本文主要是介绍区间预测 | PSO-RF-KDE的粒子群优化随机森林结合核密度估计多变量回归区间预测(Matlab),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
区间预测 | PSO-RF-KDE的粒子群优化随机森林结合核密度估计多变量回归区间预测(Matlab)
目录
- 区间预测 | PSO-RF-KDE的粒子群优化随机森林结合核密度估计多变量回归区间预测(Matlab)
- 效果一览
- 基本介绍
- 程序设计
- 参考资料
效果一览
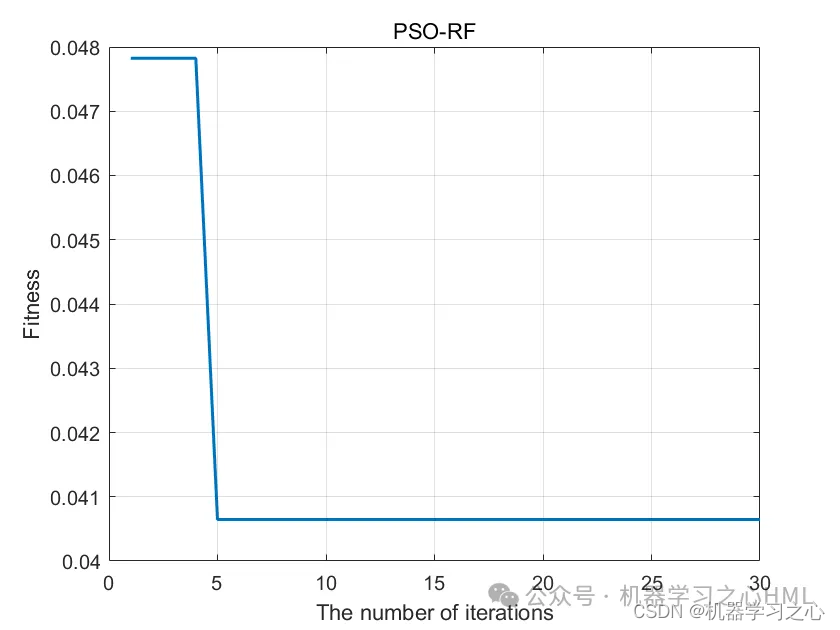
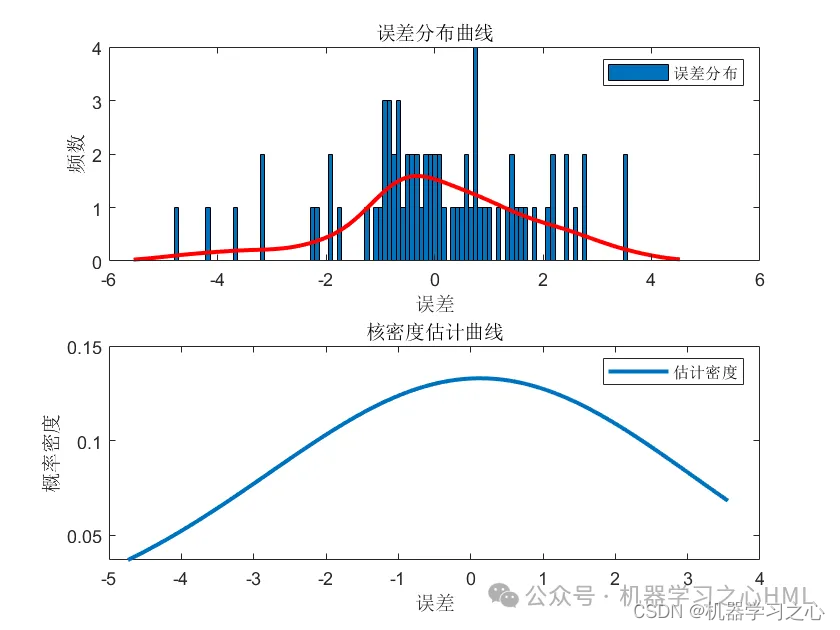
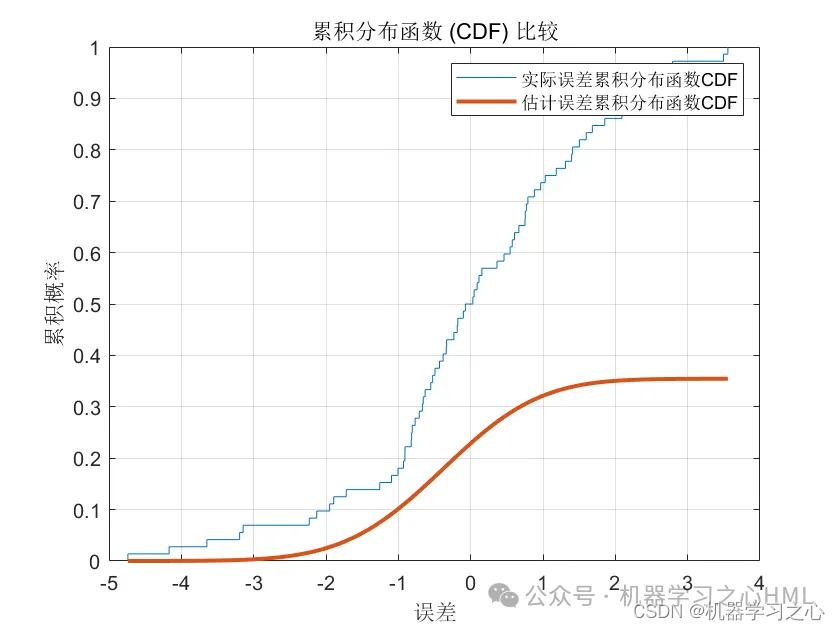
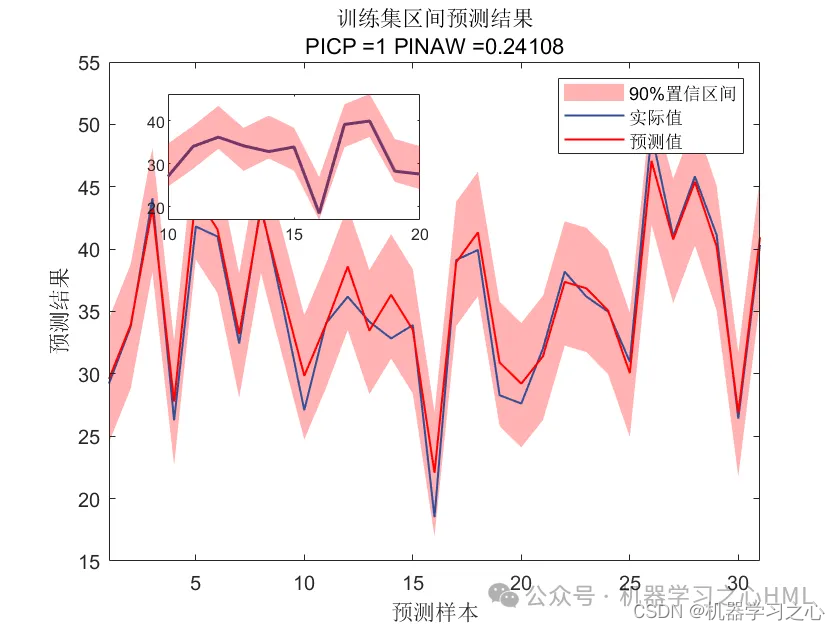
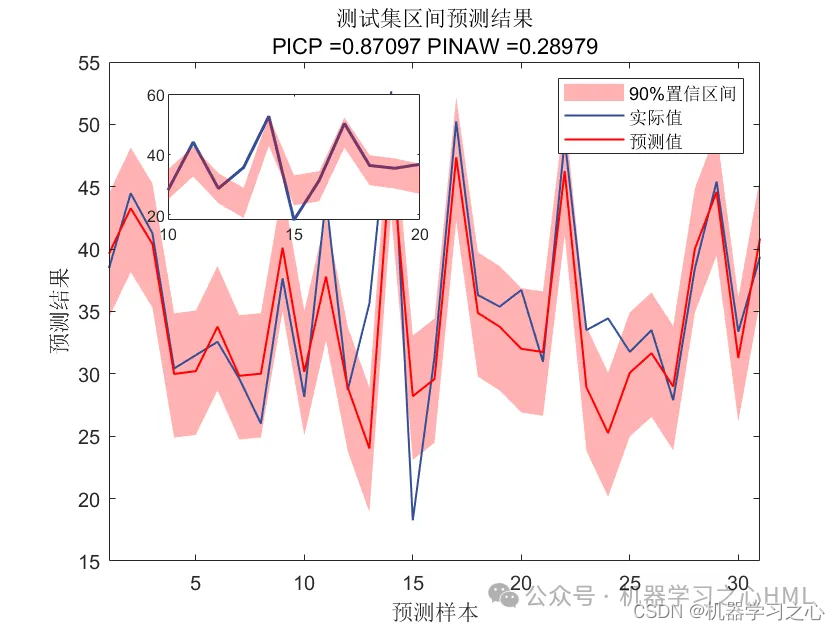
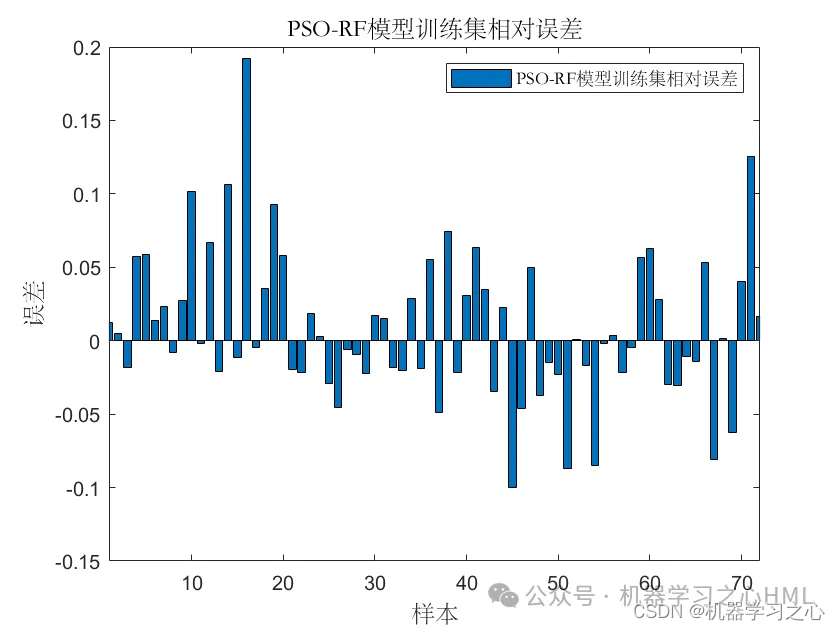
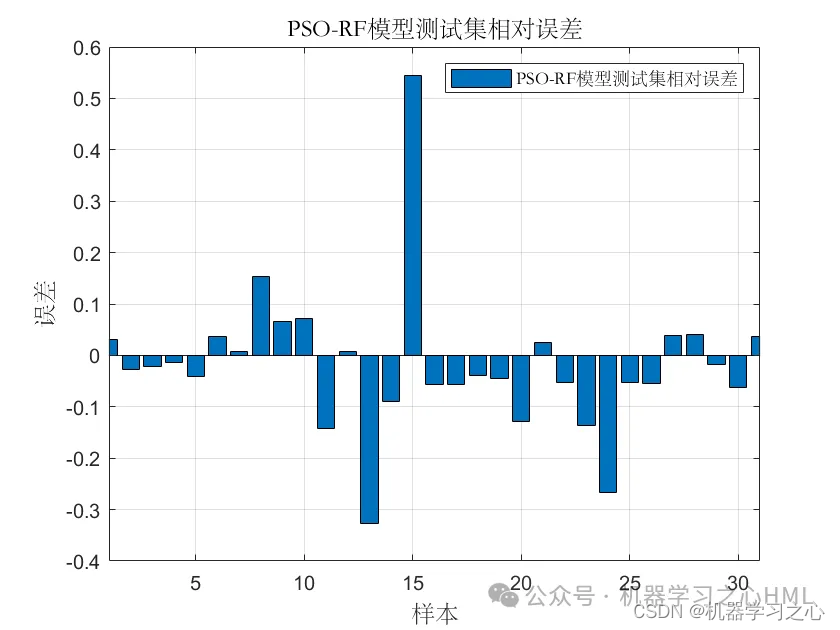
基本介绍
1.Matlab实现PSO-RF-KDE的粒子群优化随机森林结合核密度估计多变量回归区间预测,基于PSO-RF-KDE多变量回归区间预测,PSO-RF-KDE的核密度估计下置信区间预测。
2.含点预测图、置信区间预测图、核密度估计图,区间预测(区间覆盖率PICP、区间平均宽度百分比PINAW),点预测多指标输出(MAE、RMSE、 MSE),多输入单输出。
3.运行环境为Matlab2018b及以上;
4.输入多个特征,输出单个变量,多变量回归区间预测;
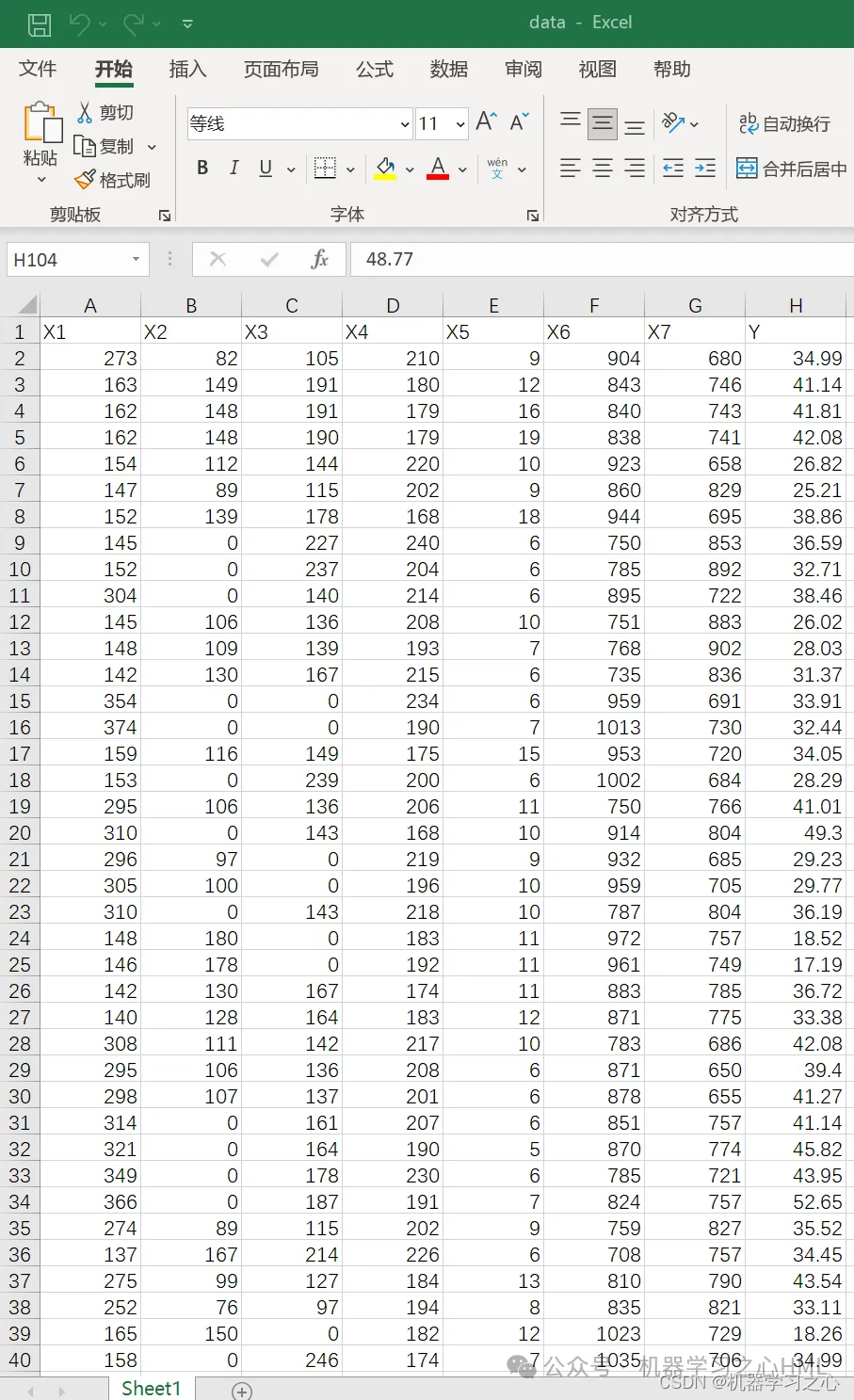
5.data为数据集,main.m为主程序,运行即可,所有文件放在一个文件夹。
PSO-RF-KDE的粒子群优化随机森林结合核密度估计多变量回归区间预测(Matlab)
PSO-RF-KDE的粒子群优化随机森林结合核密度估计多变量回归区间预测(Matlab)。
程序设计
- 完整程序和数据获取方式关注并私信博主回复PSO-RF-KDE的粒子群优化随机森林结合核密度估计多变量回归区间预测(Matlab)。
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行%% 导入数据
res = xlsread('data.xlsx','sheet1');
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);%% 参数初始化
pop=10; %种群数量
Max_iter=30; % 设定最大迭代次数
dim = 2;% 维度为2,即优化两个超参数
lb = [1,1];%下边界
ub = [20,20];%上边界
fobj = @(x) fun(x,p_train,t_train);
[Best_pos,Best_score,curve]=PSO(pop,Max_iter,lb,ub,dim,fobj); %开始优化
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/127931217
[2] https://blog.csdn.net/kjm13182345320/article/details/127418340
这篇关于区间预测 | PSO-RF-KDE的粒子群优化随机森林结合核密度估计多变量回归区间预测(Matlab)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


