本文主要是介绍拉链法解决哈希冲突,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.基本思想:
相同散列地址的记录链成一单链表,m个散列地址就设m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构.
例如:一组关键字为{19,14,23,1,68,20,84,27,55,11,10,79},散列函数为:Hash(key)=key%13,
就会发现有些元素是同义词,比如14%131,1%131,27%13==1,14,1,27是同义词
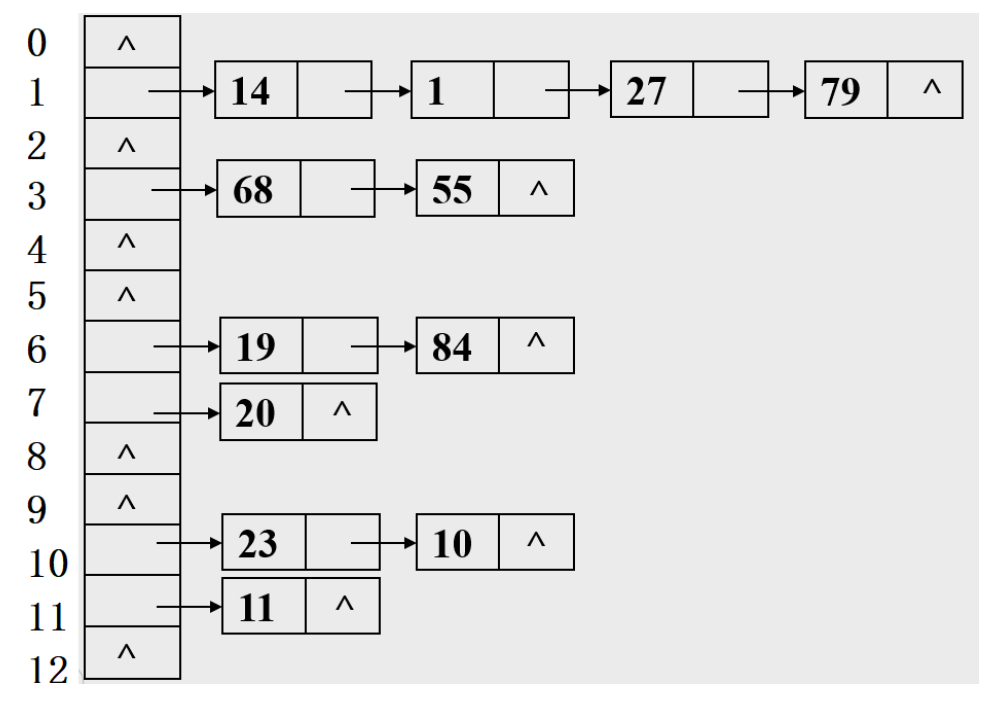
上图有一个缺点,我们最好能用头插法建立哈希表,头插法速度快,时间复杂度O(1)
最多有m个单链表,编号为0-m-1,用一个数组将m个单链表的表头指针存起来.
那么接下来我们就要依据我们的散列函数来建立我们的哈希表,那么我们开始写代码,主要是先设计结构,然后建立哈希表和查找哈希表.
2.代码实现
//链地址法:
{return key % m;
}//在哈希表中查找key,找到返回节点地址,失败返回NULL
Node* Search(const HashTable ht, int key)
{int hi = H(key);//计算key的哈希值for (Node* p = ht[hi].next; p != NULL; p = p->next){if (p->data.key == key){return p;}}return NULL;
}//将key插入到哈希表ht中,成功返回true,失败返回false
bool Insert(HashTable ht, int key)
{int hi = H(key);if (Search(ht, key) != NULL)//key已经存在{return false;}//插入keyNode* p = (Node*)malloc(sizeof(Node));//创建新节点assert(p != NULL);p->data.key = key;//头插p->next = ht[hi].next;ht[hi].next = p;return true;
}//从头到尾输出ht的所有值
void Show(HashTable ht)
{for (int i = 0; i < m; i++){printf("哈希值为%d的有:", i);for (Node* p = ht[i].next; p != NULL; p = p->next)//遍历当前哈希值的链表{printf("%d ", p->data.key);}printf("\n");}
}int main()
{HashTable ht;InitHashTable(ht);int arr[16] = { 3,5,7,1,2,9,28,25,6,11,10,15,17,23,34,19 };for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)//利用arr构造哈希表ht{Insert(ht, arr[i]);}Show(ht);Node* p;for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)//查找所有的arr{p = Search(ht, arr[i]);p == NULL ? printf("%d没有找到\n", arr[i]) : printf("%d找到了\n", arr[i]);}printf("\n");p = Search(ht, 100);p == NULL ? printf("%d没有找到\n", 100) : printf("%d找到了\n", 100);return 0;
}这篇关于拉链法解决哈希冲突的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






