本文主要是介绍redis zset详解:排行榜绝佳选择,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们发布了一款新的app,其中包含一个搜索功能。在搜索时,会给用户展示四个热门搜索词汇。我们利用 Redis 的有序集合(zset)实现了这一功能。由于应用程序刚刚上线并且尚未大力推广,所以热门搜索词汇显示的是我们随手测试词汇,如测试、test、111等。这会给人一种不够专业的印象。为了提升产品形象,我们计划通过后台删除这些测试的词汇,使热门搜索词汇更加贴近实际使用情况。今天,我将与大家分享在 Redis 命令行中操作有序集合(zset)的命令,以及我们实现热门搜索词汇功能的思路。

Redis ZSET 详解
Redis 中的 ZSET(有序集合)是一种有序的数据结构,它类似于 SET(集合),但每个成员都关联着一个分数(score),通过分数来进行排序。这使得 ZSET 既可以像 SET 一样快速查找成员,又可以按照分数从小到大或从大到小进行排序。
ZSET 的特点包括:
- 有序性:成员按照分数的顺序排列,可以进行范围查询和排名操作。
- 唯一性:每个成员都是唯一的,但不同成员可以有相同的分数。
- 快速查找:和 SET 类似,ZSET 也可以在 O(1) 的时间复杂度内查找单个成员。
- 分数(score)更新:可以对成员的分数进行增加或减少操作,同时保持排序。
ZSET 的底层实现会根据实际的情况选择ziplist(压缩列表)/listpack(紧凑列表)(redis7.0已经将 listpack 完整替代 ziplis) 或者skiplist(跳跃表),Redis 会根据实际情况动态地在这两种底层结构之间切换,使得其在内存和性能之间平衡。这是由两个配置参数:zset-max-ziplist-entries 和 zset-max-ziplist-value控制的,其默认值为128和64。当 Zset 存储的元素数量超过zset-max-ziplist-entries的值或者最长元素的长度超过 zset-max-ziplist-value的值的时候Redis 会将底层结构从压缩列表/紧凑列表转换为跳跃表。压缩列表/紧凑列表占用的内存比较少,但是修改数据时可能会对整个列表进行重写,性能较低; 跳跃表的查找和修改数据的性能较高,但是占用的内存也较多。
我们在redis 命令行中可以通过以下命令查看 zset的配置参数:
config get zset*

Redis ZSET 使用场景
- 排行榜
Redis 的zset是设计实时排行的绝佳选择,我们可以使用它来完成各种排行榜、热门词汇等场景的实现。我们app的热搜词汇也是通过zset实现的,本文中也将介绍热搜词汇的实现方式。
- 延时队列
我们可以将时间戳设置为zset的score,延时处理的任务作为元素,定期或者循环扫描zset来处理到达时间的任务。
- 滑动窗口限流
我们可以将接口地址设置为zset的key,时间戳设置为zset的score,使用uuid作为元素,那么我们可以通过zset获取到 score固定窗口范围的时间内的请求数来达到限流的目的。
REDISSON 操作ZSET数据
代码如下:
package cn.xj.xjdoc.redis.zset;import jakarta.annotation.Resource;
import org.redisson.api.RScoredSortedSet;
import org.redisson.api.RedissonClient;
import org.redisson.client.protocol.ScoredEntry;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;import java.util.Collection;@Service
public class ZSETService {private static final Logger log = LoggerFactory.getLogger(ZSETService.class);@Resourceprivate RedissonClient redissonClient;public void operation(){String zsetKey = "xjzset";RScoredSortedSet<String> zset = redissonClient.getScoredSortedSet(zsetKey);//添加元素zset.add(1.0, "修己xj1");zset.add(2.0, "修己xj2");zset.add(3.0, "修己xj3");zset.add(4.0, "修己xj4");// 获取ZSET中指定成员的分数Double score = zset.getScore("修己xj2");log.info("1、获取ZSET中指定成员的分数:{}",score);//获取ZSET中指定成员的排名(分数从小到大排序)Integer rank = zset.rank("修己xj3");log.info("2、获取ZSET中指定成员的排名(分数从小到大排序):{}",rank);//获取ZSET中指定成员的排名(分数从大到小排序)Integer reverseRank = zset.revRank("修己xj4");log.info("3、获取ZSET中指定成员的排名(分数从大到小排序):{}",reverseRank);// 获取ZSET中指定排名范围内的成员(分数从小到大排序)Collection<String> membersInRange = zset.valueRange(0, 1);membersInRange.forEach(o->log.info("4、获取ZSET中指定排名范围内的成员(分数从小到大排序):{}",o));// 获取ZSET中指定排名范围内的成员(分数从大到小排序)Collection<String> membersInRangeRever = zset.valueRangeReversed(0, 1);membersInRangeRever.forEach(o->log.info("5、获取ZSET中指定排名范围内的成员(分数从大到小排序):{}",o));//获取ZSET中指定分数范围内的成员(分数从小到大排序)Collection<String> membersInScoreRange = zset.valueRange(2.0, true, 3.0, true);membersInScoreRange.forEach(o->log.info("6、获取ZSET中指定分数范围内的成员(分数从小到大排序):{}",o));//获取ZSET中指定分数范围内的成员(分数从大到小排序)Collection<String> membersInScoreRever = zset.valueRangeReversed(2.0, true, 3.0, true);membersInScoreRever.forEach(o->log.info("7、获取ZSET中指定分数范围内的成员(分数从大到小排序):{}",o));//获取ZSET中指定排名范围内的成员及其分数Collection<ScoredEntry<String>> membersWithScoresInRange = zset.entryRange(0, 1);membersWithScoresInRange.forEach(o->log.info("8、获取ZSET中指定排名范围内的成员及其分数,成员:{},分数",o.getValue(),o.getScore()));//获取ZSET中指定分数范围内的成员及其分数Collection<ScoredEntry<String>> membersWithScoresInScoreRange = zset.entryRange(3.0, true, 4.0, true);membersWithScoresInScoreRange.forEach(o->log.info("9、获取ZSET中指定分数范围内的成员及其分数,成员:{},分数",o.getValue(),o.getScore()));//Double newScore = zset.addScore("修己xj4", 1);log.info("10、增加1之后指定成员的分数:{}",newScore);//删除ZSET 中的指定成员Boolean removedFlag = zset.remove("修己xj3");log.info("11、删除ZSET 中的指定成员:{}",removedFlag);//删除指定排名范围内的成员Integer removedByRangeCount = zset.removeRangeByRank(0, 1);log.info("12、删除指定排名范围内的成员数量:{}",removedByRangeCount);//删除指定分数范围内的成员Integer removedByScoreCount = zset.removeRangeByScore(3.0, true, 4.0, true);log.info("13、删除指定分数范围内的成员数量:{}",removedByScoreCount);}}执行结果如下:
1、获取ZSET中指定成员的分数:2.0
2、获取ZSET中指定成员的排名(分数从小到大排序):2
3、获取ZSET中指定成员的排名(分数从大到小排序):0
4、获取ZSET中指定排名范围内的成员(分数从小到大排序):修己xj1
4、获取ZSET中指定排名范围内的成员(分数从小到大排序):修己xj2
5、获取ZSET中指定排名范围内的成员(分数从大到小排序):修己xj4
5、获取ZSET中指定排名范围内的成员(分数从大到小排序):修己xj3
6、获取ZSET中指定分数范围内的成员(分数从小到大排序):修己xj2
6、获取ZSET中指定分数范围内的成员(分数从小到大排序):修己xj3
7、获取ZSET中指定分数范围内的成员(分数从大到小排序):修己xj3
7、获取ZSET中指定分数范围内的成员(分数从大到小排序):修己xj2
8、获取ZSET中指定排名范围内的成员及其分数,成员:修己xj1,分数
8、获取ZSET中指定排名范围内的成员及其分数,成员:修己xj2,分数
9、获取ZSET中指定分数范围内的成员及其分数,成员:修己xj3,分数
9、获取ZSET中指定分数范围内的成员及其分数,成员:修己xj4,分数
10、增加1之后指定成员的分数:5.0
11、删除ZSET 中的指定成员:true
12、删除指定排名范围内的成员数量:2
13、删除指定分数范围内的成员数量:0
命令行操作ZSET数据
- zadd 添加成员
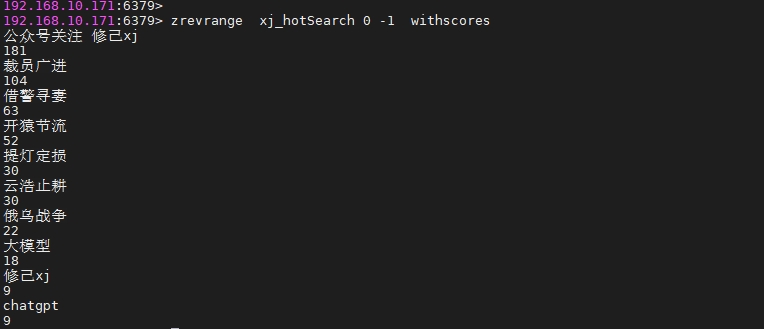
zadd xjzset 1 "修己xj1" 2 "修己xj2" 3 "修己xj3" 4 "修己xj4"
- zscore 获取指定成员的分数
zscore xjzset '修己xj2'
- zrank 获取指定成员的排名(分数从小到大排序)
zrank xjzset 修己xj3
- zrevrank 获取指定成员的排名(分数从大到小排序)
zrevrank xjzset 修己xj3
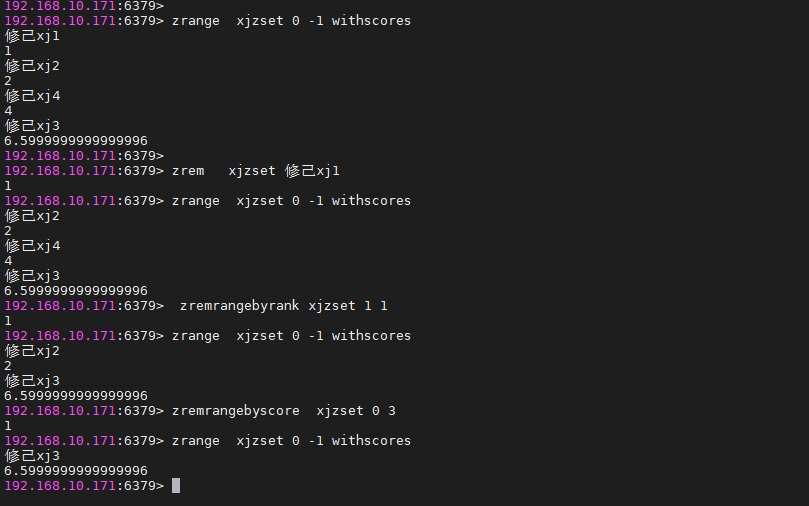
- zrange/zrevrange 获取ZSET中指定排名范围内的成员 zrange:分数从小到大排序,我们加了一些测试数据,如下
zrevrange:分数从大到小排序
zrange key start stop [withscores]zrevrange key start stop [withscores]
其中,key是zset的键名,start是起始索引,stop结束索引,withscores表示是否同时返回分数。可以使用负数索引表示从末尾开始,比如-1表示最后一个元素。zrange key 0 -1 则会显示出所有元素
zrange xjzset 1 2 withscores
- zrangebyscore/zrevrangebyscore 获取ZSET中指定分数score范围内的成员 zrangebyscore:分数从小到大排序,zrevrangebyscore:分数从大到小排序
zrangebyscore key min max [withscores]zrevrangebyscore key max min [withscores]
其中,key是zset的键名,min 和 max 表示score的范围,范围为闭区间,withscores表示是否同时返回分数。
zrangebyscore xjzset 2.5 3.5 withscores
- zincrby 将指定成员的分数增加指定的值
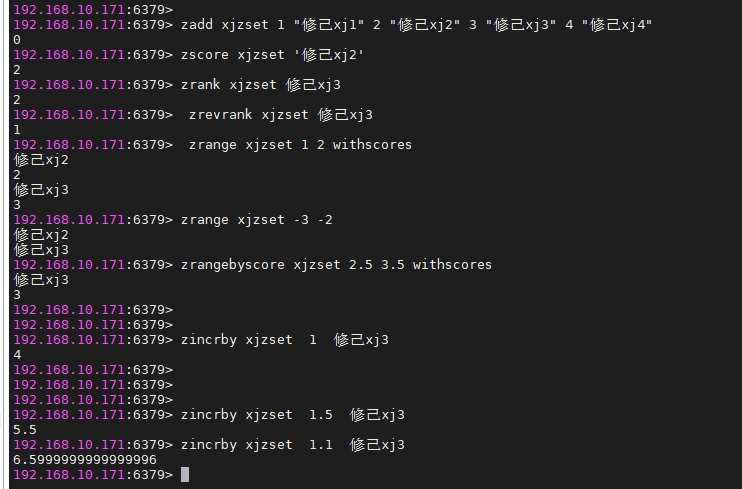
zincrby xjzset 1 修己xj3
注: 进行double的值的运算时可能会丢失精度,如果对score进行运算时尽可能使用整数运算。
- zcard 返回zset中成员的数量
zcard xjzset
- zcount 获取指定范围分数内的成员的数量
zcount key min max
其中,key是zset的键名,min 和 max 表示score的范围,范围为闭区间。
zcount xjzset 0 2
- zrem 删除指定成员
zrem xjzset
- zremrangebyrank 删除指定排名范围内的成员
zremrangebyrank key start stop
其中,key是zset的键名,start是起始索引,stop结束索引。
zremrangebyrank xjzset 1 1
- zremrangebyscore 删除指定分数范围内的成员
zremrangebyscore key min max
其中,key是zset的键名,min 和 max 表示score的范围,范围为闭区间。
zremrangebyscore xjzset 0 3
热搜词汇功能实现
我们设计思路是 将每个搜索词作为有序集合的成员,而搜索次数作为成员的分数,每次搜索的时候对这个搜索词的分数加1,这样可以根据搜索次数对热搜词进行排序。
- 搜索接口
public String keySearch(String keyStr){String hotSearchKey = "xj_hotSearch";RScoredSortedSet<String> hotSearchZSet = redissonClient.getScoredSortedSet(hotSearchKey);//更新zset中当前搜索词的搜索次数hotSearchZSet.addScore(keyStr,1);//搜索逻辑//doSearch(keyStr);return keyStr;
}- 热搜词汇查询接口
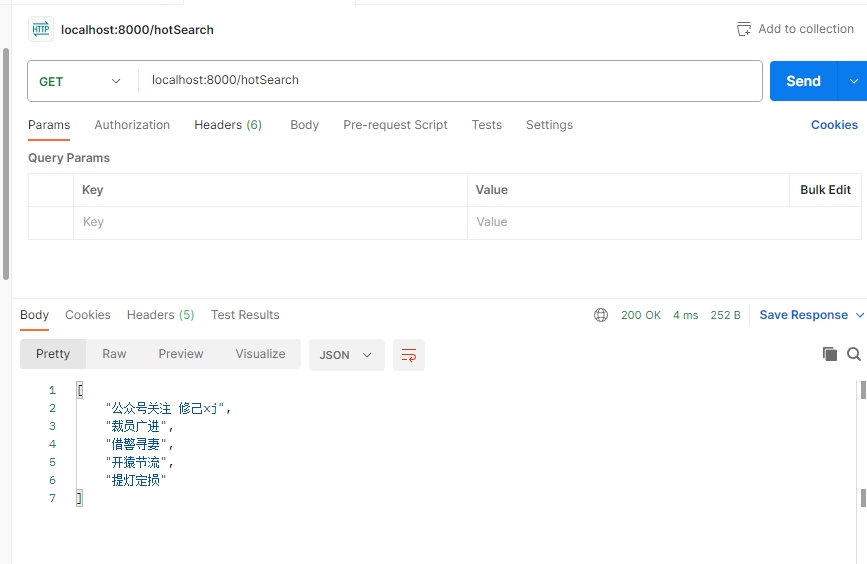
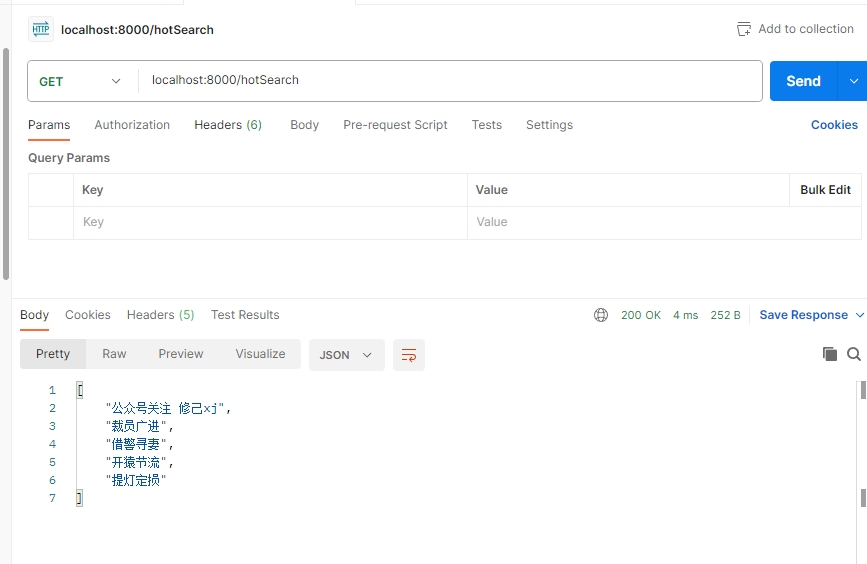
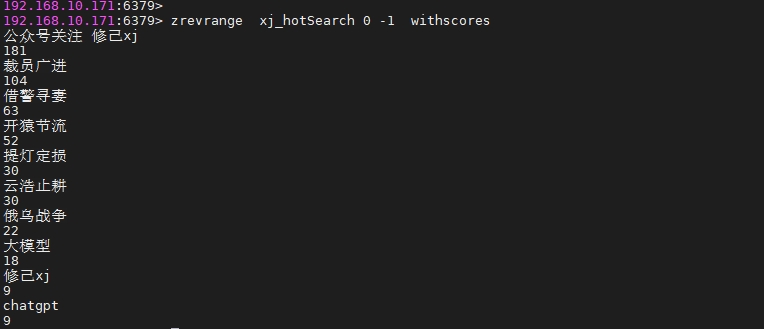
public Collection<String> hotSearch(){String hotSearchKey = "xj_hotSearch";RScoredSortedSet<String> hotSearchZSet = redissonClient.getScoredSortedSet(hotSearchKey);//获取zset中点击次数排名前5的数据Collection<String> hotList= hotSearchZSet.valueRangeReversed(0,4);return hotList;
}
我们加了一些测试数据,如下
总结
通过本文的介绍,你学会了如何利用Spring Boot和Redis的ZSET数据结构实现热门搜索功能,并深入了解了热搜词汇的实现细节。通过合理的设计和优化,可以为用户提供更好的搜索体验,同时也提升了应用程序的性能和可扩展性。
这篇关于redis zset详解:排行榜绝佳选择的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!