本文主要是介绍Python读取influxDB数据库(二)(influxDB2.X版本),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. influxDB连接
首先在浏览器中输入influxDB的IP和端口,然后输入账号密码进入到influxDB数据库来进行数据的相关操作:
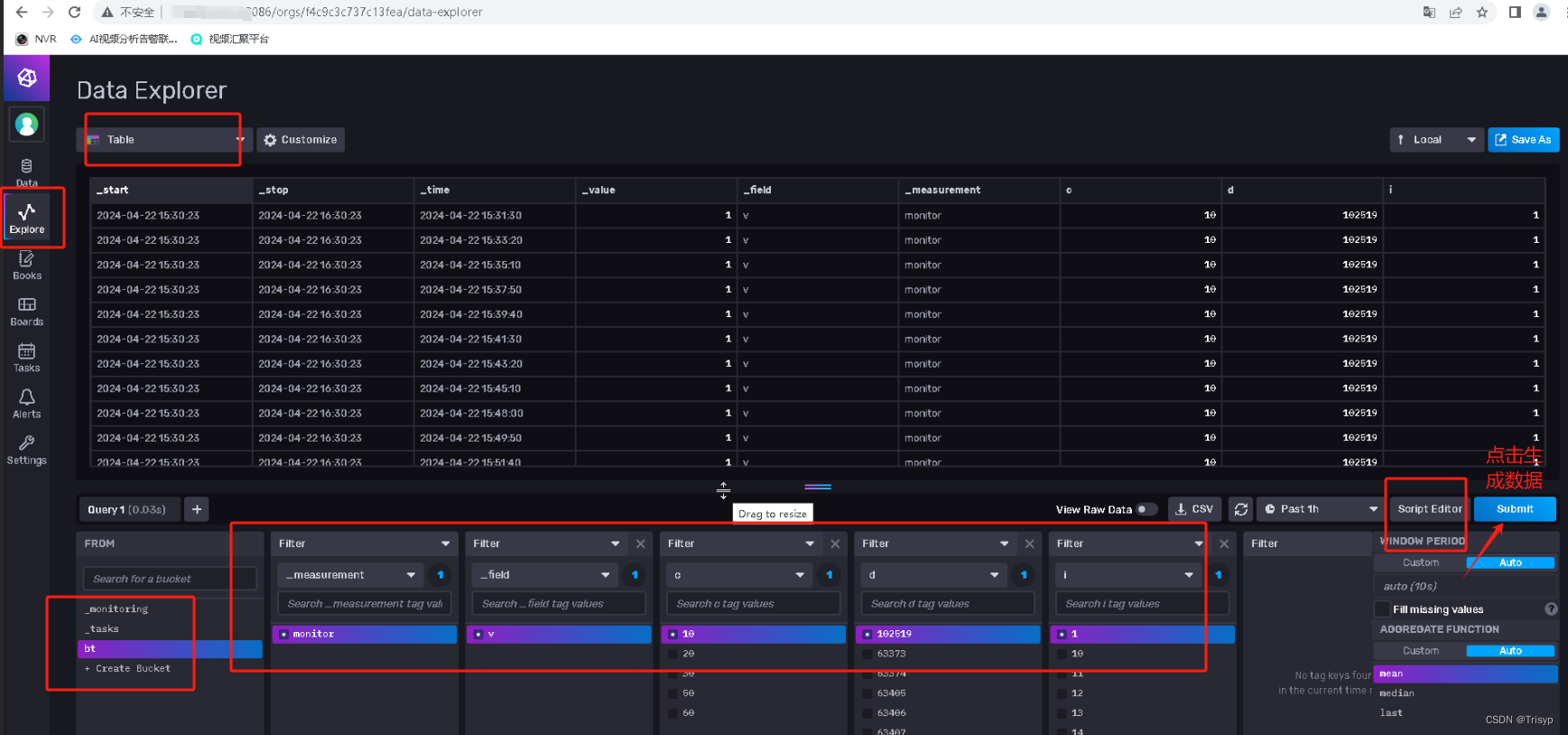
里面的bucket相当于sql中的数据库,_measurement相当于sql中的表
2. 获取influxDB数据库的token方法
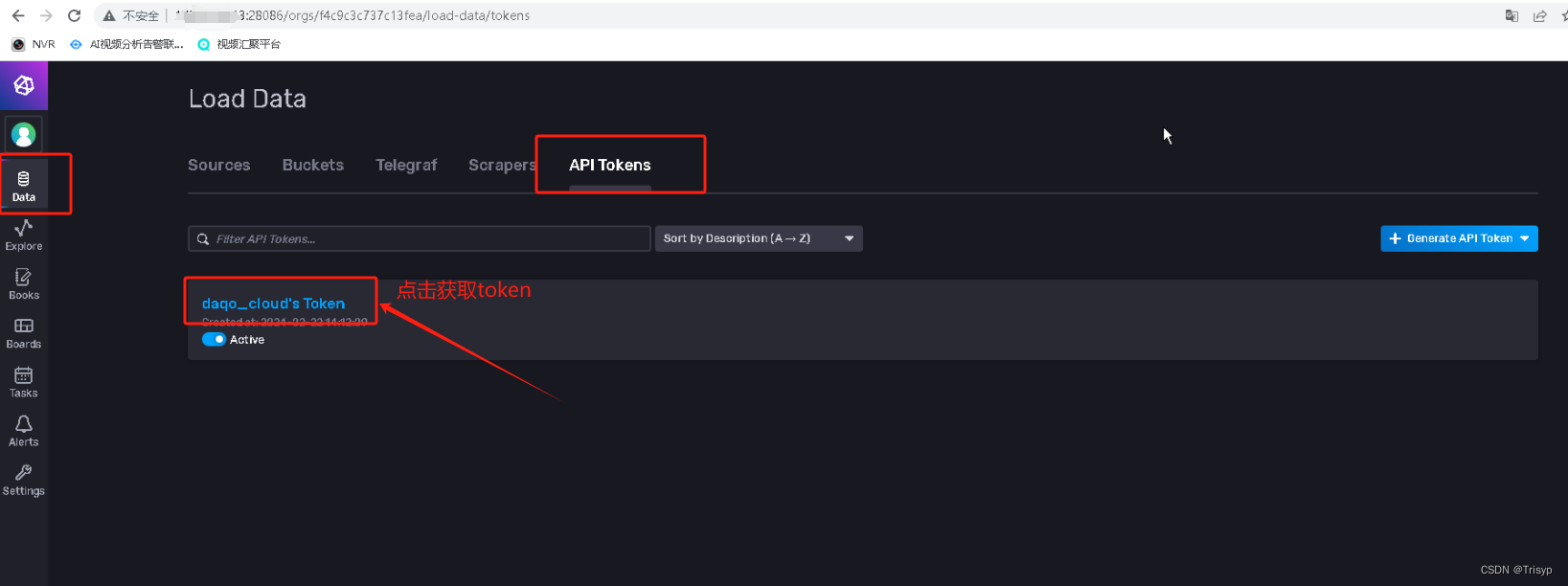
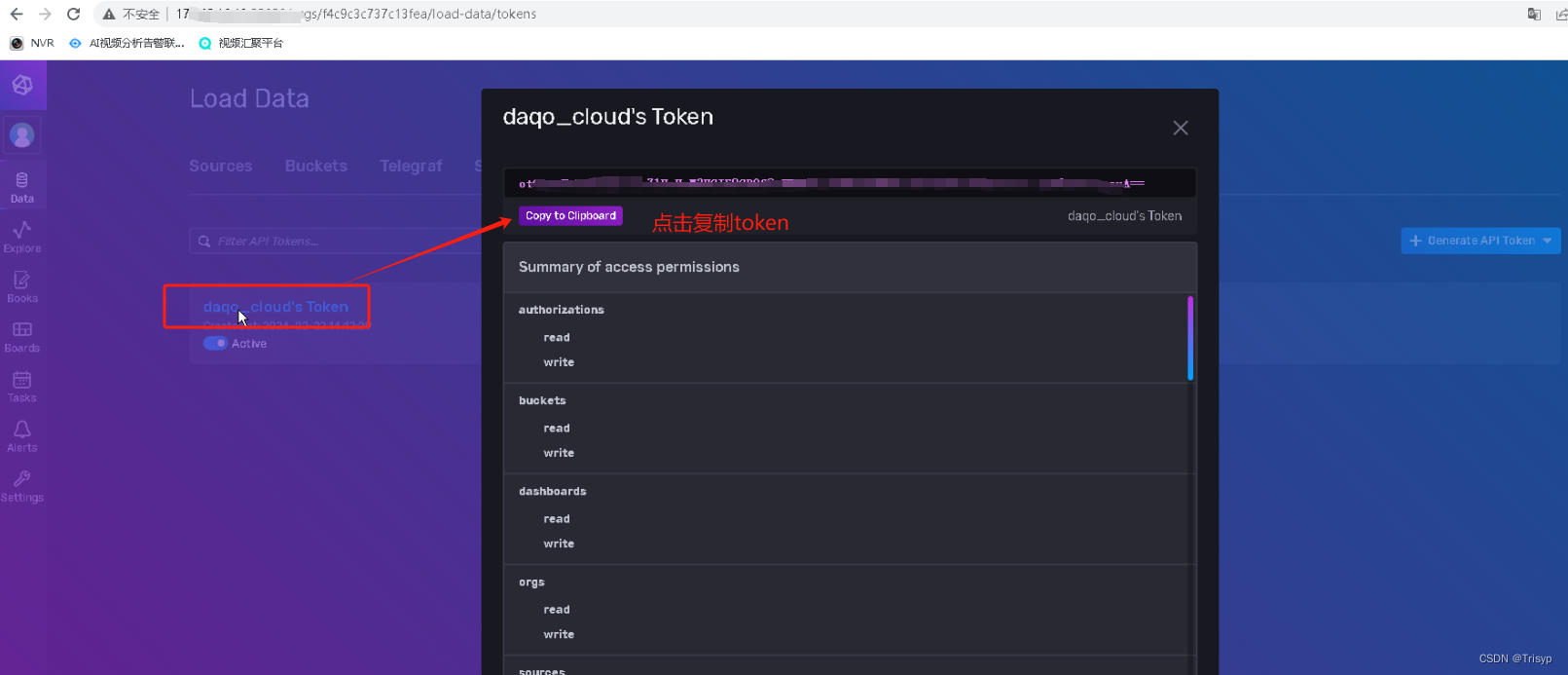
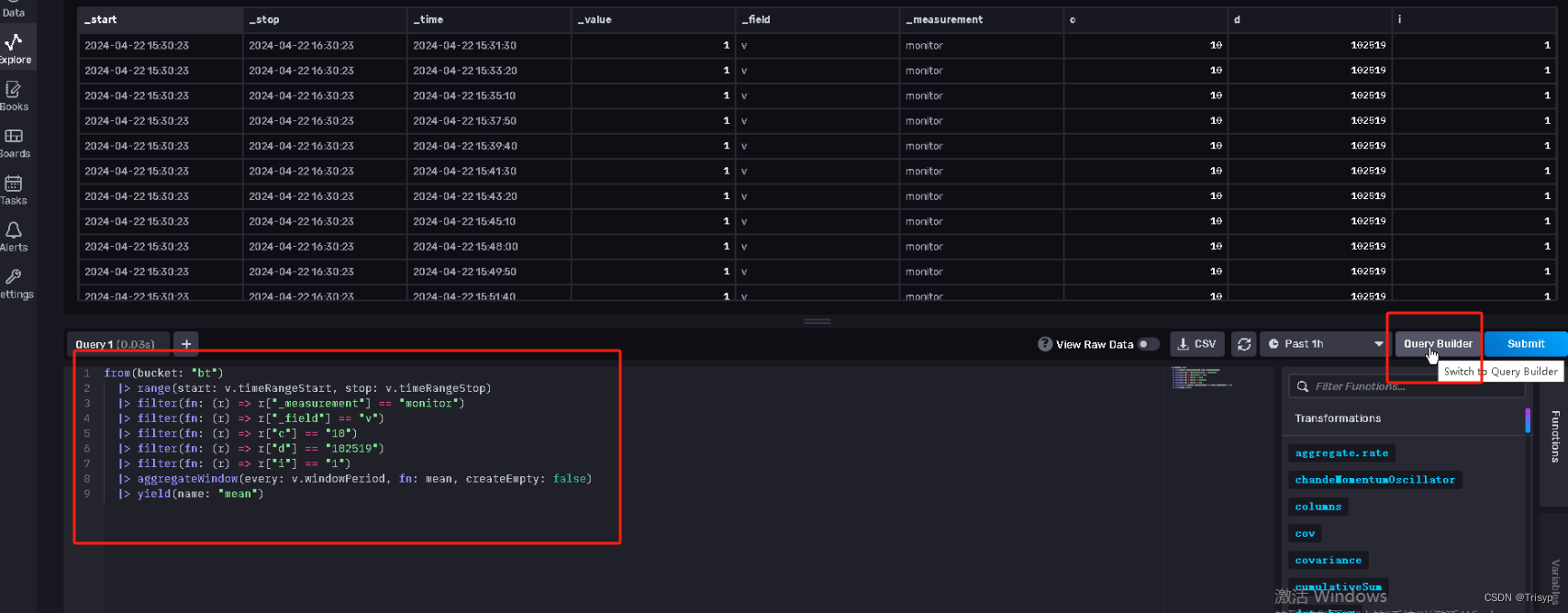
3. 写查询语句来查询数据
然后和平时写sql查询语句一样,先创建连接client,然后调用其query函数来查询获取数据
from (bucket: "bt")
|> range(start: 2024-04-01T15:16:21Z, stop: 2024-04-02T15:16:21Z)
|> filter(fn: (r) => r["_measurement"] == "monitor")
|> filter(fn: (r) => r["d"] == "102519")
|> filter(fn: (r) => r["c"] == "10")
|> filter(fn: (r) => r["i"] == "1")
4. 完整代码(code)
import yaml
from params import pool_num
import os
import time
from pathlib import Path
import influxdb_client
from params import influx_host, influx_port
import pandas as pdfrom utils.logger import Logos_file_name = Path(__file__).nameclass InfluxInfo(object):def __init__(self):passdef influx_conn(self): # 读取的influxdb库地址url = "http://" + influx_host + ":" + str(influx_port) # 安装时的配置参数中查找org = "test_org" # 安装时的配置参数中查找token = "my_token" # 获取方式见图片self.client = influxdb_client.InfluxDBClient(url=url, token=token, org=org)def query_data(self, table_name, expression, begin_time, end_time):self.influx_conn()query_api = self.client.query_api()bucket = "bt"dev, cg, id = expression.split("_")query_sql = f"""from (bucket: "{bucket}") \|> range(start: {begin_time}, stop: {end_time}) \|> filter(fn: (r) => r["_measurement"] == "{table_name}") \|> filter(fn: (r) => r["d"] == "{dev}") \|> filter(fn: (r) => r["c"] == "{cg}") \|> filter(fn: (r) => r["i"] == "{id}")"""tables = query_api.query(query=query_sql)# data_csv = query_api.query_csv(query=query_sql)self.client.close()returndata = pd.DataFrame()if len(tables) > 0:table = tables[0]records = table.recordsif len(records) > 0:timelist = [] #expression_list = []dev_list = []cg_list = []id_list = []valuelist = []for record in records:r = record.valuestimestr = r['_time'].strftime("%Y-%m-%d %H:%M:%S")timelist.append(timestr)dev_list.append(r['d'])cg_list.append(r['c'])id_list.append(r['i'])expression_list.append("_".join([r['d'], r['c'], r['i']]))valuelist.append(r['_value'])if len(timelist) > 0:returndata = pd.DataFrame({'time': timelist, 'expression': expression_list, 'dev': dev_list,'cg': cg_list, 'id': id_list, 'value': valuelist})return returndataif __name__ == '__main__':begin_time = '2024-04-01T15:16:21Z'end_time = '2024-04-02T15:16:21Z'expression = "102519_10_1"query_rslt = InfluxInfo().query_data("monitor", expression, begin_time, end_time)
这篇关于Python读取influxDB数据库(二)(influxDB2.X版本)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






