本文主要是介绍大菠萝M1内存条应用场景和性价比分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一篇中,冬瓜哥向大家详细介绍了Memory1的基本原理,其逼格还是非常高的,也让冬瓜哥见识了底层体系结构的一种花样玩法,不禁感叹技术无止境。
本文目录:
1. ApacheSpark实测数据
2. MySQL场景实测数据
3. 3dxpoint等介质与M1是威胁还是共生?
那么,M1的适用场景和效果到底怎样,250GB的物理内存+2TB的DIMM接口的Flash换页空间到底适用于哪些场景呢?显然,那些对内存需求量非常高的应用无疑是首选测试对象。另外,如果业务对内存需求量不大,但是该业务需要承载较高的并发量的话,比如启动多个实例,这样的话,加起来对内存的需求量也很大。一些超算环境中,单节点最高配有6TB内存,极为恐怖,可想而知其成本和功耗会有多高。
比如,Apache Spark 以及内存数据库场景。在大数据领域里,Spark便是一个极度依赖内存容量的应用。Spark必须实现尽快的完成对数据对象的创建、缓存、排序、分组、结合等操作,这些对数据对象的处理过程都在内存中进行,访存频率非常高,对内存的容量和速度非常敏感。尤其是排序操作操作,其速度起到关键作用。
然而,目前来讲,单台服务器所能支撑的内存容量,在合理的可接受范围内,实在不足以弥补这些业务对内存的需求。假设配备16GB的内存,双路服务器,假设共16个DIMM槽位,满配不过区区256G内存,对于普通业务完全足够,但是对大数据、内存计算这类场景,杯水车薪。如此小的内存容量,只会导致系统swap换页,此时系统还需配备SSD,比如nvme SSD来承载换页空间来弥补一些性能损失,整个系统的成本又被提升上去了,而且效果也并不佳,因为换页操作流程比较复杂,可能需要数千个CPU周期,而如果内存命中的话则只需要几百周期。再加上从SSD读数据这步操作本身需要大概9k时钟周期,总体上换页产生的时延将会非常高,换页到机械盘就更不用提了。
所以,为了解决这个内存墙问题,人们不得不把数据切分开,然后部署多台服务器集群来解决问题,这个成本的增加不可谓不大。这么做还有个问题则是,资源被隔离,形成烟囱,一旦节点间处理负载不均匀,则可能导致资源闲置,解决办法是跨网络在节点间迁移数据,这就又增加了系统的复杂性,和对前端网络带宽的需求。
综上所述,一个内存计算集群的成本将会比较高,这又进一步反压了集群的规模,受限于成本,集群又不能做的太大。对于不差钱的,即便节点数量可以做的比较高,那么势必又会增加网络规模,此时网络极有可能成为瓶颈。
在高并发量领域,比如互联网,如今大量被使用的MySQL Server和Memcached集群,在成本领域也饱受困扰,大家都在寻找如何能够在尽可能小的集群规模下做更多的事情,也就是提升部署密度,用一台服务器部署更多应用实例,没有什么比直接降低服务器整机台数更能降低成本的了,哪怕在现有服务器内增加一些部件。
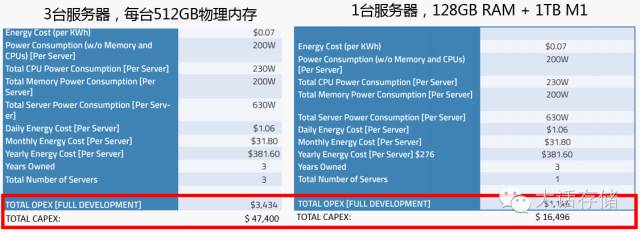
那么,我们看看M1在实际测试中的表现以及对成本的节省力度到底如何。在该测试用例中,利用Spark对500GB的数据做Sort操作。在非M1环境,利用3台浪潮双路服务器,每台配置512GB(16条32GB的RAM)的DDR4 SDRAM物理内存;相应的,采用同样配置的单台服务器,配置128GB(8条16GB的RAM)的物理内存,加上8条128GB(共1TB的换页空间)的M1。

还没开测,就可以知道,单台服务器内部的线程之间不需要跨网络即可实现同步,而三台服务器组成的集群,还需要配置额外的网络交换机,跨网络产生的同步无疑会给系统带来时延。总体成本很显然,单台服务器的配置会低很多。
不妨先来核算对比一下这两个系统的3年的CAPEX和OPEX。可以看到,传统配置的总体拥有成本=$3434+$47400=$50834,而相比之下,M1的配置只有$17640。
再来看看性价比。经过实测,传统配置耗时27.5分钟,而M1的配置则只耗时19.5分钟。换算成性价比之后如下图所示,可以看到其性价比有75%的提升,这个结果还是非常诱人的。

再来看一下Spark Graph计算方面的加速效果,
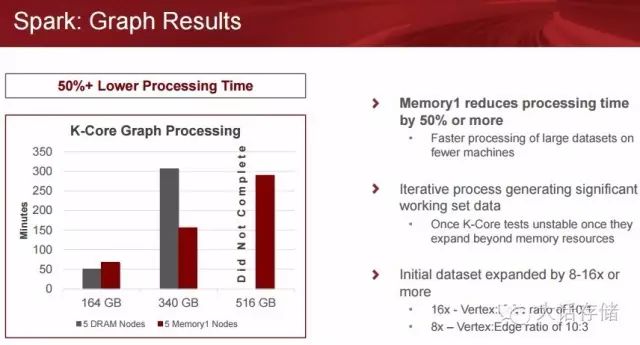

M1在Spark加速方面的总结:
-
在同样的集群规模下, M1完成大数据量的JOB时间是全内存配置的1/2。
-
在同样的集群规模下, M1 可以完成3倍的全内存配置的数据量, 可以大幅地减少集群规模。
-
提供超大内存给JAVA JVM , 显著增加大数据量内存计算的稳定性, 减少SPARK 内存计算SHUFFLE/SPILL和磁盘网络交互产生的损耗。
-
全物理内存配置的机器不能跑过512GB 的数据, 跑340GB 数据极不稳定(10:1成功率), 用M1加速后都是一次通过。
-
SPARK SQL : Memory1 可以显著提升大数据量的效率和集群规模。 在12个节点的(每节点384GB 内存)SPARK SQL集群运行一个100K 的SPARK SQL PARQUET 的文件, 和3个节点的(2TB M1) 对比, 结果是M1 可以减少24% 的JOB COMPLETION 时间, 成本节省超过一半, 集群节点数节省75%。
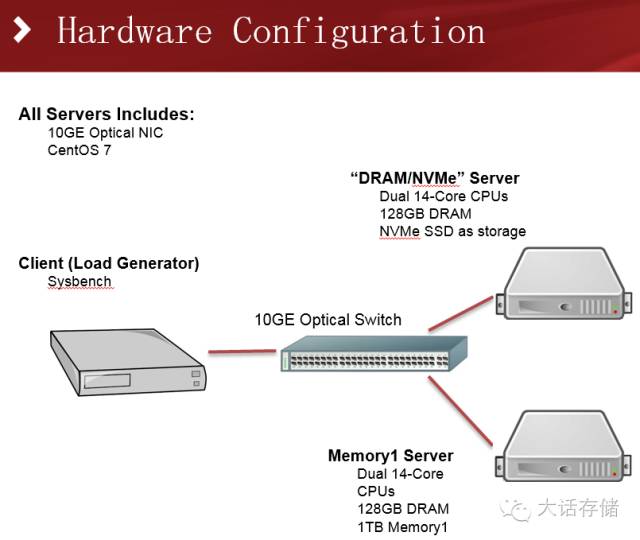
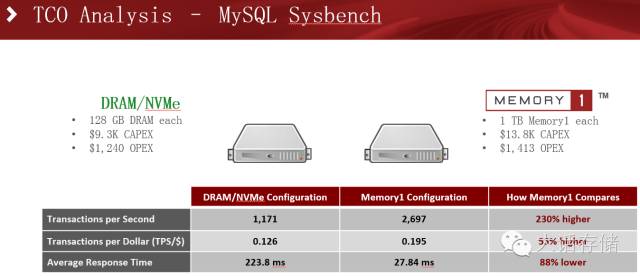
再来看一下更为广泛的场景,MySQL数据库场景下的对比测试。传统配置使用双路服务器,128GB内存,800GB的NVMe SSD;M1配置则采用128GB内存+1TB的M1。
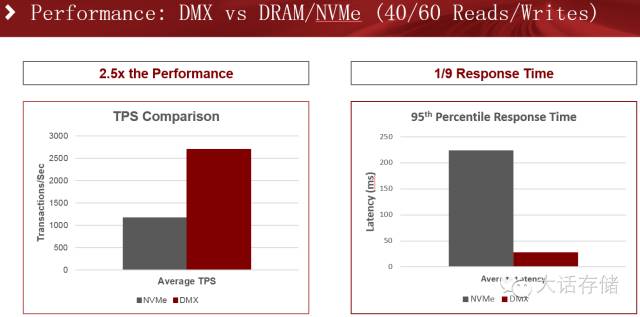
在读写比例6:4的场景下,吞吐量提升近2倍,同时响应时间下降了近四分之一。
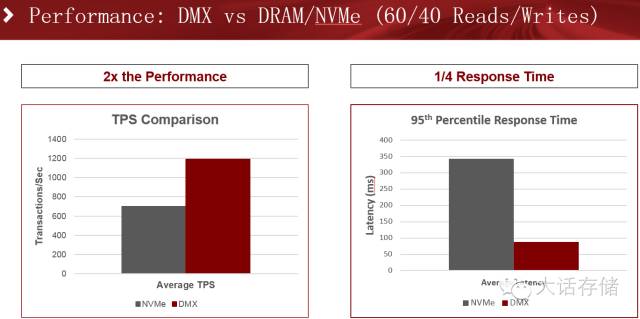
而在读写比例倒置,4:6的场景下,吞吐量和响应时间又进一步提升,尤其是响应时间,是传统配置的九分之一。冬瓜哥分析,对于内存写入场景,相比读场景而言,会导致更多比例的换页操作,因为dirty页面是不能被简单invalidate的,如果有进程想挤占这部分空间,系统必须换页,如果有进程需要读取的数据之前被换出,那么也得换入。读多写少的场景一般命中率较高,换页不太明显。
最好看一下性价比:
可以看到,M1的确能够提供很高的性价比,非常适合于对内存敏感而且大规模部署的环境下,比如大数据分析、互联网在线系统、HPC等场景。冬瓜哥认为,M1想要取胜,关键取决于Tiering的算法和实时性、智能性,能够在多数场景下都拥有很高的性价比。只要Diablo持续针对市场上的主流业务场景做适配优化算法,最后形成固定的Profile,整个生态将会更加成熟。
另外,我们也可以看到,新介质层出不穷,比如3dxpoint,PCM等等,有不少人认为,这些新介质普及之后,M1的生存空间就会被压缩。冬瓜哥却不这么认为。在上一篇文章中,大家可以看到M1的本质其实是一种RAM分层,Tiering。只要内存还有不同的Tier,也就是不同的介质、高落差的价格,那么M1就依然有生存空间,比如,3dxpoint即便出来了,其性能依然是不如SDRAM的,那些习惯了SDRAM的应用,不可能短期内迁移到xpoint上。3dxpoint更多是用在非易失性场景下,而不是可以接受易失性的场景,比如某些HPC场景单节点配6TB内存,根本不要求非易失。而且,xpoint可以被M1所用,将板上的NAND换成xpoint不就好了么?呵。
冬瓜哥在此也期待能够有更多类似M1的奇特同时又能解决实际问题的产品出现。创新无止境!

这篇关于大菠萝M1内存条应用场景和性价比分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






