本文主要是介绍预测房屋价格(使用SGDRegressor随机梯度下降回归),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
线性回归:预测未来趋势01(预测房屋价格)
文章目录
- 线性回归:预测未来趋势01(预测房屋价格)
- 前言
- 一、案例介绍:
- 二、架构图:(流程图)
- 三、使用了什么技术:(知识点)
- (1)标准化数据:(有3种方式)
- (2)预测准确率得分:Score
- (3)均方误差:MSE
- (4)SGDRegressor:随机梯度下降回归
- 四、结果示意图:
- 五、具体代码与分析:
- 导库
- 任务1:可视化房屋数据
- 执行结果:(使用散点图进行可视化)
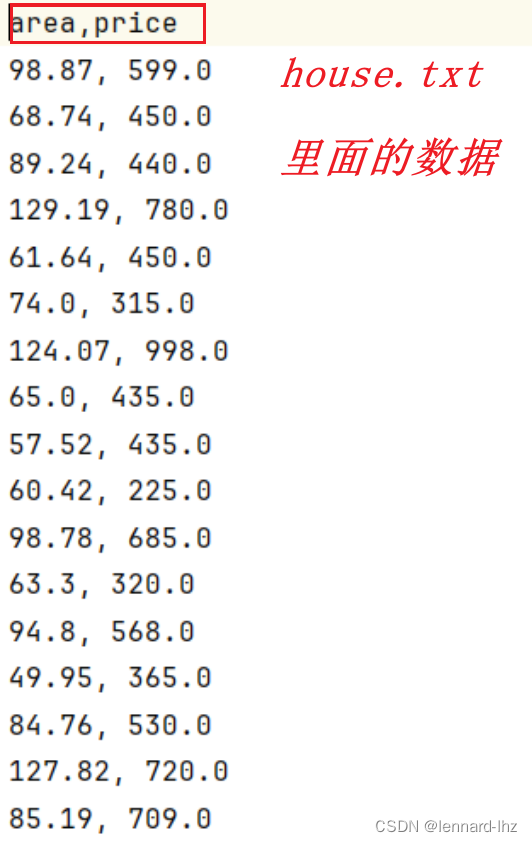
- 补充:(house.txt里面的数据展示)
- 任务2:训练线性回归模型
- 执行结果:
- 补充:(x_test 和 y_test的结果展示)
- 任务3:测试以及评估线性回归模型
- 执行结果:
- 六、总结:须要注意的地方 && 改进之处:(个人思考)
- 七、附录:完整代码
- 总结
前言
使用SGDRegressor随机梯度下降回归
提示:以下是本篇文章正文内容:
一、案例介绍:
从房屋交易的历史记录中发现某种规律,来预测房屋价格的走势。(极其简略的版本)
划分为3个任务:
任务1:可视化房屋数据
任务2:训练线性回归模型
任务3:测试以及评估线性回归模型
二、架构图:(流程图)
1.通过观察散点图来确定是否可以使用线性回归。
2.不可就要寻找其他方法。否则进行下一步。(判断是否使用线性回归方法来预测)
3.数据预处理(合并、清洗、标准化、转换),在这里使用离差标准化的方式对数据进行标准化处理
4.训练模型fit
5.评估模型的性能score(判断模型是否合适)
6.使用模型预测房屋价格predict
三、使用了什么技术:(知识点)
(1)标准化数据:(有3种方式)

(2)预测准确率得分:Score
# 训练集 和 测试集的预测准确率得分
model.score(x_train,y_train)
model.score(x_test,y_test)
预测准确率得分score又叫做判定系数,
返回值反映了因变量y的波动有多少可以被自变量x的波动所描述,
就是y的波动中有多少可以由控制x来解释。
得分越高,线性回归方程的拟合程度越高。
(3)均方误差:MSE
MSE = np.mean((y_test - y_pred)**2)
均方误差(Mean Squared Error, MSE)是一种在回归分析中常用的损失函数,
用于衡量模型预测值与实际观测值之间的差异。
MSE 提供了预测错误的量化度量,帮助我们评估模型的性能。
较小的MSE值通常意味着模型的预测能力更强,即模型的预测值更接近实际观测值。
(4)SGDRegressor:随机梯度下降回归
SGDRegressor:实现随机梯度下降回归,
随机梯度下降是一种优化算法,常用于大规模数据集的线性回归问题。
Stochastic Gradient Descent:随机梯度下降
四、结果示意图:

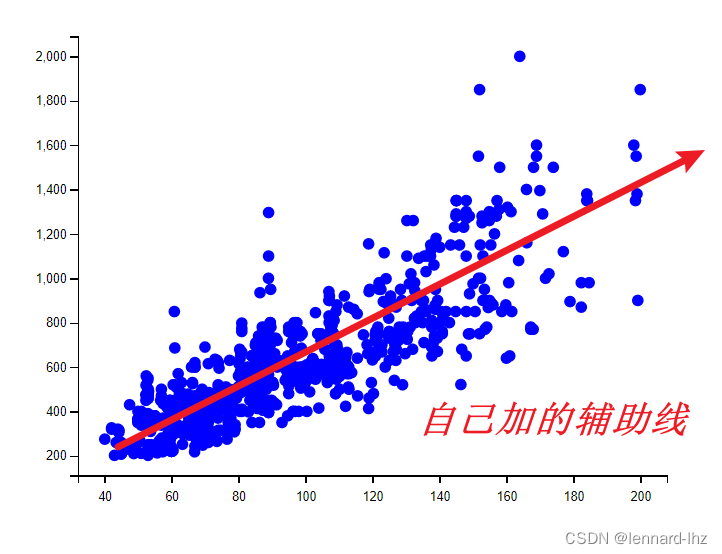
五、具体代码与分析:
导库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 导入随机梯度下降回归模型函数
from sklearn.linear_model import SGDRegressor
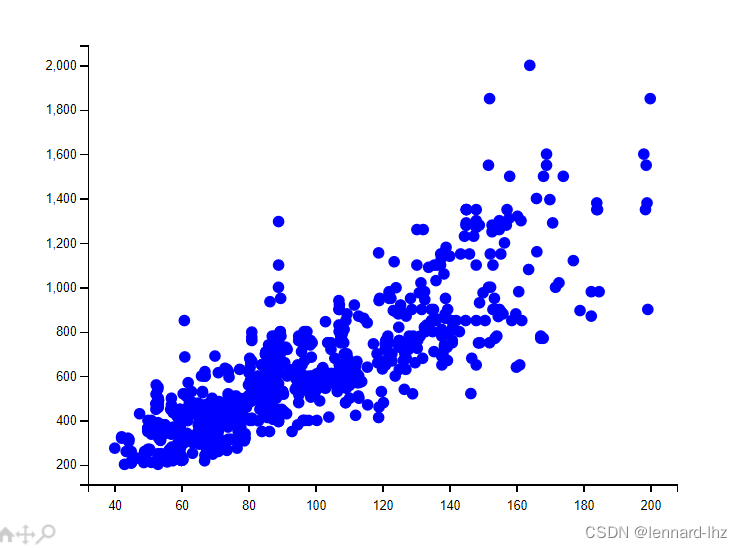
任务1:可视化房屋数据
df=pd.read_csv('data\house.txt',sep=',',header=0)# 读取文件
plt.scatter(df['area'],df['price'],c='b')# 指定散点图的颜色为蓝色
plt.show()
header=0:表示以第0行数据为列名
df是数据框,df[‘area’]是单列数据Series,通过字典的方式进行访问
c:接收color或数组,这里接收的是‘blue蓝色;
如果接收的是一个数组,按照数组的值分配颜色,有多少种值,就有多少种颜色。(在分类里面常用到)
执行结果:(使用散点图进行可视化)
补充:(house.txt里面的数据展示)
任务2:训练线性回归模型
# 1.数据的归一化处理:min-max标准化
df=(df-df.min())/(df.max()-df.min())# 2.产生训练集和测试集
train_data=df.sample(frac=0.8,replace=False)# 训练集
test_data=df.drop(train_data.index)# 测试集
#转换数据:将数据转换为二维数组的形式:行自适应,1列
x_train=train_data['area'].values.reshape(-1, 1)
y_train=train_data['price'].values
x_test=test_data['area'].values.reshape(-1, 1)
y_test=test_data['price'].values# 3.构建并训练模型
model=SGDRegressor(max_iter=500,learning_rate='constant',eta0=0.01)# 构建线性回归模型
model.fit(x_train,y_train)# 训练模型
# 输出训练结果:准确率得分 和 模型的自变量系数、截距
pre_score=model.score(x_train,y_train)
print('score=',pre_score)
print('coef=',model.coef_,'intercept=',model.intercept_)
sample:用于从df中随机抽取样本
frac:表示抽取的比例
replace=False:表示每个样本只能被选中一次,不允许被替换???
使用sample的好处:有一定的随机性,是结果更加可靠。
train_data.index:获取train_data的行索引
reshape(-1, 1) :将一维数组转换为二维数组,其中每一行只有一个元素。用于某些函数或方法期望输入是一个二维数组时。
max_iter=500 :最大迭代次数为500次。
learning_rate=‘constant’:学习率策略是常数,即在整个训练过程中学习率保持不变。
eta0=0.01 :初始学习率是0.01。
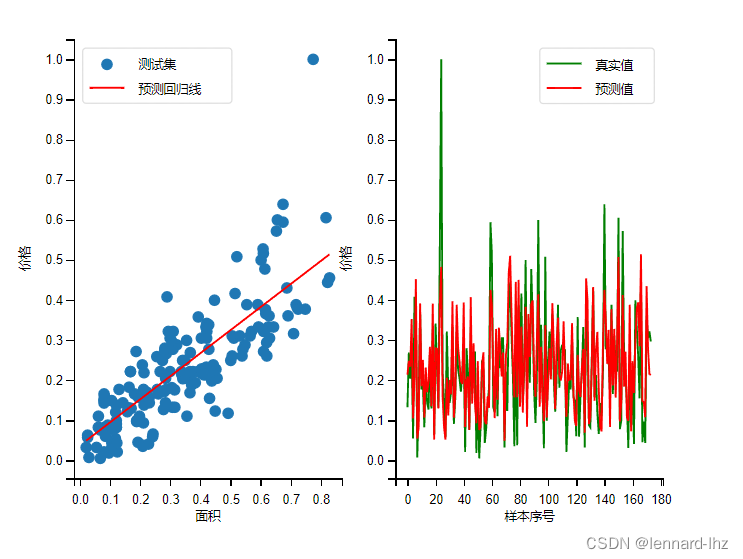
执行结果:

补充:(x_test 和 y_test的结果展示)


任务3:测试以及评估线性回归模型
# 1.计算均方误差
y_pred=model.predict(x_test)
print('测试集准确性得分=%.5f'%model.score(x_test,y_test))
#计算测试集的损失(用均方差)
MSE=np.mean((y_test - y_pred)**2)# 误差的平方的均值
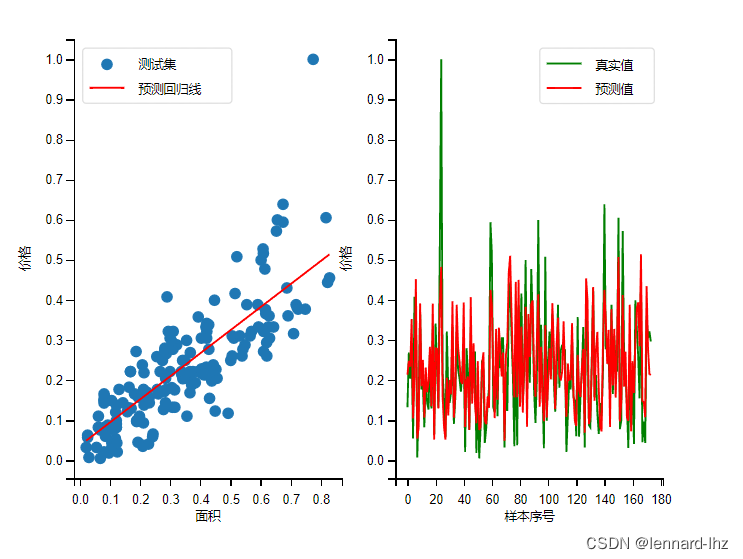
print('损失MSE={:.5f}'.format(MSE))# 2.绘制效果预测图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10,4))
ax1=plt.subplot(121)
# (1)先后绘制出 真实样本散点图 和 预测回归线
plt.scatter(x_test,y_test,label='测试集')
plt.plot(x_test,y_pred,'r',label='预测回归线')
ax1.set_xlabel('面积')
ax1.set_ylabel('价格')
plt.legend(loc='upper left')
# (2)先后绘制出 真实值 和 预测值 的分布折线图
ax2=plt.subplot(122)
x=range(0,len(y_test))
plt.plot(x,y_test,'g',label='真实值')
plt.plot(x,y_pred,'r',label='预测值')
ax2.set_xlabel('样本序号')
ax2.set_ylabel('价格')
plt.legend(loc='upper right')
plt.show()
误差:真实值-预测值(test-pred)
plt.plot(x_test,y_pred,‘r’,label=‘预测回归线’):由于是线性回归预测,所以虽然是画折线图,但最终的结果是以“直线”的形式呈现的。
upper left:左上
upper right:右上
执行结果:
六、总结:须要注意的地方 && 改进之处:(个人思考)
1.如何用其他的方法实现“标准化数据”???
2.如何使用其他的方法产生“训练集和测试集”???
比如:train_test_split(data, target, test_size=0.2, random_state=42)
3.为什么会有“model.coef_”这样以下划线结尾的属性???
4.可视化数据,可以看得懂,但是自己写就总是差点意思。
自己要去整理一套模版。
七、附录:完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 导入随机梯度下降回归模型函数
from sklearn.linear_model import SGDRegressordf=pd.read_csv('data\house.txt',sep=',',header=0)# 读取文件
plt.scatter(df['area'],df['price'],c='b')# 指定散点图的颜色为蓝色
plt.show()# 1.数据的归一化处理:min-max标准化
df=(df-df.min())/(df.max()-df.min())# 2.产生训练集和测试集
train_data=df.sample(frac=0.8,replace=False)# 训练集
test_data=df.drop(train_data.index)# 测试集
#转换数据:将数据转换为二维数组的形式:行自适应,1列
x_train=train_data['area'].values.reshape(-1, 1)
y_train=train_data['price'].values
x_test=test_data['area'].values.reshape(-1, 1)
y_test=test_data['price'].values# 3.构建并训练模型
model=SGDRegressor(max_iter=500,learning_rate='constant',eta0=0.01)# 构建线性回归模型
model.fit(x_train,y_train)# 训练模型
# 输出训练结果:准确率得分 和 模型的自变量系数、截距
pre_score=model.score(x_train,y_train)
print('score=',pre_score)
print('coef=',model.coef_,'intercept=',model.intercept_)# 1.计算均方误差
y_pred=model.predict(x_test)
print('测试集准确性得分=%.5f'%model.score(x_test,y_test))
#计算测试集的损失(用均方差)
MSE=np.mean((y_test - y_pred)**2)# 误差的平方的均值
print('损失MSE={:.5f}'.format(MSE))# 2.绘制效果预测图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10,4))
ax1=plt.subplot(121)
# (1)先后绘制出 真实样本散点图 和 预测回归线
plt.scatter(x_test,y_test,label='测试集')
plt.plot(x_test,y_pred,'r',label='预测回归线')
ax1.set_xlabel('面积')
ax1.set_ylabel('价格')
plt.legend(loc='upper left')
# (2)先后绘制出 真实值 和 预测值 的分布折线图
ax2=plt.subplot(122)
x=range(0,len(y_test))
plt.plot(x,y_test,'g',label='真实值')
plt.plot(x,y_pred,'r',label='预测值')
ax2.set_xlabel('样本序号')
ax2.set_ylabel('价格')
plt.legend(loc='upper right')
plt.show()
总结
提示:这里对文章进行总结:
💕💕💕
这篇关于预测房屋价格(使用SGDRegressor随机梯度下降回归)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




