本文主要是介绍Oracle进阶(2)——物化视图案例延伸以及序列、同义词,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、物化视图
物化视图(Materialized View)是 Oracle 数据库中的一个对象,它是一个预先计算和存储的查询结果集,类似于视图,但与视图不同的是,物化视图会将查询结果保存在物理存储中,而不是动态计算结果。这样可以提高查询性能,特别是对于复杂的查询或者包含聚合函数的查询。物化视图在创建时可以指定刷新方式,可以是手动刷新或自动刷新。自动刷新的物化视图会在底层表发生改变时自动更新,而手动刷新的物化视图需要手动触发刷新操作。物化视图通常用于提高查询性能,减少复杂查询的执行时间,特别是在数据仓库等需要频繁进行聚合查询或者数据汇总的场景中。
注意:以下案例图标关系如下:
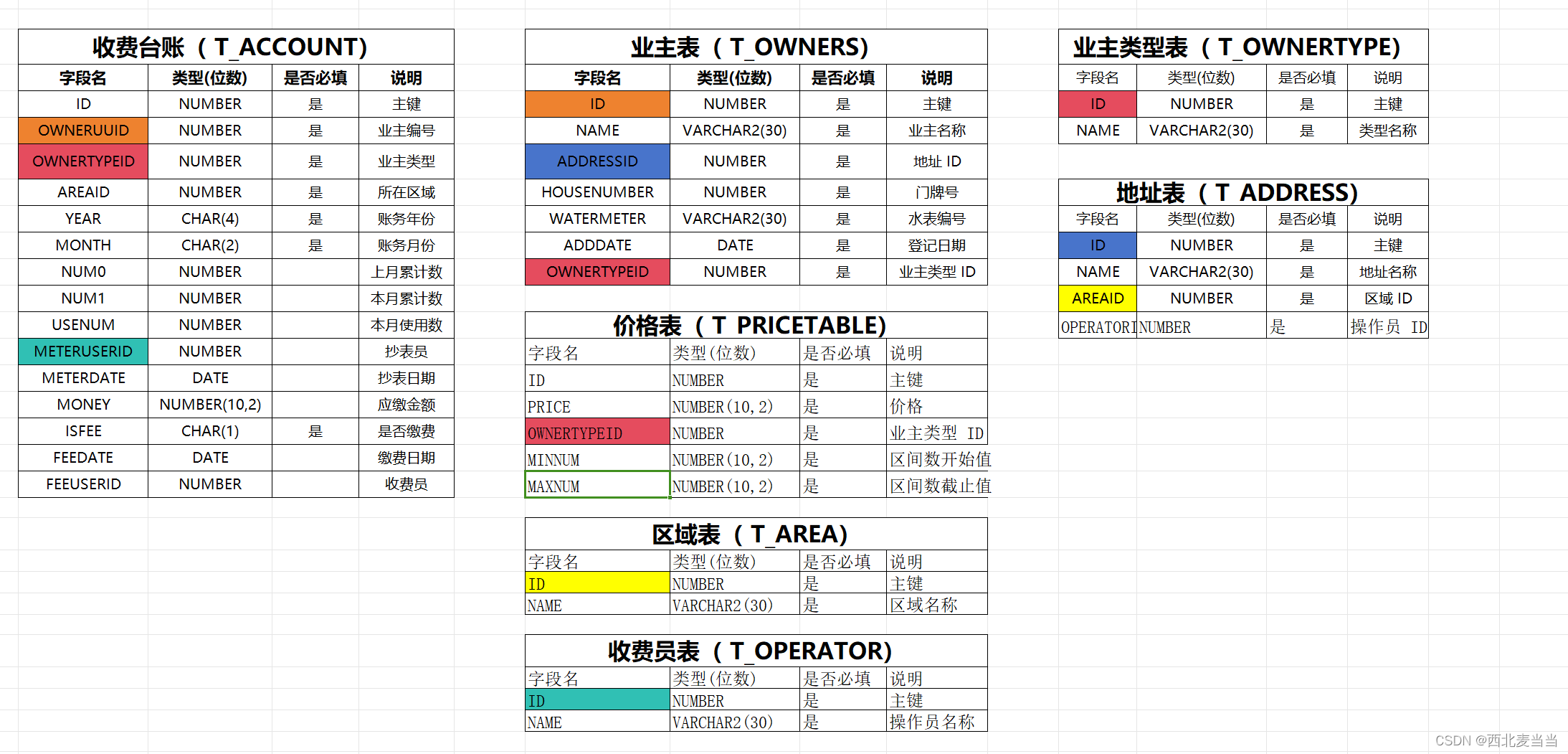
1、物化视图----手动刷新、自动刷新、延时生成数据
-- todo 1 需求:查询地址 ID,地址名称和所属区域名称 t_address t_area
-- 创建手动更新的物化视图(默认)
-- create materialized view 视图名
-- build immediate
-- refresh force on demand
create materialized view te1
build immediate
refresh force on demand
as
select T_ADDRESS.ID, T_ADDRESS.NAME, T_AREA.NAME area
from T_ADDRESSinner join T_AREA on T_ADDRESS.AREAID = T_AREA.ID;
-- 查询视图
select * from te1;
-- 向 t_address添加数据 (8,'宏福苑小区',1,1) 查看是否同步数据
insert into t_address values(8,'宏福苑小区',1,1);
commit;
-- 这里需要手动刷新 begin dbms_mview.refresh('te1') end;
begindbms_mview.refresh('te1');
end;-- todo 2 创建自动更新的物化视图
-- 需求:查询地址 ID,地址名称和所属区域名称 t_address t_area
-- create materialized view 视图名
-- build immediate
-- refresh force on commit
create materialized view te2
build immediate
refresh force on commit
as
select T_ADDRESS.ID, T_ADDRESS.NAME, T_AREA.NAME area
from T_ADDRESSinner join T_AREA on T_ADDRESS.AREAID = T_AREA.ID;
-- 查看视图
select * from te2;
-- 向 t_address添加数据 (9,'龙旗2区',1,1) 查看是否同步数据
insert into t_address values(9,'龙旗2区',1,1);
commit;
-- 查看视图
select * from te2;-- todo 3 创建不生成数据的物化视图 bulid deferred(延时生成数据)
-- 需求:查询地址 ID,地址名称和所属区域名称 t_address t_area
-- create materialized view 视图名
-- build deferred
-- refresh force on commit
create materialized view test1
build deferred
refresh force on commit
asselect T_ADDRESS.ID, T_ADDRESS.NAME, T_AREA.NAME area
from T_ADDRESSinner join T_AREA on T_ADDRESS.AREAID = T_AREA.ID;
-- 查看数据
select * from C##WATERUSER.test1;
-- 刷新后生成数据
beginDBMS_MVIEW.REFRESH('test1');
end;
2、物化视图----增量手动更新
-- todo 6. 创建增量更新物化视图
-- 需求:查询地址 ID,地址名称和所属区域名称 t_address t_area
-- 注意:
-- 1. 创建增量更新物化视图 所有的源数据表 必须有物化视图日志
-- 2. 创建的增量更新物化视图 中 必须包含 源数据表中的rowid-- 创建物化视图日志
create materialized view log on T_ADDRESS with rowid;
create materialized view log on T_AREA with rowid;
-- 查看t_address的日志 MLOG$_T_ADDRESS
select * from MLOG$_T_ADDRESS;
-- 向t_address表插入数据 (10,'幸福社区',1,1)
delete from T_ADDRESS where id=10;
insert into T_ADDRESS values (10,'幸福社区',1,1);
commit;
-- 查看t_address的日志 MLOG$_T_ADDRESS
select * from MLOG$_T_ADDRESS;
-- 创建增量更新手动刷新表
-- create materialized view test2
-- build immediate
-- refresh fast on demand
-- as
-- select
-- T_ADDRESS.ROWID as addr_rowid,
-- T_AREA.ROWID as area_rowid,
-- T_ADDRESS.ID, T_ADDRESS.NAME, T_AREA.NAME area
-- from T_ADDRESS
-- inner join T_AREA on T_ADDRESS.AREAID = T_AREA.ID;
create materialized view test2
build immediate
refresh fast on demand
as
selectT_ADDRESS.ROWID as addr_rowid,T_AREA.ROWID as area_rowid,T_ADDRESS.ID, T_ADDRESS.NAME, T_AREA.NAME area
from T_ADDRESS
inner join T_AREA on T_ADDRESS.AREAID = T_AREA.ID;
-- 向t_address表中增加数据(11, '德国公馆', 1, 1)
insert into t_address values (11, '德国公馆', 1, 1);
commit;
-- 查看T_ADDRESS表数据
select * from T_ADDRESS;
-- 查看视图数据(非select方式查看)
select * from test2;
-- 手动刷新 begin DBMS_MVIEW.REFRESH('view_test_', METHOD =>'f'); end;
beginDBMS_MVIEW.REFRESH('view_test_11', METHOD =>'f');
end;
3、物化视图----全量自动更新
-- todo 1 需求: 查询地址 ID,地址名称和所属区域名称
-- create materialized 视图名
-- build immediate
-- refresh complete on commit
create materialized view test3
build immediate
refresh complete on commit
as
selectT_ADDRESS.ID, T_ADDRESS.NAME, T_AREA.NAME area
from T_ADDRESS
inner join T_AREA on T_ADDRESS.AREAID = T_AREA.ID;
-- 向t_address表添加数据(12, '德黑兰', 1, 1)
insert into t_address values (12, '德黑兰', 1, 1);
commit;
-- 查询 t_address表 数据
select * from T_ADDRESS;
-- 查询视图
select * from C##WATERUSER.test3;
-- todo 2 删除视图
drop materialized view test3;
-- todo 3 删除视图日志
drop materialized view log on 数据表名;
二、序列
1、序列含义
在 Oracle 中,序列(Sequence)是一种数据库对象,用于生成唯一的数字序列。序列通常用于为表的主键字段或其他需要唯一标识的字段提供自增的值。
2、使用案例
2.1、 创建序列
2.1.1、创建简单序列
CREATE SEQUENCE employee_id_seqSTART WITH 1001INCREMENT BY 1NOCACHENOCYCLE;
employee_id_seq是序列的名称。START WITH 1001指定序列的起始值为 1001。INCREMENT BY 1指定序列每次增加的步长为 1。NOCACHE表示不缓存序列号,每次都从数据库获取。NOCYCLE表示不循环,当达到最大值后不会重新从最小值开始。
创建序列语法:
| create sequence 序列名称 |
通过序列的伪列来访问序列的值
NEXTVAL 返回序列的下一个值
CURRVAL 返回序列的当前值
注意:我们在刚建立序列后,无法提取当前值,只有先提取下一个值时才能再次提取当前值。
提取下一个值
| select 序列名称.nextval from dual |
提取当前值
| select 序列名称.currval from dual |
2.1.2、创建复杂序列:
CREATE SEQUENCE sequence //创建序列名称
[INCREMENT BY n] //递增的序列值是 n 如果 n 是正数就递增,如果是负数就递减 默认是 1
[START WITH n] //开始的值,递增默认是 minvalue 递减是 maxvalue
[{MAXVALUE n | NOMAXVALUE}] //最大值
[{MINVALUE n | NOMINVALUE}] //最小值
[{CYCLE | NOCYCLE}] //CYCLE和NOCYCLE 表示当序列的值达到限制值后是否循环。CYCLE代表循环即到达例如最大值后重新从最小值开始
[{CACHE n | NOCACHE}];//定义存放序列的内存块的大小,默认为20。NOCACHE表示不对序列进行内存缓冲。对序列进行内存缓冲,可以改善序列的性能。
2.2、使用序列
SELECT employee_id_seq.NEXTVAL FROM dual;2.3、序列与表的关联
通常,序列会与表的主键字段关联,以确保每次插入新记录时都能为主键生成唯一的值。例如,假设有一个名为 employees 的表,其中有一个 employee_id 字段作为主键:
CREATE TABLE employees (employee_id NUMBER PRIMARY KEY,first_name VARCHAR2(50),last_name VARCHAR2(50),...
);可以在表创建时指定序列的默认值:
CREATE TABLE employees (employee_id NUMBER DEFAULT employee_id_seq.NEXTVAL PRIMARY KEY,first_name VARCHAR2(50),last_name VARCHAR2(50),...
); 这样,在插入新记录时,如果不提供 employee_id 的值,数据库会自动使用序列来为其生成唯一的值。
2.4、序列的管理
--修改序列
ALTER SEQUENCE employee_id_seq INCREMENT BY 2;--删除数列
DROP SEQUENCE employee_id_seq;三、同义词
1、什么是同义词
同义词实质上是指定方案对象的一个别名。通过屏蔽对象的名称和所有者以 及对分布式数据库的远程对象提供位置透明性,同义词可以提供一定程度的安全性。同时,同义词的易用性较好,降低了数据库用户的 SQL 语句复杂度。
同义词允许基对象重命名或者移动,这时,只需对同义词进行重定义,基于同义词的应用程序可以继续运行而无需修改。你可以创建公共同义词和私有同义词。其中,公共同义词属于 PUBLIC 特殊 用户组,数据库的所有用户都能访问;而私有同义词包含在特定用户的方案中,只允许特定用户或者有基对象访问权限的用户进行访问。
同义词本身不涉及安全,当你赋予一个同义词对象权限时,你实质上是在给同义词的基对象赋予权限,同义词只是基对象的一个别名。
2、创建与使用同义词
创建同义词的具体语法是:
create [public] SYNONYM synooym for object;其中 synonym 表示要创建的同义词的名称,object 表示表,视图,序列等我们要创建同义词的对象的名称。
3、同义词使用案例
3.1、私有同义词
需求:为表 T_OWNERS 创建( 私有 )同义词 名称为 OWNERS
语句:
create synonym owners for t_owners;使用同义词:
select * from owners;3.3、公有同义词
需求:为表 T_OWNERS 创建( 公有 )同义词 名称为 OWNERS2:
create public synonym owners2 for t_owners;以另外的用户登陆,也可以使用公有同义词:
select * from owners2;案例
-- 1 需求:为表 T_AREA 创建( 私有 )同义词 名称为 AREA
-- 2 需求:为表 T_AREA 创建( 共有 )同义词 名称为 AREA2
-- 3 验证 其他用户
实现
-- 1 需求:为表 T_AREA 创建( 私有 )同义词 名称为 AREA
create synonym area for t_area;
select * from area;-- 2 需求:为表 T_AREA 创建( 共有 )同义词 名称为 AREA2
create public synonym area2 for t_area;-- 3 验证
select * from area2;这篇关于Oracle进阶(2)——物化视图案例延伸以及序列、同义词的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




