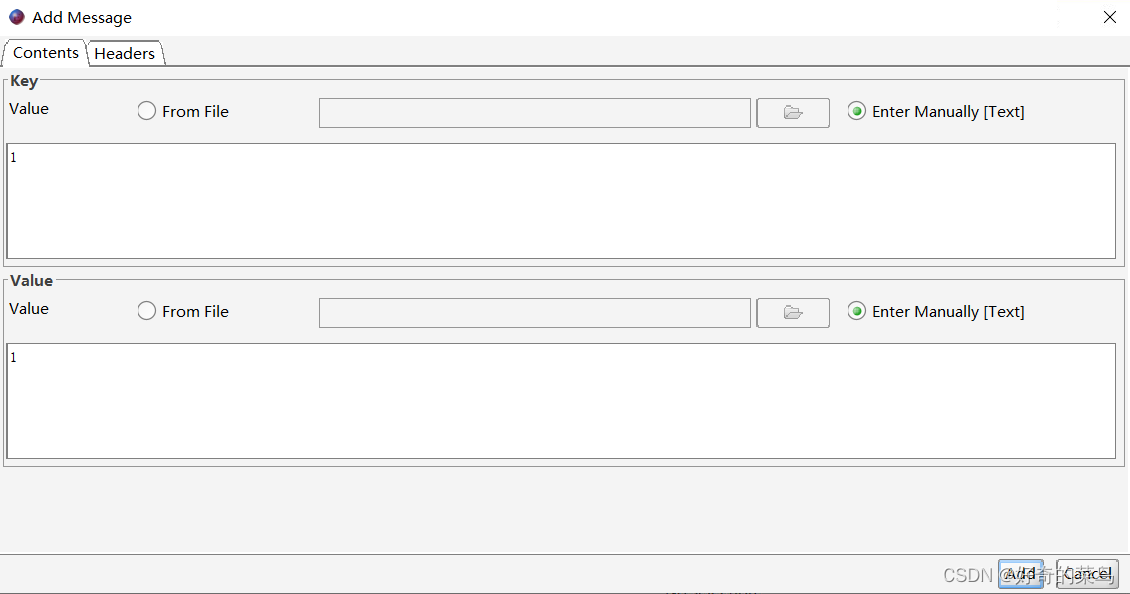
使用命令行发送消息示例:
kafka-console-producer.sh --broker-list localhost:9092 --topic your_topic_name
然后在出现的命令行界面中直接输入消息内容并回车即可发送。
通过以上步骤,您已经掌握了使用Offset Explorer进行Kafka集群的基本管理和消息查看操作。无论是监控offset状态还是进行基础的集群维护,Offset Explorer都是一个非常实用的工具。
这篇关于Kafka客户端工具:Offset Explorer 使用指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






