本文主要是介绍StarRocks x Paimon 构建极速实时湖仓分析架构实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Paimon 介绍
Apache Paimon 是新一代的湖格式,可以使用 Flink 和 Spark 构建实时 Lakehouse 架构,以进行流式处理和批处理操作。Paimon 创新性地使用 LSM(日志结构合并树)结构,将实时流式更新引入 Lakehouse 架构中。
Paimon 提供以下核心功能:
高效实时更新:高吞吐和低延迟的数据摄入和更新
统一的批处理和流处理:同时支持批量读写和流式读写
丰富的数据湖功能:ACID, Time Travel 和 Schema Evolution 等
StarRocks 介绍
Linux 基金会项目 StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库,遵循 Apache 2.0 开源协议。StarRocks 架构简洁,采用了全面向量化引擎,并配备全新设计的 CBO (Cost Based Optimizer) 优化器,查询速度(尤其是多表关联查询)远超同类产品。
StarRocks 不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据。用户可以通过 StarRocks 提供的 External Catalog,轻松查询存储在 Apache Paimon 数据湖上的数据,无需进行数据迁移。支持的存储系统包括 HDFS、阿里云 OSS、阿里云 OSS-HDFS 等
本文将介绍如何使用 StarRocks 和 Paimon 构建高效的数据湖分析架构,利用 StarRocks 达到极致的 Paimon 查询效率,并给出详细的操作步骤和性能测试数据。
本文主要内容:
-
快 - 使用 StarRocks 直接查询 Paimon 湖格式
-
更快 - 开启 Data cache 查询 Paimon 湖格式
-
超级快 - 构建异步物化视图查询 Paimon 湖格式
PART/ 01 快-使用 StarRocks 直接查询 Paimon 湖格式
StarRocks 支持 Catalog(数据目录)功能,实现在一套系统内同时维护内、外部数据,不需要手动建外表,指定数据源路径,即可轻松访问并查询各类数据湖格式,例如 Hive,Paimon,Iceberg 等。开箱即用,不需要任何数据导入和迁移。
例如:在 StarRocks 里创建一个 filesystem 类型的 Paimon Catalog:
CREATE EXTERNAL CATALOG paimon_fs_catalog
properties
( "type" = "paimon","paimon.catalog.type" = "filesystem","paimon.catalog.warehouse" = "oss://<bucket>/paimon/warehouse"
);
执行 SQL 查询 Paimon 数据湖(以 TPC-H Q1 为例):
selectl_returnflag,l_linestatus,sum(l_quantity) as sum_qty,sum(l_extendedprice) as sum_base_price,sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,avg(l_quantity) as avg_qty,avg(l_extendedprice) as avg_price,avg(l_discount) as avg_disc,count(*) as count_order
frompaimon_fs_catalog.paimon_tpch_flat_orc_100lineitem
wherel_shipdate <= date '1998-12-01' - interval '90' day
group byl_returnflag,l_linestatus
order byl_returnflag,l_linestatus
我们使用相同的硬件资源(配置详情见附录),对比了 StarRocks 和 Trino 分别查询Paimon Append Only 表格式的 TPC-H 100G 数据集,Trino 使用了最新的 Paimon-Trino 版本,已包含了对 ORC 文件读取的优化,测试结果如下:
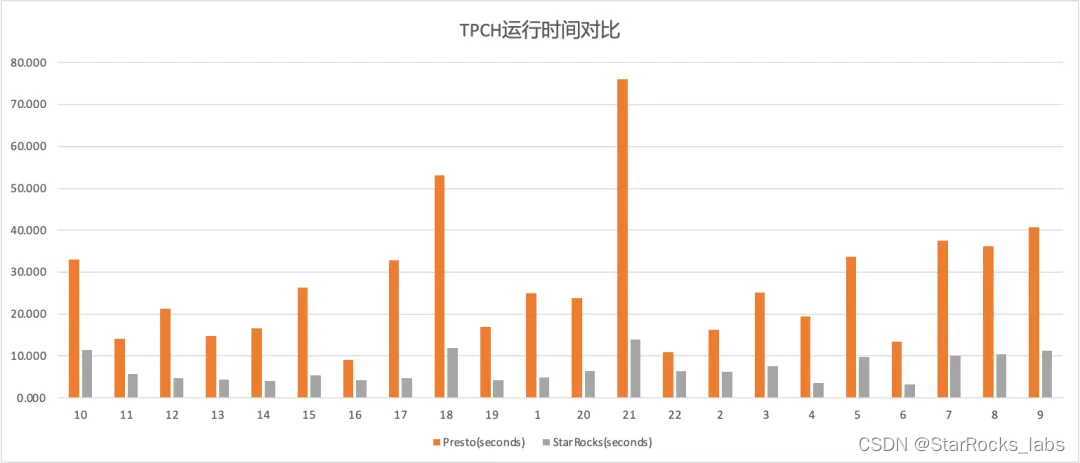
StarRocks 的总耗时为 148.92s,Trino 的总耗时为 640.8s
可以得到,在本测试场景下,StarRocks 的查询效率是 Trino 的 4.3倍。
使用 StarRocks 直接查询 Paimon 数据是实际生产环境中最常见的场景,操作简单,可以满足大部分 Paimon 数据湖分析的需求。
PART/ 02 更快-开启 Data Cache查询 Paimon 湖格式
在数据湖分析场景中,StarRocks 作为 OLAP 查询引擎需要扫描 HDFS 或对象存储上的数据文件。查询实际读取的文件数量越多,I/O 开销也就越大。此外,在即席查询 (ad-hoc) 场景中,如果频繁访问相同数据,还会带来重复的 I/O 开销。
为了进一步提升该场景下的查询性能,StarRocks 2.5 版本开始提供 Data Cache 功能。通过将外部存储系统的原始数据按照一定策略切分成多个 Block 后,缓存至 StarRocks 的本地节点,从而避免重复的远端数据拉取开销,实现热点数据查询分析性能的进一步提升。
例如:开启 Data Cache 的步骤
- BE 增加如下配置并重启:
# 开启data cachedatacache_enable=true# 单个磁盘缓存数据量的上限,本示例20Gdatacache_disk_size=21474836480# 内存缓存数据量的上限,本示例4Gdatacache_mem_size=4294967296# 缓存使用的磁盘路径datacache_disk_path=/mnt/disk1/starrocks/storage/datacache;/mnt/disk2/starrocks/storage/datacache;/mnt/disk3/starrocks/storage/datacache;/mnt/disk4/starrocks/storage/datacache
- MySQL 客户端执行:
SET enable_scan_datacache = true;
我们可以在 Query Profile 里观测当前 Query 的 Cache 命中情况,观测下述指标查看 Data Cache 的命中情况:
-
DataCacheReadBytes:从内存和磁盘中读取的数据量。
-
DataCacheWriteBytes:从外部存储系统加载到内存和磁盘的数据量。
如以下的示例,显示该 Query 在 Data Cache里读取了 10.107 GB 的数据
- DataCache:- DataCacheReadBlockBufferBytes: 920.146 MB- __MAX_OF_DataCacheReadBlockBufferBytes: 14.610 MB- __MIN_OF_DataCacheReadBlockBufferBytes: 1.762 MB- DataCacheReadBlockBufferCounter: 27.923K (27923)- __MAX_OF_DataCacheReadBlockBufferCounter: 440- __MIN_OF_DataCacheReadBlockBufferCounter: 55- DataCacheReadBytes: 10.107 GB- __MAX_OF_DataCacheReadBytes: 163.518 MB- __MIN_OF_DataCacheReadBytes: 20.225 MB- DataCacheReadDiskBytes: 563.468 MB- __MAX_OF_DataCacheReadDiskBytes: 30.965 MB- __MIN_OF_DataCacheReadDiskBytes: 0.000 B- DataCacheReadMemBytes: 9.556 GB- __MAX_OF_DataCacheReadMemBytes: 142.791 MB- __MIN_OF_DataCacheReadMemBytes: 20.225 MB- DataCacheReadCounter: 41.456K (41456)- __MAX_OF_DataCacheReadCounter: 655- __MIN_OF_DataCacheReadCounter: 81- DataCacheReadTimer: 9.157ms- __MAX_OF_DataCacheReadTimer: 48.792ms- __MIN_OF_DataCacheReadTimer: 478.759us- DataCacheSkipReadBytes: 0.000 B- DataCacheSkipReadCounter: 0- DataCacheWriteBytes: 0.000 B- DataCacheWriteCounter: 0- DataCacheWriteFailBytes: 0.000 B- DataCacheWriteFailCounter: 0- DataCacheWriteTimer: 0ns
我们开启 Data Cache 后,再次执行 TPC-H 100G 基准测试,第一次执行总耗时为134.59s,第二次执行总耗时为 110.2s,第三次执行总耗时 113.12s,第一次相对后两次较慢是因为 StarRocks 要从对象存储 OSS 里拉数据,并做本地 Cache,后两次从 Profile 可以看到基本全命中本地 Cache 做运算,执行时间稳定在 110s 左右。
可以得到,在本测试场景下,开启 Cache 之后,查****询性能提升了35.4%左右。
在生产环境中,Data Cache 的性能在不同的 Query Pattern 以及不同的数据量下,查询性能有从百****分之几十到几倍的提升。
PART/ 03 超级快-构建异步物化视图查询 Paimon 湖格式
生产环境环境中的应用程序经常基于多个大表执行复杂查询,通常涉及大量的数据的关联和聚合。处理此类查询通常会大量消耗系统资源和时间,造成极高的查询成本,StarRocks 可以使用异步物化视图解决以上问题。异步物化视图是一种特殊的物理表,其中存储了基于基表特定查询语句的预计算结果。当您对基表执行复杂查询时,StarRocks 可以直接复用预计算结果,避免重复计算,进而提高查询性能。
我们以 TPC-H Q1 的查询 SQL 为例,演示如何创建 Paimon 湖格式的异步物化视图:
CREATE MATERIALIZED VIEW lineitem
DISTRIBUTED BY HASH(l_shipdate)
REFRESH IMMEDIATE MANUAL
AS
selectl_returnflag,l_linestatus,l_shipdate,sum(l_quantity) as sum_qty,sum(l_extendedprice) as sum_base_price,sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,avg(l_quantity) as avg_qty,avg(l_extendedprice) as avg_price,avg(l_discount) as avg_disc,count(*) as count_order
frompaimon_fs_catalog.paimon_tpch_flat_orc_100.lineitem
group byl_returnflag,l_linestatus,l_shipdate
物化视图构建完成后,再次运行 TPC-H Q1 查询,StarRocks 可以自动改写查询SQL,从物化视图里直接读取数据。
在本测试场景下,TPC-H Q1 执行时间从直接查询 Paimon 数据湖的 3.5秒左右缩短到0.04s 左右。
实际生产环境中,物化视图应用在对查询延迟要求非常高的场景,而物化视图的构建方式会极大的影响最终查询耗时,需要用户根据业务需求和历史的查询 SQL 进行总结来选择合适的物化视图构建方式来满足具体的业务需求。
PART/ 04 当前总结
当前 StarRocks x Paimon 的能力主要包括:
-
支持各类存储系统,包括 HDFS 以及对象存储 S3/OSS/OSS-HDFS
-
支持 HMS 以及阿里云 DLF 元数据管理系统
-
支持 Paimon 的 Primary Key 和 Append Only 表类型查询
-
支持 Paimon 系统表的查询,常见例如 Read Optimized 表,snapshots 表等
-
支持 Paimon 表和其他类型数据湖格式的关联查询
-
支持 Paimon 表和 StarRocks 内表的关联查询
-
支持 Data Cache 加速查询
-
支持基于 Paimon 表构建物化视图实现透明加速,查询改写等
对于 Primary Key 表类型,我们对 Read Optimized 系统表做了完善的性能优化,可以与 Append Only 表一样充分利用 Native reader 的能力,得到直接查询 Paimon数据的最佳性能。直接查询 Primary Key 表的情况下,若 Primary Key 表里包含没有做 Compaction 的数据,StarRocks 里会通过 JNI 调用 Java 读取这部分内容,性能会有一定的损耗。即使是这种情况,在我们收到客户反馈里,平均还是会有相对Trino 达到3倍以上的性能提升。
PART/ 05 未来规划
接下来,我们会继续完善 StarRocks x Paimon 的支持能力,包括:
-
使用 Native reader 支持 Primary Key 表的 Deletion vectors,进一步加速查询性能
-
缓存 Paimon 元数据,减少重复 I/O 和降低 Analyze 阶段的延时
-
接入 Paimon 表统计信息,优化复杂 SQL 的执行计划
-
完善 Paimon 异步物化视图查询和改写功能
===
附录:本文性能测试环境说明
阿里云 EMR on ECS 数据湖集群:
-
EMR版本:EMR-5.16.0版本
-
集群配置:1x master, 3x core
-
机型:ecs.g6.4xlarge 16 vCPU 64 GiB
-
Trino版本:427
-
Paimon 版本:0.7
-
Paimon TPC-H 测试表类型:Append only,存储格式为ORC
EMR Serveless StarRocks 集群
StarRocks版本:3.2.4
测试软件配置
-
Trino
-
-Xmx50G
-
query.max-total-memory: 105GB
-
query.max-memory: 105GB
-
query.max-memory-per-node: 35GB
-
StarRocks
-
-Xmx50G
测试数据和步骤
-
性能测试基准:TPCH 100G
-
测试方法:每个 Query 跑3次取平均值,不做预热,不预先收集统计信息,测试数据放在 OSS
更多交流,联系我们:https://wx.focussend.com/weComLink/mobileQrCodeLink/33412/8da64
这篇关于StarRocks x Paimon 构建极速实时湖仓分析架构实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






