本文主要是介绍python项目练习-1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
获取无忧书城的小说内容!
import requests # 导入请求包
from lxml import etree # 导入处理xml数据包url = 'https://www.51shucheng.net/wangluo/douluodalu/21750.html'
book_num = 1 # 文章页数
download_urls = [] # 定义一个空列表,表示我们下载过小说的url!while True:# UA头headers = {'User-Agent=': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'}resp = requests.get(url, headers=headers) # 使用get方式请求数据!resp.encoding = 'utf-8' # 将请求的数据编码为 utf-8的格式e = etree.HTML(resp.text) # 使用etree模块处理数据,并赋值给e对象!data = ''.join(e.xpath('string(//div[@class="neirong"]/p)')) # 使用xpath插件获取我需要的标签内容!title = e.xpath('//h1/text()')[0] # 获取文章的标题if url in download_urls:print(f"跳过重复下载的章节: {title}")else:filename = f'output/斗罗大陆-第{book_num}章.txt'with open(filename, mode='w', encoding='utf-8') as file:file.write(title + "\n" + data)book_num += 1download_urls.append(url) # 将已经下载章节的url添加到列表中!next_url = e.xpath('//div[@class="next"]/a/@href')[0] # 使用xpath插件获取下一章节url在html标签内的位置!if not next_url:breakurl = next_url
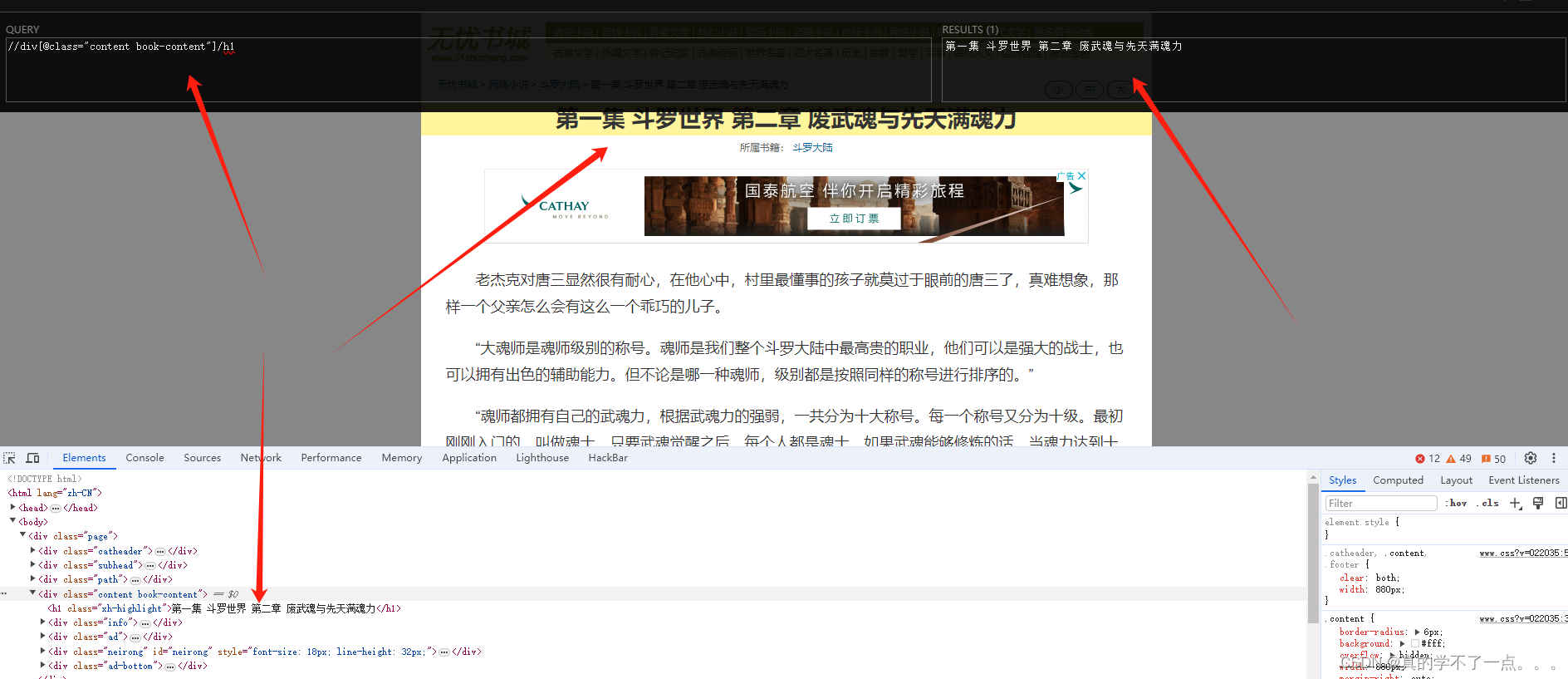
不会用xpath的话,看下边!
比如我要获取每章节的标题在xml数据中的位置,请看如下图~
这篇关于python项目练习-1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





