本文主要是介绍Druid Supervisor启动task流程分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
继前一篇文章关于supervisor启动流程分析的启动过程,然后来分析一下supervisor启动后是如何启动并管理task的运行的。又是如何将KafkaTask的对象创建的。
上图
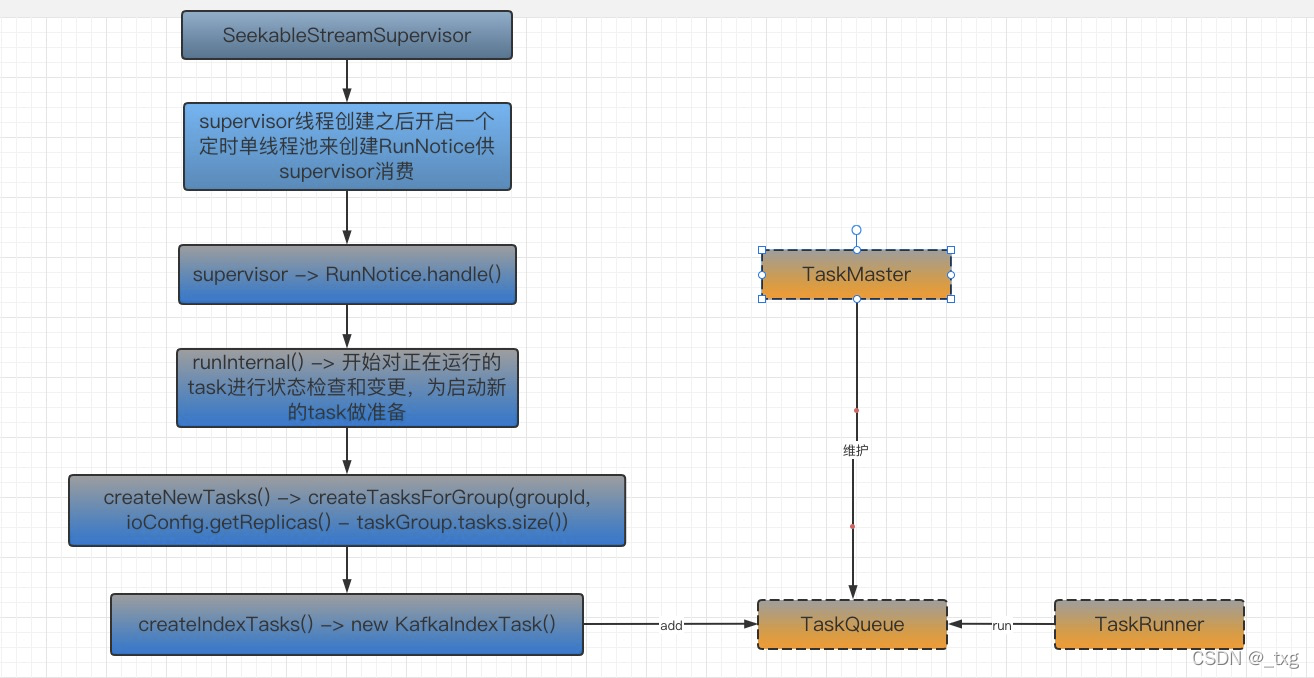
创建完持续执行的supervisor线程后,紧接着通过一个定时的单线程池来创建RunNotice()对象并放入notice队列中供supervisor进行poll并运行handle()方法。定时的时间则是配置的task的运行周期,默认是1秒。
当supervisor获取到RunNotice的时候,开始执行RunNotice的hadle(), 然后开始执行创建task并将创建的kafkaTask添加到TaskMaster管理的TaskQueue中供taskRunner执行。整个task的创建和被执行的过程是消费者模式启动的。
taskRunner调用task的start方法后开始具体的数据传输。此处的taskRunner包含:ForkingTaskRunner、HttpRemoteTaskRunner、RemoteTaskRunner、SingleTaskBackgroundRunner 四种实现。具体每中taskRunner的创建过程以及操作原理在后面的文章中做描述,本篇文章不做描述。
上代码
在类SeekableStreamSupervisor中执行tryInit() 来启动supervisor, 然后紧接着创建定时创建task的线程池。
scheduledExec.scheduleAtFixedRate(buildRunTask(), // 创建RunNotice()对象ioConfig.getStartDelay().getMillis(),Math.max(ioConfig.getPeriod().getMillis(), MAX_RUN_FREQUENCY_MILLIS), // 配置的task执行周期TimeUnit.MILLISECONDS);具体创建task入口则是RunNotice的handle()方法:
private class RunNotice implements Notice{@Overridepublic void handle(){long nowTime = System.currentTimeMillis();// // MAX_RUN_FREQUENCY_MILLIS 是任务的运行周期,默认是一秒, 如果配置的是2个小时,即2个小时会运行一次runInternal()if (nowTime - lastRunTime < MAX_RUN_FREQUENCY_MILLIS) {return;}lastRunTime = nowTime;// 即2个小时会运行一次runInternal()runInternal();}}如果符合执行的时间要求则执行runInternal()方法:
public void runInternal(){try {/*** 此处省略了很多状态检查以及状态判断变成的操作* 主要是针对现有的task进行状态变更检查,为启动新的task做准备* 这里关于task状态变更的代码可作为细节详解来仔细研究下,具体就是描述了task在切换的时候需要做哪些事情*/if (!spec.isSuspended()) {log.info("[%s] supervisor is running.", dataSource);stateManager.maybeSetState(SeekableStreamSupervisorStateManager.SeekableStreamState.CREATING_TASKS);// 前置操作判断完后开始创建新的taskcreateNewTasks();} else {log.info("[%s] supervisor is suspended.", dataSource);gracefulShutdownInternal();}if (log.isDebugEnabled()) {log.debug(generateReport(true).toString());} else {log.info(generateReport(false).toString());}}catch (Exception e) {stateManager.recordThrowableEvent(e);log.warn(e, "Exception in supervisor run loop for dataSource [%s]", dataSource);}finally {stateManager.markRunFinished();}}调用创建task的方法后,会经过一些列的判断,最终组合封装出task的基本信息,io配置信息,封装分配TaskGroup, 创建出具体的task对象。
createNewTasks() -> createTasksForGroup(groupId, ioConfig.getReplicas() - taskGroup.tasks.size()) -> createIndexTasks() -> new KafkaIndexTask() 创建完task对象后会调用taskMaster得到TaskQueue, 将创建的task对象添加到TaskQueue中供taskQueue进行处理。至此supervisor创建task的工作就做完了。
private void createTasksForGroup(int groupId, int replicas)throws JsonProcessingException{TaskGroup group = activelyReadingTaskGroups.get(groupId);Map<PartitionIdType, SequenceOffsetType> startPartitions = group.startingSequences;Map<PartitionIdType, SequenceOffsetType> endPartitions = new HashMap<>();for (PartitionIdType partition : startPartitions.keySet()) {endPartitions.put(partition, getEndOfPartitionMarker());}Set<PartitionIdType> exclusiveStartSequenceNumberPartitions = activelyReadingTaskGroups.get(groupId).exclusiveStartSequenceNumberPartitions;DateTime minimumMessageTime = group.minimumMessageTime.orNull();DateTime maximumMessageTime = group.maximumMessageTime.orNull();// 根据taskGroupId信息 创建task的IOConfigSeekableStreamIndexTaskIOConfig newIoConfig = createTaskIoConfig(groupId,startPartitions,endPartitions,group.baseSequenceName,minimumMessageTime,maximumMessageTime,exclusiveStartSequenceNumberPartitions,ioConfig);// 根据task的基本信息,创建kafkaTask, 因为可能有副本所以使用ListList<SeekableStreamIndexTask<PartitionIdType, SequenceOffsetType>> taskList = createIndexTasks(replicas,group.baseSequenceName,sortingMapper,group.checkpointSequences,newIoConfig,taskTuningConfig,rowIngestionMetersFactory);// 创建完task后 将task放到taskMaster的队列中,等待被启for (SeekableStreamIndexTask indexTask : taskList) {Optional<TaskQueue> taskQueue = taskMaster.getTaskQueue();if (taskQueue.isPresent()) {try {taskQueue.get().add(indexTask);}catch (EntryExistsException e) {stateManager.recordThrowableEvent(e);log.error("Tried to add task [%s] but it already exists", indexTask.getId());}} else {log.error("Failed to get task queue because I'm not the leader!");}}
}接着来简单看看把task扔给TaskQueue后,TaskQueue是做的什么操作:首先TaskQueue这个对象也是注入的,且是有生命周期的。注入时会调用TaskQueue的start方法。然后启动一个线程来循环处理任务。
@LifecycleStartpublic void start(){giant.lock();try {Preconditions.checkState(!active, "queue must be stopped");active = true;syncFromStorage();managerExec.submit(new Runnable(){@Overridepublic void run(){while (true) {try {manage(); // 开启线程来不断的调用该方案break;}catch (InterruptedException e) {log.info("Interrupted, exiting!");break;}catch (Exception e) {final long restartDelay = config.getRestartDelay().getMillis();log.makeAlert(e, "Failed to manage").addData("restartDelay", restartDelay).emit();try {Thread.sleep(restartDelay);}catch (InterruptedException e2) {log.info("Interrupted, exiting!");break;}}}}});
}TaskQueue启动一个线程在调用manage()方法,那我们来看看manage()方法在干什么?从代码可以看出manage()方法执行结束后该线程也会结束了。之所以加一个循环是为了重试机制。manage()方法中才是真正循环执行task的地方。 对于每个task会被TaskRunner调用并将其run()起来。此时task才是真正的被启动了。关于TaskRunner的内容后续文章在做详细描述。
/*** Main task runner management loop. Meant to run forever, or, at least until we're stopped.*/private void manage() throws InterruptedException{// ....while (active) {giant.lock();try {// ....for (final Task task : ImmutableList.copyOf(tasks)) {if (!taskFutures.containsKey(task.getId())) {final ListenableFuture<TaskStatus> runnerTaskFuture;if (runnerTaskFutures.containsKey(task.getId())) {runnerTaskFuture = runnerTaskFutures.get(task.getId());} else {// Task should be running, so run it.final boolean taskIsReady;try {taskIsReady = task.isReady(taskActionClientFactory.create(task));}catch (Exception e) {log.warn(e, "Exception thrown during isReady for task: %s", task.getId());notifyStatus(task, TaskStatus.failure(task.getId()), "failed because of exception[%s]", e.getClass());continue;}if (taskIsReady) {log.info("Asking taskRunner to run: %s", task.getId());runnerTaskFuture = taskRunner.run(task);} else {continue;}}taskFutures.put(task.getId(), attachCallbacks(task, runnerTaskFuture));} else if (isTaskPending(task)) {// if the taskFutures contain this task and this task is pending, also let the taskRunner// to run it to guarantee it will be assigned to run// see https://github.com/apache/incubator-druid/pull/6991taskRunner.run(task);}}// ....}finally {giant.unlock();}}}END
本篇文章涉及的很多细节性问题都没有展开详细描述,比如task的状态变更、taskGroup的实现与应用、taskRunner注册监听器问题、task的chackpoint的问题、task的消费序列记录问题、task的副本问题、KafkaIndexTask的执行流程(下一篇描述)、TaskQueue的实现、TaskRunner的实现(重点)等等,每一个细节都非常值得研究~~ 。不过本篇重在task创建的大体流程,对task的存在形式整体有个认识。
这篇关于Druid Supervisor启动task流程分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





