本文主要是介绍如何安装sbt(sbt在ubuntu上的安装与配置)(有详细安装网站和图解),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
sbt下载官网
选择对应的版本和安装程序
Download | sbt (scala-sbt.org)
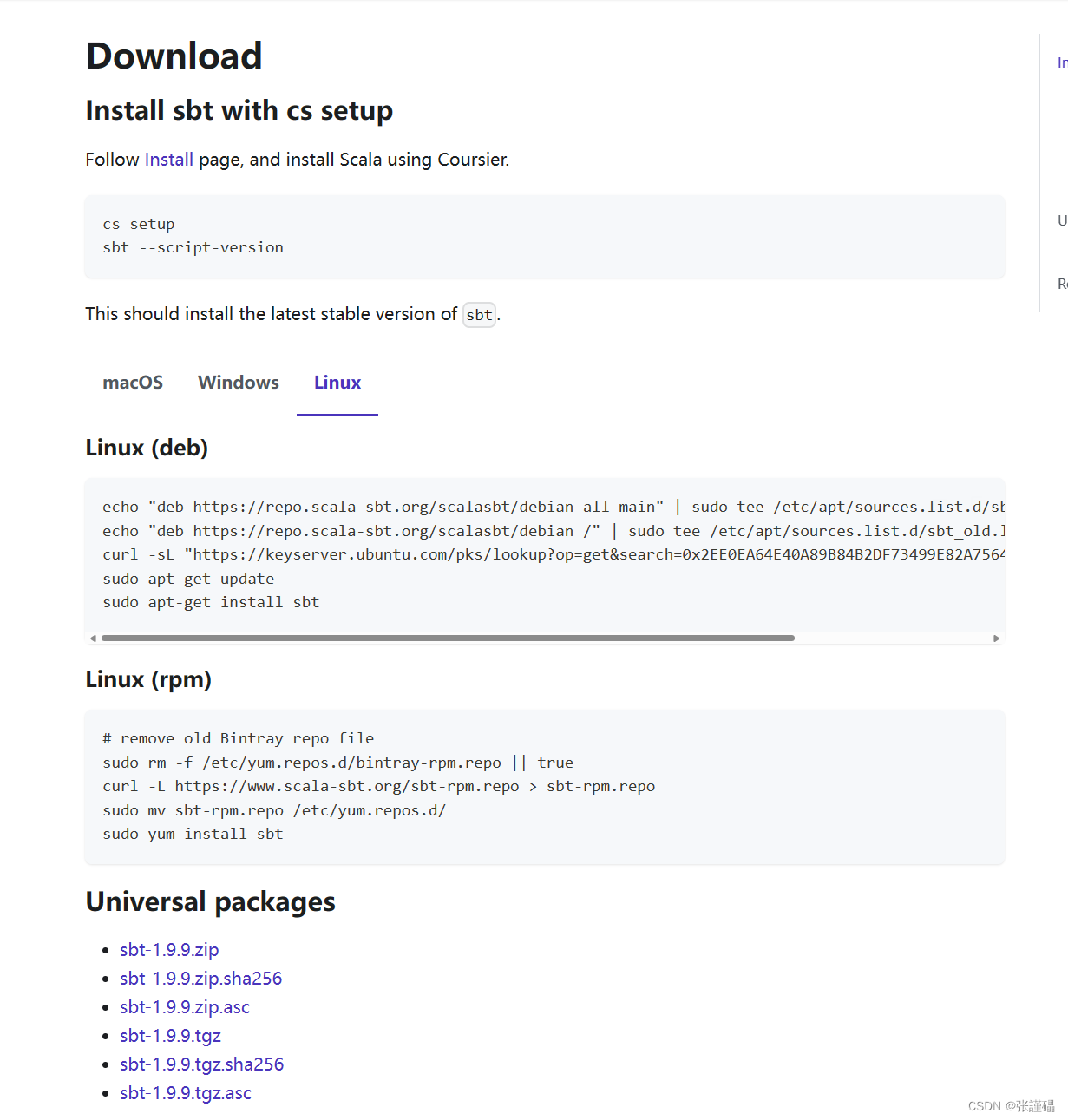
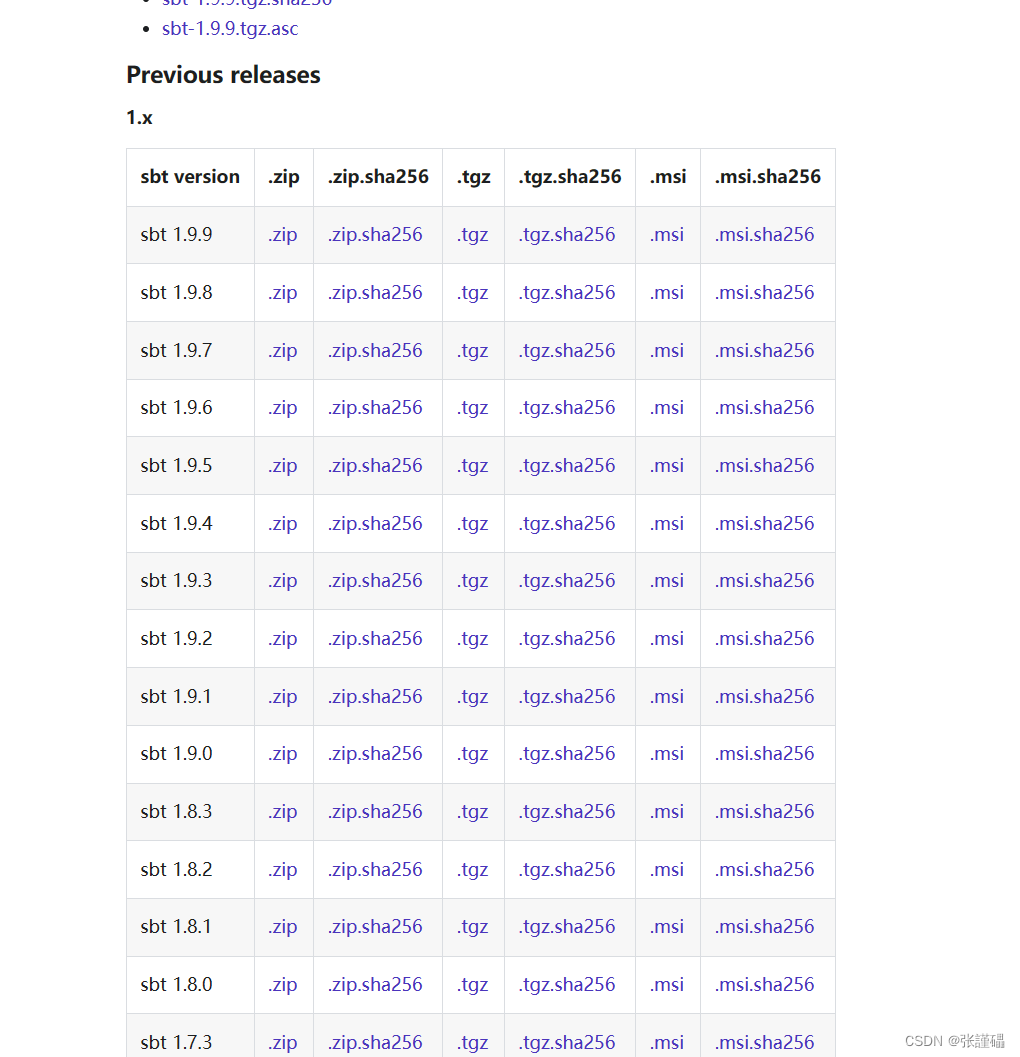
安装
解压
将sbt-1.9.0.tgz上传到xshell,并解压

解压:
tar -zxvf sbt-1.9.0.tgz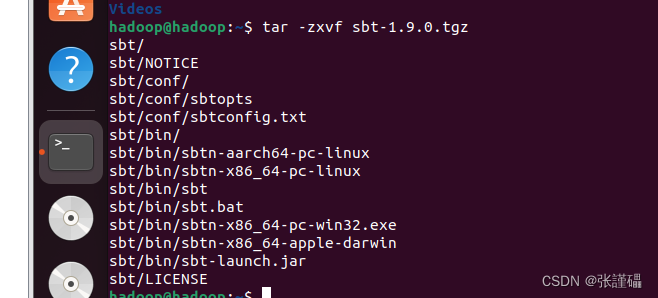
配置
1、在/home/hadoop/sbt中创建sbt脚本
/home/hadoop/sbt 注意要改成自己的地址
cd sbtvim ./sbt 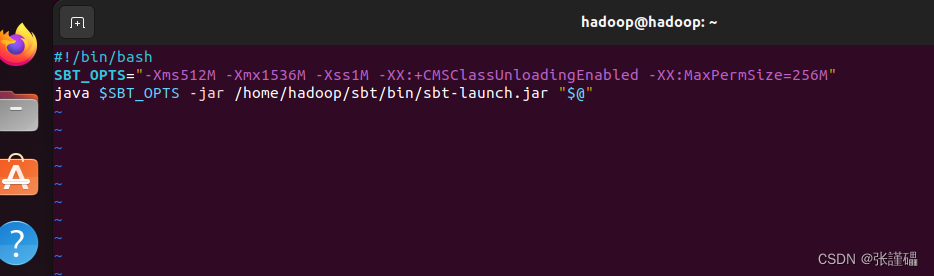
在脚本中添加如下内容:
记住里面的路径,要改成自己的路径
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar /home/hadoop/sbt/bin/sbt-launch.jar "$@"
2、为sbt脚本文件增加可执行权限
一定要在对应的目录下完成
找到对应的文件夹目录
chmod u+x ./sbt
3、运行如下命令,检查sbt是否可用(查看sbt的版本信息)
./sbt sbtVersion 
sbt的运用
一定要注意对应的目录和路径,不能错
1、创建存放代码的目录
mkdir -p sparkapp/src/main/scala/
2、编写代码
vim sparkapp/src/main/scala/test1.scala 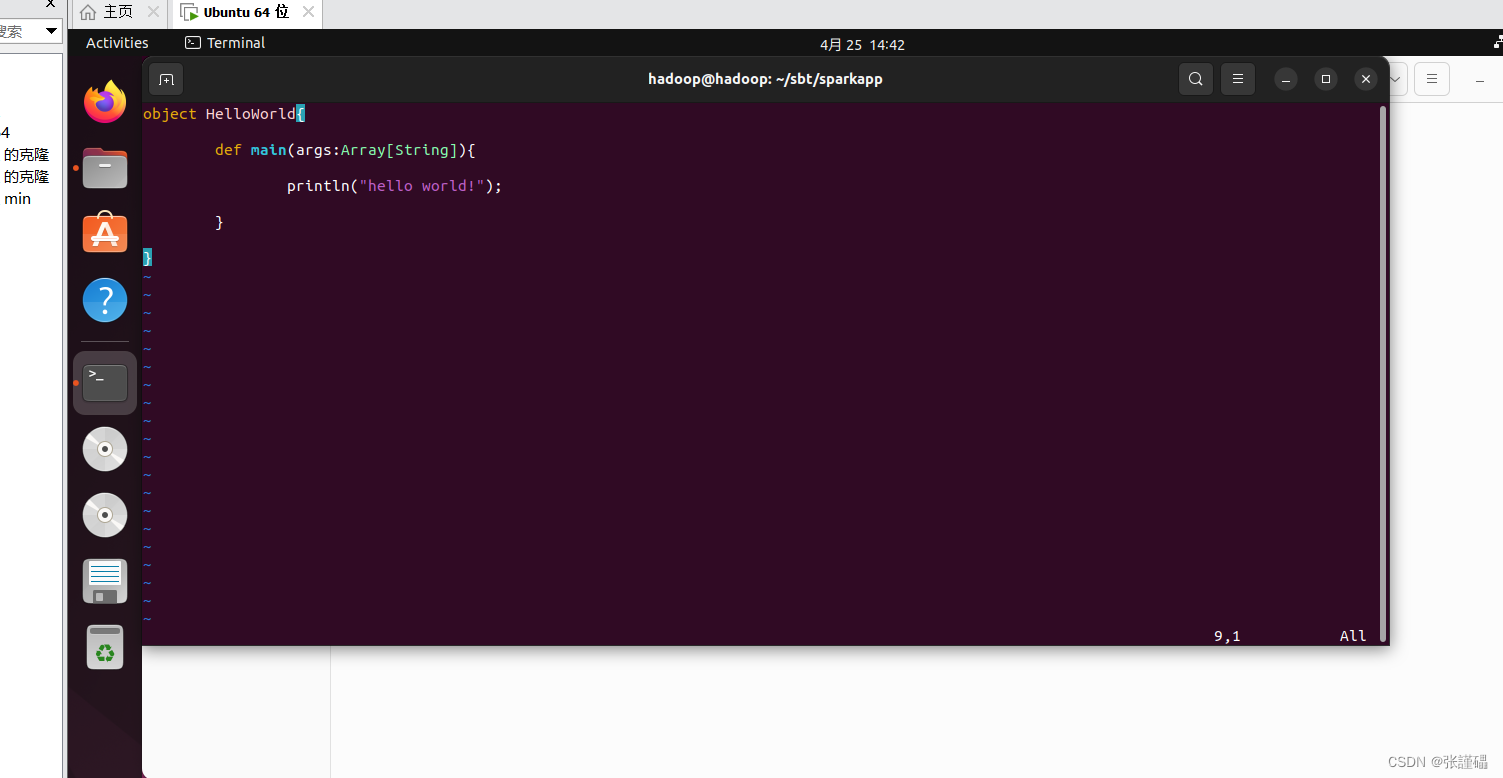
对应目录
在test1.scala文件中增加如下内容
object HelloWorld{def main(args:Array[String]){println("hello world!");}}3、进入sparkapp目录编写sbt程序
cd sparkapp/vim simple.sbt
在simple.sbt中添加如下内容:
name := "Simple Project"
version := "1.9.0"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.1" name := "Simple Project" (项目名称)
version := "1.6.1" (自己的sbt版本号)
scalaVersion := "2.12.10" (自动scala版本号)
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.1.1" (spark的版本号)
//如何要连接mysql的话
libraryDependencies += "mysql" % "mysql-connector-java" % "8.0.26" // 使用适合你MySQL版本的驱动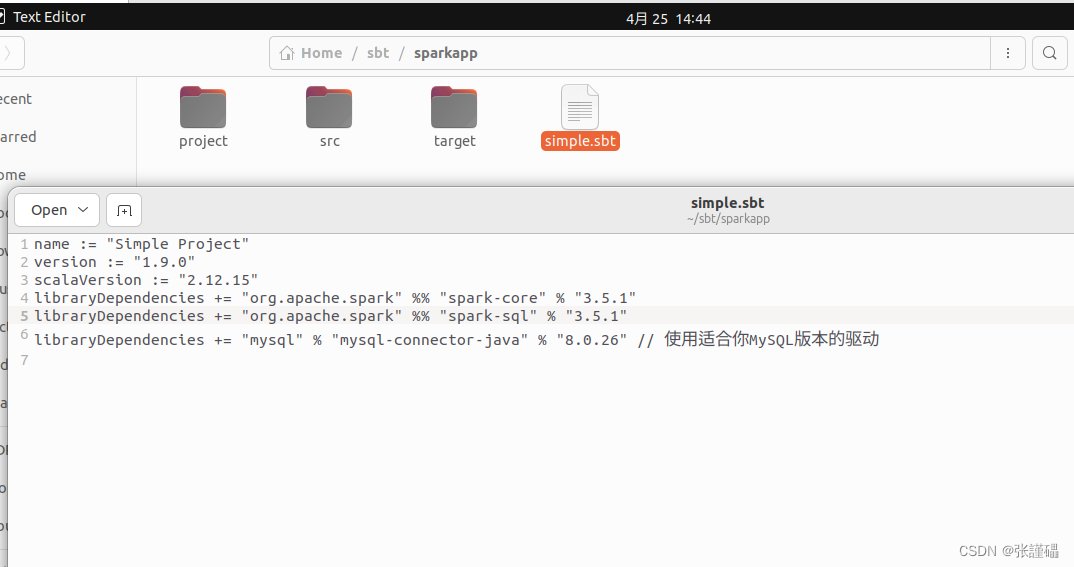
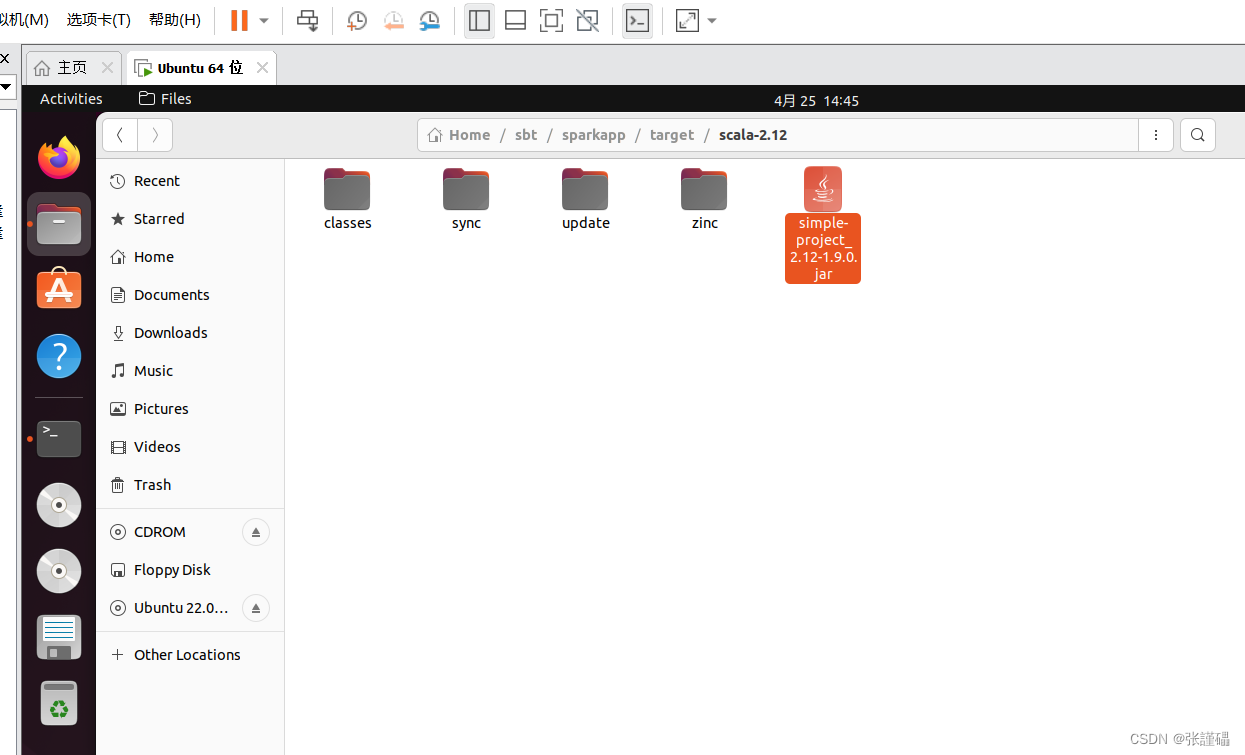
4、打包scala程序(必须在sbt/sparkapp这个路径下操作)
cd sbt/sparkapp/
/home/hadoop/sbt/sbt package
(打包生成的jar包在sbt/sparkapp/target/scala-2.12/simple-project_2.12-1.6.1.jar) 不同的路径生成的位置也不一样
5、通过spark-submit运行程序
/usr/local/spark-3.5.1/bin/spark-submit --class "HelloWorld" ./target/scala-2.12/simple-project_2.12-1.9.0.jar/usr/local/spark-3.5.1/bin/spark-submit //spark-submit的对应位置
--class "HelloWorld" //引用类的名称
./target/scala-2.12/simple-project_2.12-1.9.0.jar //刚才打包的对应的位置
运行结果

复杂代码的实现
1、创建一个代码文件text2.scala
cd sbt/sparkapp/src/main/scala/
vim text2.scala
在文件中增加如下内容:
这段代码,中处理了employ.txt文件,请确定对应路径下你有这个文件
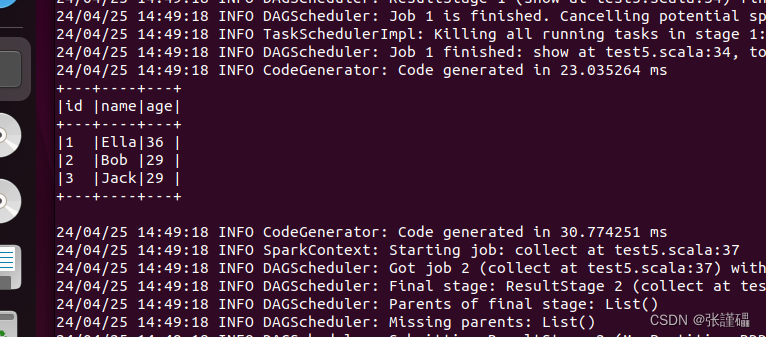
文件内容为
1,Ella,36
2,Bob,29
3,Jack,29
import org.apache.spark.sql.{SparkSession, Row}
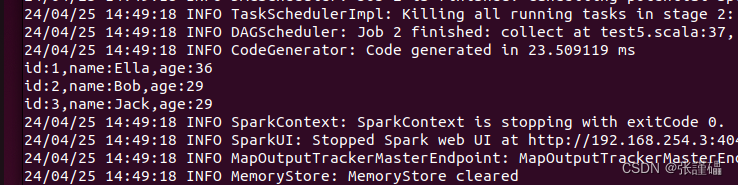
import org.apache.spark.sql.types._ object RDDToDataFrameExample { def main(args: Array[String]): Unit = { // 创建SparkSession val spark = SparkSession.builder() .appName("RDD to DataFrame Example") .master("local[*]") // 使用本地模式,如果连接到集群请更改这里 .getOrCreate() import spark.implicits._ // 指定employee.txt文件的位置 val inputFilePath = "file:///home/hadoop/employee.txt" // 从文本文件读取数据创建RDD val rdd = spark.sparkContext.textFile(inputFilePath) // 定义DataFrame的schema val schema = StructType(Array( StructField("id", IntegerType, nullable = false), StructField("name", StringType, nullable = false), StructField("age", IntegerType, nullable = false) )) // 将RDD转换为DataFrame val dataFrame = spark.createDataFrame(rdd.map { line => val parts = line.split(",") Row(parts(0).toInt, parts(1), parts(2).toInt) }, schema) // 显示DataFrame内容 dataFrame.show(false) // 按照指定格式打印所有数据 dataFrame.collect().foreach { row => println(s"id:${row.getAs[Int]("id")},name:${row.getAs[String]("name")},age:${row.getAs[Int]("age")}") } // 停止SparkSession spark.stop() }
}
2、在sbt中编译打包(必须在cd sbt/sparkapp目录下)
cd
cd sbt/sparkapp
/home/hadoop/sbt/sbt package
3、使用spark-submit命令提交运行(必须在cd sbt/sparkapp目录下)
/usr/local/spark-3.5.1/bin/spark-submit --class "RDDToDataFrameExample" ./target/scala-2.12/simple-project_2.12-1.9.0.jar4、运行后查看结果
如果你学到这里,恭喜,你已经学习sbt的安装和使用了
这篇关于如何安装sbt(sbt在ubuntu上的安装与配置)(有详细安装网站和图解)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






