本文主要是介绍TCP/IP详解 卷1:协议 学习笔记 第八章 Traceroute程序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
尽管不能保证从源端发往目的端的两份连续的IP数据报有相同路由,但大多情况下是这样的。Traceroute可让我们看到IP数据报从一台主机传到另一台主机所经过的路由,还可让我们使用IP源路由选项。
有了IP首部的RR选项,但还是使用Traceroute的理由:
1.不是所有路由器都支持RR选项。
2.RR一般是单向的选项,发送端设置后,接收端必须从收到的IP首部中提取出信息,再全部返回给发送端。这样使记录下来的IP地址翻了一番。而Traceroute程序只需在目的端运行一个UDP模块,不需要特殊的服务器应用程序。
3.IP首部选项字段空间有限。
Traceroute使用ICMP报文和IP首部中的TTL字段。每个处理数据报的路由器都将TTL减去1或减去数据报在路由器中停留的秒数,而大多路由器转发数据报的时延都小于1s,因此TTL最终成为一个跳站计数器。
TTL字段的目的是防止数据报在选路时无休止地在网络中流动。
当路由器收到一份TTL字段是0(通常不应收到)或1的数据报时,路由器不转发该数据报,而是将其丢弃,并给源机发送一份ICMP超时信息,这份ICMP信息的IP报文的信源地址是路由器的IP地址。
Traceroute工作过程:Traceroute先发送一份TTL字段为1的IP数据报给目的主机,处理这份数据报的第一个路由器将TTL值减1,然后丢弃该数据报,并发回一份超时ICMP报文,这样就得到了该路径中第一个路由器的地址。然后Traceroute发送一份TTL值为2的数据报,这样就得到了第二个路由器的地址。继续这个过程,直至该数据报到达目的主机,目的主机接收到TTL为1的IP数据报也不会丢弃数据报或产生超时ICMP报文,那怎么判断是否已经到达目的主机了呢?Traceroute发送一份UDP数据报给目的主机,但它选择一个不可能的值作为UDP端口号(大于30000),目的主机任何一个应用程序都不可能使用该端口,目的主机会产生一份端口不可达错误的ICMP报文,这样Traceroute只需区分接收到的是ICMP超时还是端口不可达。
Traceroute一般要求root权限。
在svr4上运行Traceroute,目的地址是slip,中间只需经过bsdi路由器:

输出的无编号行给出了traceroute的最大TTL字段为30,40字节的数据报包含20字节IP首部、8字节UDP首部、12字节用户数据(用户数据包含每发一个数据报就+1的序列号,TTL和发送数据报的时间)。
后面输出行以TTL值为开端,对于每个TTL值,发送三份数据报,每接收到一份ICMP报文,就计算并打印出往返时间,如果5s内未收到一份的应答,则此份应答的rtt处会打印一个星号,并发送下一份数据报。
往返时间指运行traceroute程序的主机到目标路由器的总往返时间,用TTL字段为N+1打印出来的时间减去TTL字段为N的时间就是第N步路由到第N+1步路由的中间一段路径的往返时间。

从上图得知,第一次往返时间是20ms而非10ms的原因是发送了arp请求。traceroute程序第一次选择的目的主机的UDP端口号是33435,且每发送一个数据报就加1,可用选项改变开始端口号。UDP数据报包含12个字节的用户数据。后面打印出了TTL字段为1的IP数据报注释,当TTL为0或1时,打印这条信息,而其他一些应用可能发出警告,表示数据报可能无法到达最终目的主机。上图中的发送端的端口为42804,有些大,这是由于traceroute程序将其发送的UDP数据报的源端口号设置为UNIX进程号与32768之间的逻辑或值,同一台主机上多次运行traceroute时,进程通过ICMP返回的UDP首部中的源端口号来识别并只处理给自己发送的应答报文。
我们不可能看到TTL为0的数据报,除非发出它的路由器已经崩溃。

在TTL值为0时产生的ICMP超时报文的code字段为0,而在主机组装分片时发生的超时,会发送组装报文超时的ICMP报文,此时的code字段为1。
不能保证ICMP报文的路由与traceroute程序发送的UDP数据报采用同一路由,如果路由不同,则rtt时间失效。
从A到B的traceroute和从B到A的traceroute程序的结果可能不同。
traceroute也同时打印出与IP相关的主机名,主机名可能发生变化。

在上图中,两路由器以SLIP链路相连,在左边LAN的主机上运行traceroute会发现路由器地址为if1和if3,而在右边主机运行traceroute时,会发现地址为if4和if2。
if2和if3有同样的网络号,而if1和if4网络号不同。
在广域网时,traceroute获得的是IP地址而非域名,这样可读性不高,因此,他会做一个反向域名查看来获得域名。
广域网输出:

TTL字段为6的第2个数据报的RTT几乎是其他两个RTT的两倍,在发送主机和这个路由器之间发生了使该数据报速度变慢的事件,但我们无法区分是发出的数据报还是返回的ICMP差错报文被拦截。
IP源站选路选项是由发送者指定路由,采用两种形式:
1.严格的源路由选择。发送端指明IP数据报所必须采用的确切路由,如果一个路由器发现源路由所指定的下一个路由器不在其直接连接的网络上,则它返回一个源站路由失败的ICMP差错报文。
2.宽松的源站选路。发送端指明了一个数据报经过的IP地址清单,但是数据报在清单上指明的任意两个地址间可通过其他路由器。
Traceroute提供一个查看源站选路的方法,可在选项中指明源站路由,然后检查其运行情况。
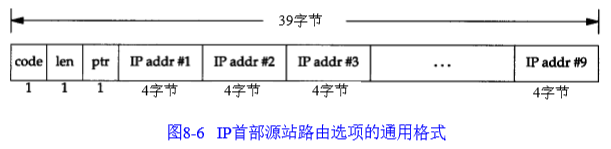
我们在发送IP数据报前要填充清单中各项。宽松的源站选路的code字段是0x83,严格的源站选路的code字段是0x89。
宽松的源站路由选路和严格的源站路由选路简写分别为LSRR和SSRR。源站路由选项又称为源站及记录路由选项,因为在数据报沿路发送过程对IP地址清单进行了更新,运行过程为:
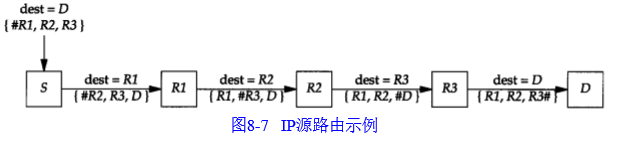
上图中,#代表指针ptr字段,其值分别为4、8、12、16等;长度len字段恒为15;可见,每一跳IP数据报中的目的地址都发生改变。
当应用收到由信源指定路由的数据时,在发送应答时,应读出接收到的路由值,并提供反向路由。
使用traceroute的-g选项,可为宽松的源站选路指明一些中间路由器,此选项最多可以指定8个中间路由器(8个而非9个的原因是,使用的编程接口要求最后的表目是目的主机):

指定中间路由后,有16跳,而默认路径有13跳。上例中,命令行使用的是IP地址而非域名,这是因为此处无法做到将域名解析为IP地址(前向解析),在DNS中,前向映射和反向映射是两个独立文件,并非所有管理者都同时拥有这两个文件,因此,可能出现在一个方向上正常工作而另一方向失败的情况。
上例输出中TTL为8时,第一个rtt打印的是星号,这表明5秒内没收到本次探查的应答信号。
-G选项可进行严格的源站选路:

TTL为3的输出行中,rtt后面是!s,表明接收到了ICMP源站路由失败的差错报文,*表明未收到这次探查的应答信号。ttl为2和3的结果都来自路由器gateway。
tcpdump命令使用-v选项显示出上例的源站路由信息:

上图可见,sun发送的每一个UDP数据报的目的地址都是netb。
在sun上查看到目的主机的路由和回来的路由:

上图中,发送路径(ttl为1~11)与返回路径(ttl为11~21)不同,选路是不对称的。
traceroute将路由器的进入接口作为其标示,因此上图输出中ttl为2和19的结果中IP是不同的,但路由器是相同的。
如果路由器收到一个ttl为0的IP数据报,之后错误地减1,ttl会变为255(ttl字段为8位),可能会发生这种情况。
traceroute在UDP数据报的数据部分存储了12字节,其中包含数据报的发送时间,而ICMP出错返回报文只返回了UDP首部的8字节,没有返回存储的时间值。traceroute保存了它发送分组的时间,收到ICMP应答时,取出当时时间,然后相减即可。而ping在ICMP回显请求中存储了时间,这样即使分组返回时是失序的,ping也能打印出正确的rtt。
在traceroute中,如果一个出错路由器接收到一个ttl为1的数据报但仍减1后传给下一跳路由器,这样下一跳路由器会丢弃此报文,并发送ICMP超时差错报文,此时,会显示连续两个来自同一路由器的差错报文。
在traceroute中,如果出错目的主机发送ICMP端口不可达报文时将ttl值设为进入时的ttl值,则往回传1站就会被丢弃,而没有生成ICMP超时差错报文,这是由于不会为ICMP差错报文生成差错报文。而源端在发送完三个报文后,将ttl加1,继续发送,直到目的主机的ICMP差错报文能回到traceroute的发送端,此时ttl会为1,traceroute会认为它可能是有问题的,因此会打印一个感叹号。
这篇关于TCP/IP详解 卷1:协议 学习笔记 第八章 Traceroute程序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





