本文主要是介绍copy函数+不/可变对象,python实现list每个元素依次左移,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python实现list的所有元素左移一个位置,且将所有结果保存成一个list
例如:[1,2,3,4,5]
输出:[[1,2,3,4,5], [2,3,4,5,1], [3,4,5,1,2], [4,5,1,2,3], [5,1,2,3,4]]
天真烂漫
lt = [1, 2, 3, 4, 5]
end=[]
l=len(lt)
for i in range(l):lt.append(lt.pop(0))end.append(lt)print(end)
>>>[[1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5]]
看到结果的我是有点蒙逼的???为何会这样,end每一步append的元素,最后为何变成一样的了?立刻意识到这个问题不简单,半路出家的我知道我该去看看list的底层实现了。
但在这之前,我先看了python的可变与不可变对象。
python的可变与不可变对象
不可变对象:对象存放在地址中的值不会被改变,当想要修改对象时,会新创建一个地址来存放改变后的值,而原来的对象并不发生改变;而且当两个对象的值一样的时候,只有一个地址存放,两个对象都指向这个地址。
可变对象:对象存放在地址中的值会原地改变
int str float tuple 属于不可变对象 其中tuple更与众不同
dict set list 属于可变对象
那么也就是说,list作为可变对象,end每次append的时候,是原地改变的,
lt = [1, 2, 3, 4, 5]
end=[]
for i in range(len(lt)):print(id(lt))lt.append(lt.pop(0))print(id(lt))end.append(lt)print(end)
>>>
2897136022472
2897136022472
2897136022472
2897136022472
2897136022472
2897136022472
2897136022472
2897136022472
2897136022472
2897136022472
[[1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5]]
从id的结果可以看出来,确实列表的id一直没有变。再debug过程中观察


当再一次为end加入元素时,会在原有的列表基础上进行修改,只不过这次连接的是两个lt,而lt对象指向的内存地址中的值是[3, ,4, 5, 1, 2]所以end就会改变。这时可以用copy函数解决这个问题,这里说明一下copy函数。
python传递变量值的三种形式:赋值,浅拷贝,深拷贝
- 基本数据类型
在Python中基本数据类型(整型、字符串、布尔及None)的赋值、深浅拷贝没有任何意义,都是指向同一块内存地址,也不存在层次问题。
import copy
n1 = 'abc'
n2 = n1
n3 = copy.copy(n1)
n4 = copy.deepcopy(n1)
print(id(n1)) #输出140350336680040
print(id(n2)) #输出140350336680040
print(id(n3)) #输出140350336680040
print(id(n4)) #输出140350336680040
- 列表、元组、字典等非基本数据类型对象的赋值、深浅拷贝的区别
假设字典n1 = {“k1”: “abc”, “k2”: 123, “k3”: [“abc”, 123]}
赋值是将变量的内存赋给另一个变量,让另一个变量指向那个内存地址
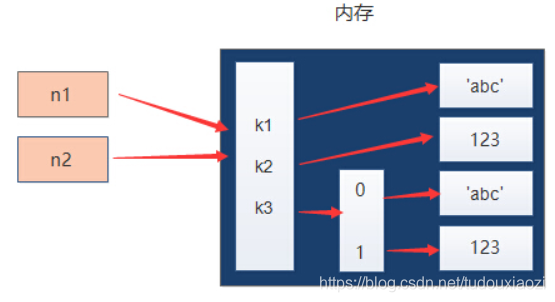
- 浅拷贝
在内存中将第一层额外开辟空间进行存放

n1 = {"k1": "abc", "k2": 123, "k3": ["abc", 123]}
print(id(n1)) #140350328984328
n3 = copy.copy(n1)
print(id(n3)) #140350328986504可以看n3的内存地址已经和n1不同了print(id(n1['k3'])) #140350328603976
print(id(n3['k3'])) #140350328603976 字典里的列表还是指向同一个列表
2.深拷贝
深拷贝就是在内存中将数据重新创建一份,不仅仅是第一层,第二层、第三层…都会重新创建
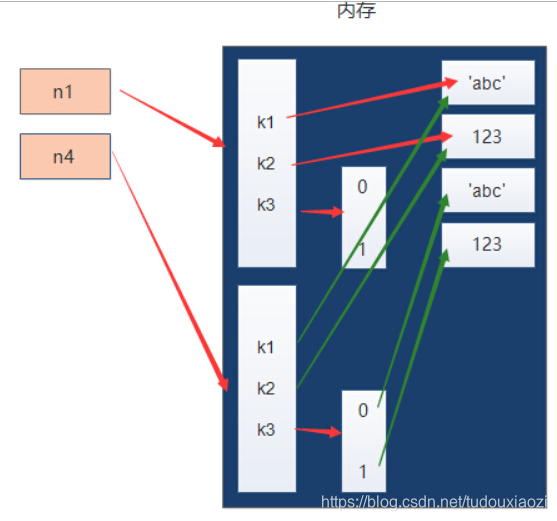
n1 = {"k1": "abc", "k2": 123, "k3": ["abc", 123]}
print(id(n1)) #140350328984328
n3 = copy.deepcopy(n1)print(id(n1['k3'])) #140350328603976
print(id(n3['k3'])) #140350328604296
#可以看到第二层的列表也拷贝了一份,内存地址已经完全不一样
言归正传,以上的问题既可以结局了
lt = [1, 2, 3, 4, 5]
end=[]
for i in range(len(lt)):lt.append(lt.pop(0))end.append(lt.copy())print(end)
>>>[[2, 3, 4, 5, 1], [3, 4, 5, 1, 2], [4, 5, 1, 2, 3], [5, 1, 2, 3, 4], [1, 2, 3, 4, 5]]
perfect!
这篇关于copy函数+不/可变对象,python实现list每个元素依次左移的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






