本文主要是介绍YOLOv3没有比这详细的了吧,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
YOLOv3:目标检测基于YOLOv2的改进
在目标检测领域,YOLO(You Only Look Once)系列以其出色的性能和速度而闻名。YOLOv3作为该系列的第三个版本,不仅继承了前身YOLOv2的优势,还在多个方面进行了创新和改进。本文将深入探讨YOLOv3的架构、关键技术以及与YOLOv2相比所做的改进。
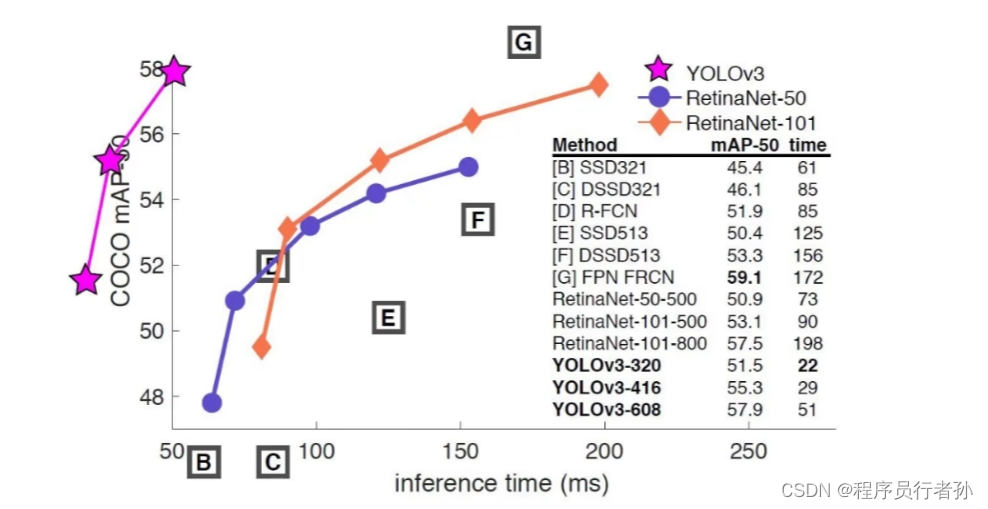 YOLOv3:在座的都是trash,不是针对谁,这图画的过分了?!!
YOLOv3:在座的都是trash,不是针对谁,这图画的过分了?!!
YOLOv3简介
YOLOv3介绍
YOLOv3(You Only Look Once version 3)是一种流行的实时目标检测算法,由Joseph Redmon等人提出。它是YOLO系列的第三个版本,在精度和速度上都有显著提升。
核心思想
YOLOv3将目标检测任务视为一个回归问题,通过单个神经网络模型直接在整个图像上预测目标的类别和边界框。相比于传统的目标检测算法,YOLOv3具有以下特点:
- 单次前向传播: YOLOv3通过单次前向传播即可同时预测出图像中所有目标的类别和位置信息,而不需要像其他方法一样使用多次滑动窗口或候选框。
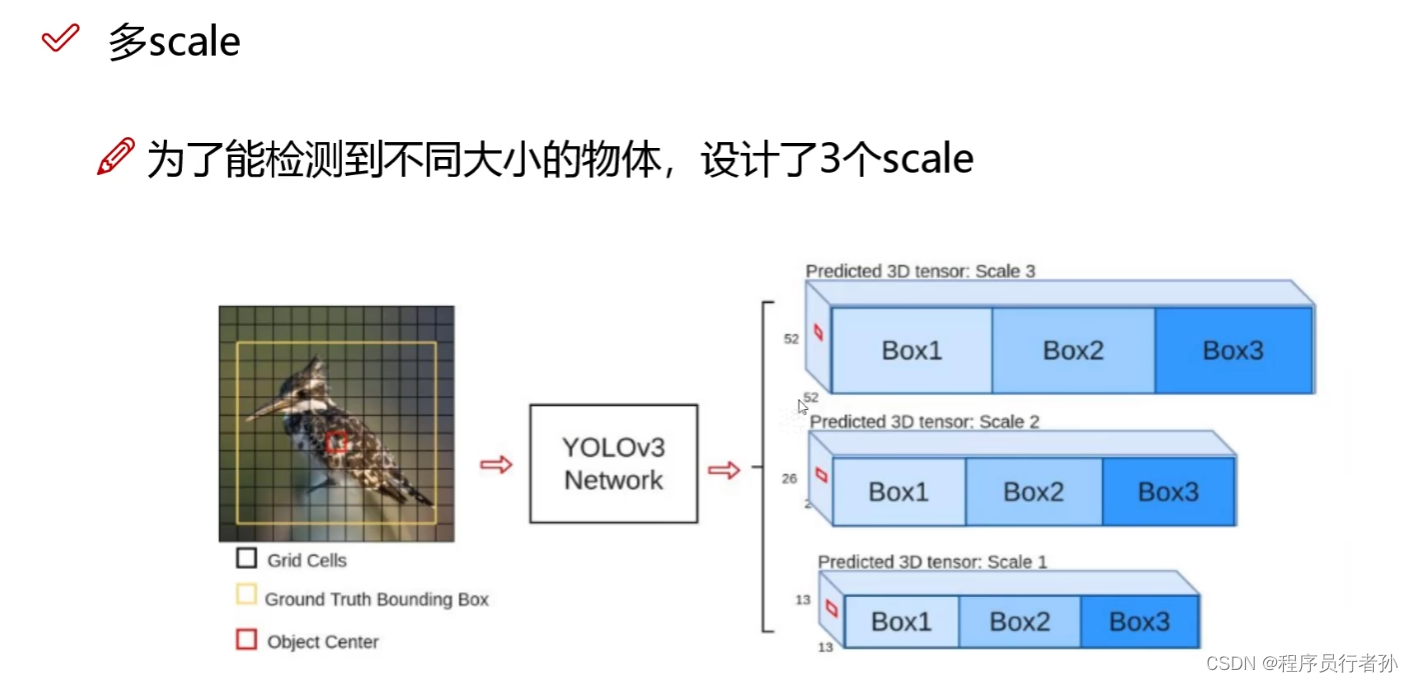
- 多尺度特征图: YOLOv3使用了多尺度的特征图来检测不同尺度的目标,这样可以提高对小目标和远处目标的检测效果。
- 多尺度预测框: YOLOv3在每个尺度上使用不同大小的锚框(anchor boxes),以适应不同大小和形状的目标。
- 交叉特征融合: YOLOv3通过将不同层次的特征图进行融合,从而提高了目标检测的准确性和稳定性。
- 分类与定位的联合训练: YOLOv3将目标检测任务分解为目标分类和边界框定位两个子任务,并进行联合训练,从而更好地优化目标检测性能。
应用场景
YOLOv3在速度和准确性之间取得了良好的平衡,适用于需要实时目标检测的应用场景,如自动驾驶、视频监控、智能家居等领域。同时,其简单的设计和易用性也使其成为学术界和工业界广泛应用的目标检测算法之一。
YOLOv2与YOLOv3的比较
YOLOv2的贡献
- 快速检测:YOLOv2通过减少计算量和优化网络结构,实现了快速的目标检测。
- 批量归一化:引入批量归一化技术,提高了训练的稳定性和速度。
YOLOv3的改进
- 更深的基础网络:从Darknet-19升级到Darknet-53,增强了特征提取的能力。
- 多尺度预测:在不同尺度上进行预测,更好地捕捉不同大小的目标。
- 特征融合:通过低层次和高层次特征的融合,提高了小目标的检测准确率。
- 锚点框优化:改进了锚点框的设计,使其更适应目标的实际形状。
- 复合损失函数:引入了同时考虑类别和空间位置的损失函数。
YOLOv3的关键技术
YOLOv3广泛采用了深度可分离卷积,这种卷积操作既减少了模型的参数数量,也降低了计算量。
YOLOv3中的深度可分离卷积
深度可分离卷积是一种卷积神经网络中的卷积操作,它将传统的卷积操作分成两个步骤:深度卷积和逐点卷积。以下是YOLOv3中深度可分离卷积的介绍:
深度卷积(Depthwise Convolution)
- 作用: 深度卷积只对输入的每个通道进行卷积操作,产生相同数量的输出通道。
- 优势: 由于每个通道之间的卷积是独立进行的,因此深度卷积在减少计算量的同时保持了特征图的维度。
- 效果: 深度卷积可以提取输入特征图的空间信息。
逐点卷积(Pointwise Convolution)
- 作用: 逐点卷积是指使用1x1的卷积核对深度卷积的输出进行卷积操作。
- 优势: 逐点卷积用较少的参数进行卷积操作,从而减少了计算量和存储需求。
- 效果: 逐点卷积可以将特征图的维度映射到任意大小,并且可以引入非线性。
YOLOv3中的应用
在YOLOv3中,深度可分离卷积被广泛应用于模型的各个层次,特别是在骨干网络和特征提取层中。通过使用深度可分离卷积,YOLOv3能够在减少计算量的同时保持模型的准确性,并且能够更好地处理不同尺度和大小的目标。
空间金字塔池化
空间金字塔池化是一种用于解决目标检测和图像分类任务中输入尺寸不固定的图像的技术。它允许神经网络在处理具有不同尺寸的图像时,能够自适应地对其进行特征提取。
概念
多尺度池化: 空间金字塔池化将输入图像分成不同大小的网格,并在每个网格上应用池化操作。不同尺度的池化操作可以捕获图像的全局、半局部和局部特征。
固定大小输出: 不同大小的网格会产生不同大小的特征图,但是空间金字塔池化将这些特征图转换为固定大小的特征向量,以便输入到后续的全连接层或分类器中。
SPP样例代码
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SPP(nn.Module):def __init__(self, levels=[1, 2, 4]):super(SPP, self).__init__()self.levels = levelsdef forward(self, x):N, C, H, W = x.size()pooled_features = []for level in self.levels:# 计算每个级别的池化大小pool_size = (H // level, W // level)# 进行最大池化pooled = F.max_pool2d(x, kernel_size=pool_size, stride=pool_size).view(N, -1)pooled_features.append(pooled)# 拼接所有级别的池化结果output = torch.cat(pooled_features, dim=1)return output# 创建一个简单的神经网络模型,将SPP层添加到网络中
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)self.spp = SPP() # 使用默认的SPP配置self.fc = nn.Linear(256 * sum([level ** 2 for level in [1, 2, 4]]), 10)def forward(self, x):x = F.relu(self.conv1(x))x = F.max_pool2d(x, kernel_size=2, stride=2)x = F.relu(self.conv2(x))x = F.max_pool2d(x, kernel_size=2, stride=2)x = F.relu(self.conv3(x))x = self.spp(x)x = self.fc(x)return x# 创建一个简单的神经网络实例
model = SimpleCNN()# 定义输入数据
inputs = torch.randn(64, 3, 32, 32) # 64张3通道的32x32大小的图像# 运行模型
outputs = model(inputs)# 输出结果的形状
print(outputs.shape)批量归一化(Batch Normalization)
批量归一化是一种常用的神经网络层,旨在加速神经网络的训练过程并提高其性能。以下是批量归一化的介绍:
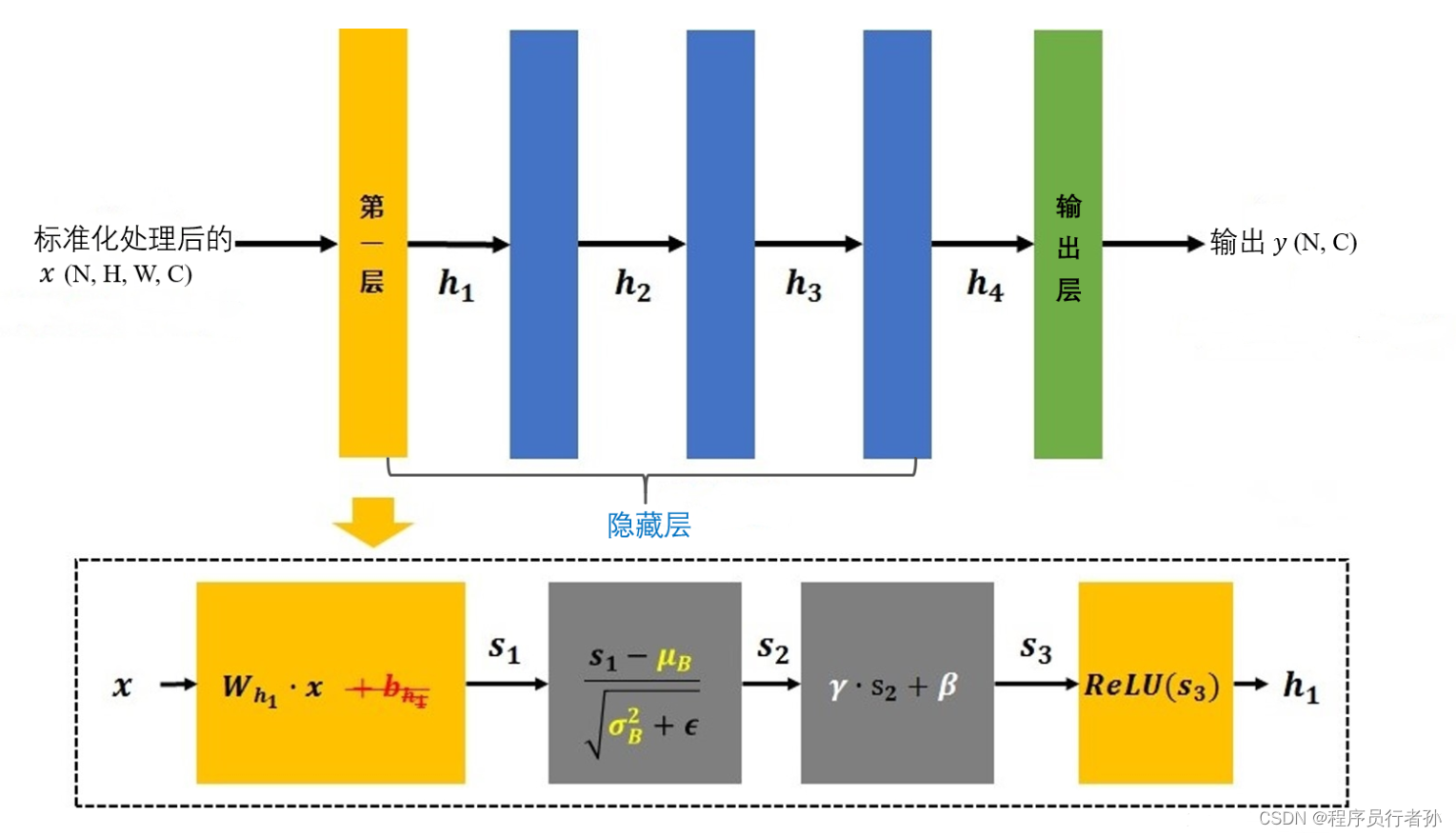
概念
-
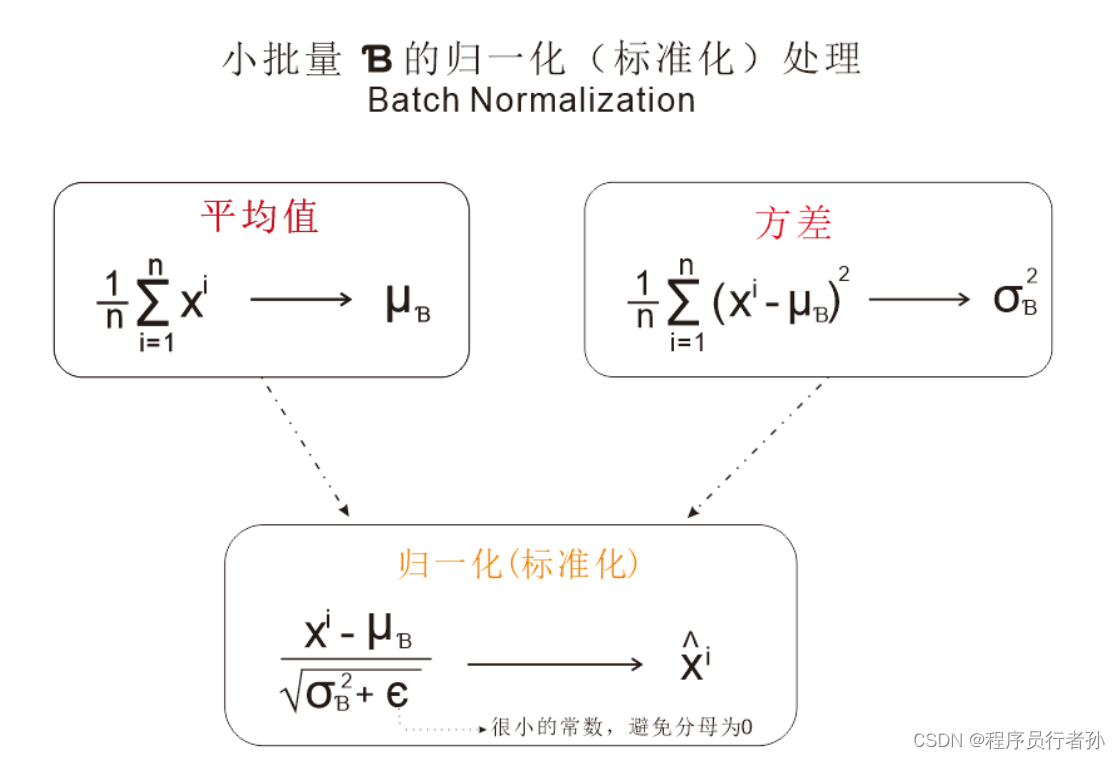
归一化: 批量归一化通过对每个批次的数据进行归一化操作,使得数据分布更稳定,有助于加速神经网络的收敛。
-
归一化操作: 对于每个特征维度,批量归一化计算其均值和标准差,并将其应用于该特征维度的所有样本。
-
规范化: 在进行归一化之后,批量归一化通过缩放和平移操作重新调整特征的均值和方差,以便模型可以学习到更多有用的特征。
优势
-
加速训练: 批量归一化可以加速神经网络的训练过程,减少梯度消失和梯度爆炸问题,从而使模型更快地收敛。
-
提高性能: 批量归一化有助于提高模型的泛化能力和性能,减少过拟合,并且能够处理更复杂的任务。
应用
批量归一化被广泛应用于深度神经网络中的各种架构,包括卷积神经网络(CNN)、全连接神经网络(FCN)和循环神经网络(RNN)等。它通常被添加到激活函数之前,或者作为卷积层或全连接层的一部分。
批量归一化在加速模型训练和提高模型性能方面发挥着重要作用,是深度学习中不可或缺的一部分。
代码样例
import torch
import torch.nn as nn# 定义一个简单的神经网络模型
class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(784, 100)self.fc2 = nn.Linear(100, 10)self.relu = nn.ReLU()self.bn = nn.BatchNorm1d(100) # 添加批量归一化层def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.bn(x) # 在激活函数之后应用批量归一化x = self.fc2(x)return x# 创建一个简单的神经网络实例
model = SimpleNN()# 定义输入数据
inputs = torch.randn(64, 784)# 运行模型
outputs = model(inputs)# 输出结果的形状
print(outputs.shape)
残差连接(Residual Connection)
残差连接是一种神经网络中的技术,旨在解决深层网络训练中的梯度消失和梯度爆炸问题。它通过将输入直接添加到网络中间的某一层的输出来构建网络结构。
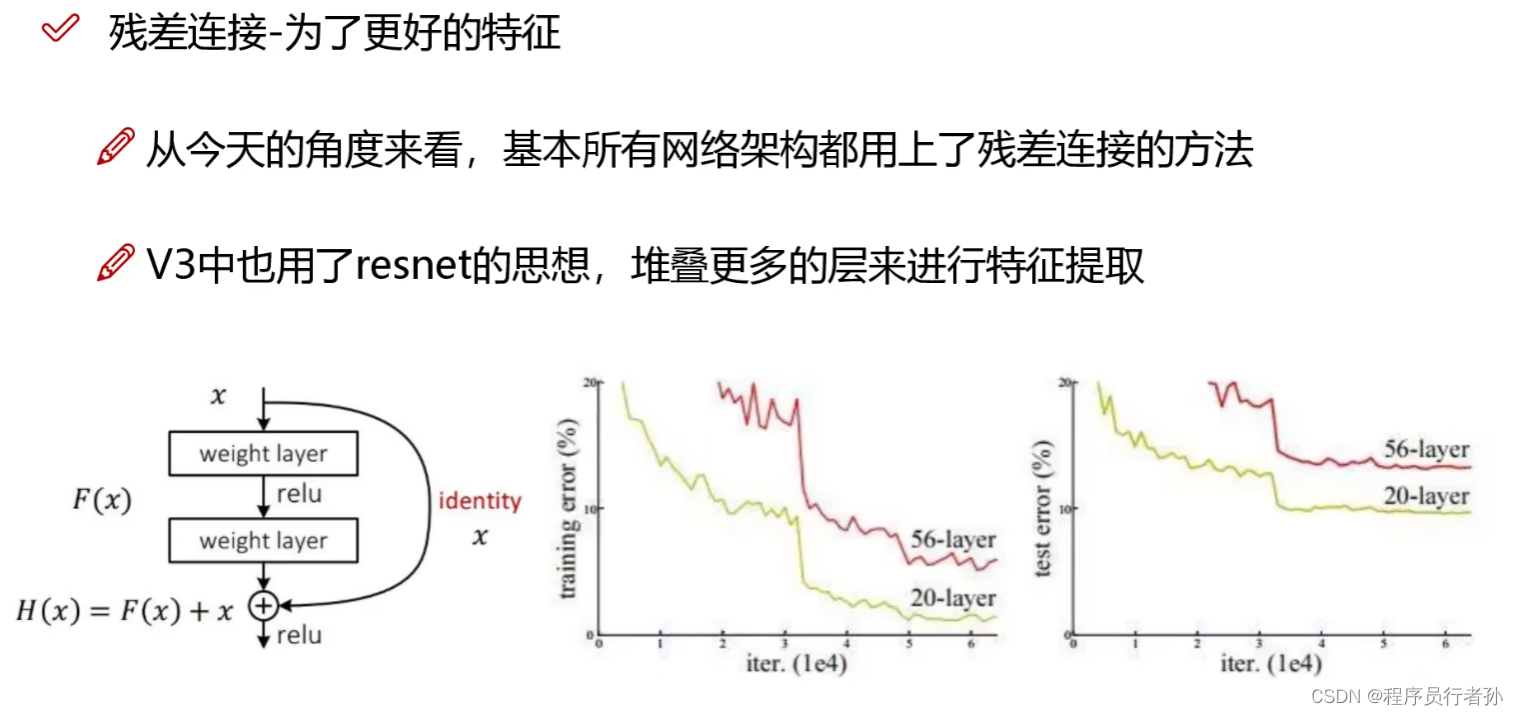 如图,加了残差后,效果明显好很多
如图,加了残差后,效果明显好很多
概念
-
跳跃连接: 残差连接通过跨越多个层级直接连接输入和输出,形成了一种跳跃连接,允许信息在网络中更快地传播。
-
残差块: 残差连接通常以残差块(Residual Block)的形式出现,其中包含了跳跃连接。典型的残差块由两个或多个卷积层组成,中间包含了跳跃连接。
-
捷径: 跳跃连接也被称为捷径(Shortcut),它允许梯度在网络中更直接地流动,从而减轻了梯度消失和梯度爆炸问题。
优势
-
减轻梯度问题: 残差连接通过跳跃连接提供了一种更直接的梯度传播路径,有助于缓解梯度消失和梯度爆炸问题,使得网络更容易训练。
-
加速训练: 残差连接可以加速深层网络的训练过程,因为它允许网络更快地收敛,并且可以处理更深的网络结构。
应用
-
ResNet: 残差连接最著名的应用之一是在ResNet(Residual Network)中。ResNet是由微软提出的一个非常深的神经网络结构,它通过残差连接成功地训练了一个152层的网络,同时避免了梯度消失和梯度爆炸问题。
-
其他架构: 残差连接不仅在ResNet中应用广泛,在其他深层网络结构中也经常使用,例如在自然语言处理(NLP)任务中的Transformer模型中。
残差连接是深度学习中一个重要的技术,通过提供更直接的信息流动路径,有助于解决深层网络训练中的梯度问题,加速了模型的训练过程,并使得更深的网络结构成为可能。
代码样例
import torch
import torch.nn as nn# 定义一个简单的残差块
class ResidualBlock(nn.Module):def __init__(self, in_channels, out_channels, stride=1):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.downsample = Noneif stride != 1 or in_channels != out_channels:self.downsample = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(out_channels))def forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return out# 定义一个简单的ResNet模型
class ResNet(nn.Module):def __init__(self, block, layers, num_classes=10):super(ResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.layer1 = self.make_layer(block, 64, layers[0], stride=1)self.layer2 = self.make_layer(block, 128, layers[1], stride=2)self.layer3 = self.make_layer(block, 256, layers[2], stride=2)self.layer4 = self.make_layer(block, 512, layers[3], stride=2)self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512, num_classes)def make_layer(self, block, out_channels, blocks, stride=1):layers = []layers.append(block(self.in_channels, out_channels, stride))self.in_channels = out_channelsfor _ in range(1, blocks):layers.append(block(out_channels, out_channels))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avg_pool(x)x = x.view(x.size(0), -1)x = self.fc(x)return x# 创建一个简单的ResNet实例
resnet = ResNet(ResidualBlock, [2, 2, 2, 2])# 定义输入数据
inputs = torch.randn(1, 3, 32, 32)# 运行模型
outputs = resnet(inputs)# 输出结果的形状
print(outputs.shape)YOLOv3的应用场景
YOLOv3因其高速度和高准确性,被广泛应用于以下领域:
- 交通监控:实时检测道路上的车辆和行人。
- 人脸识别:在安全和监控系统中识别个人。
- 医学图像分析:辅助医生进行疾病诊断。
- 无人驾驶:为自动驾驶汽车提供环境感知能力。
- 工业自动化:提高生产线的自动化水平。
YOLOv3的局限性
尽管YOLOv3在目标检测领域取得了显著的成果,但它也有一些局限性:
- 小目标检测:对小目标的检测能力相对有限。
- 复杂背景鲁棒性:在复杂背景下的鲁棒性有待提高。
- 计算资源需求:需要较多的计算资源。
结论
YOLOv3作为目标检测领域的一个里程碑,不仅在速度上实现了突破,也在准确性上取得了进步。它在YOLOv2的基础上所做的改进,为未来的研究和应用提供了新的方向。解决了YOLOv2版本的一下问题,还有比如前面提到的小目标检测、鲁棒性问题,这些是以后版本,甚至今天都在研究的热门方向
祝各位看官早日中稿cvpr~(点个赞吧)
这篇关于YOLOv3没有比这详细的了吧的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





