本文主要是介绍mysql基础24——充分利用系统资源,优化系统配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
性能瓶颈
1)磁盘读写需要计算位置 发出读写指令等,要消耗cpu资源 成为提升性能的瓶颈
2)若先把数据放在内存 后集中写入磁盘 会存在系统故障时,数据丢失的风险
3)若每次都直接写入磁盘 导致效率低下
系统的参数决定着资源的配置方式和投放的程度
调整系统参数缓解性能瓶颈
InnoDB_flush_log_at_trx_commit InnoDB_buffer_pool_size InnoDB_buffer_pool_instances
InnoDB_flush_log_at_trx_commit
该参数适合于InnoDB存储引擎 存储在my.ini文件中 默认值是1 就是每次提交事务的时候把数据写入日志 并把日志写入磁盘 这样的数据安全性最佳 但是每次提交事务时都要进行磁盘的读写,在大并发下 读写过于频繁,浪费cpu资源 系统效率降低
该参数可选0 1 2
0表示 每隔1秒将数据写入日志 并把日志写入磁盘
2表示 每次提交事务的时候把数据写入日志 但日志每隔1秒写入磁盘
将该参数改为2 在大并发系统下 改善系统的效率 降低CPU使用率
InnoDB_buffer_pool_size
该参数表示InnoDB存储引擎使用缓存来存储索引和数据 该值越大表示可以加载到缓冲区的索引和数据量越多 磁盘读写就少 将参数调整为适当的大 充分利用内存 释放一些cpu资源
InnoDB_buffer_pool_instances
该参数表示将InnoDB的缓存区分为几个部分,提高系统的并行处理能力 可以允许多个进程同时处理不同部分的缓存区 把该值修改为64 代表分成64个分区 提高CPU效率
遇到cpu资源不足的问题 从2个思路出发
1)疏通拥堵路段 消除瓶颈 让等待时间更短
2)开拓新通道 增加并行处理的能力
利用系统资源诊断问题
performance schema 工具 监控服务器执行情况的存储引擎
performance schema中的表setup_instruments和setup_consumers中的数据是启用监控的关键
setup_instruments保存的数据表示哪些对象发生的事件可以被系统捕获(在mysql中,这些事件称作信息生产者)
name 事件名称 enabled 是否启用了对这个事件的监控 timed 是否收集事件的时间信息
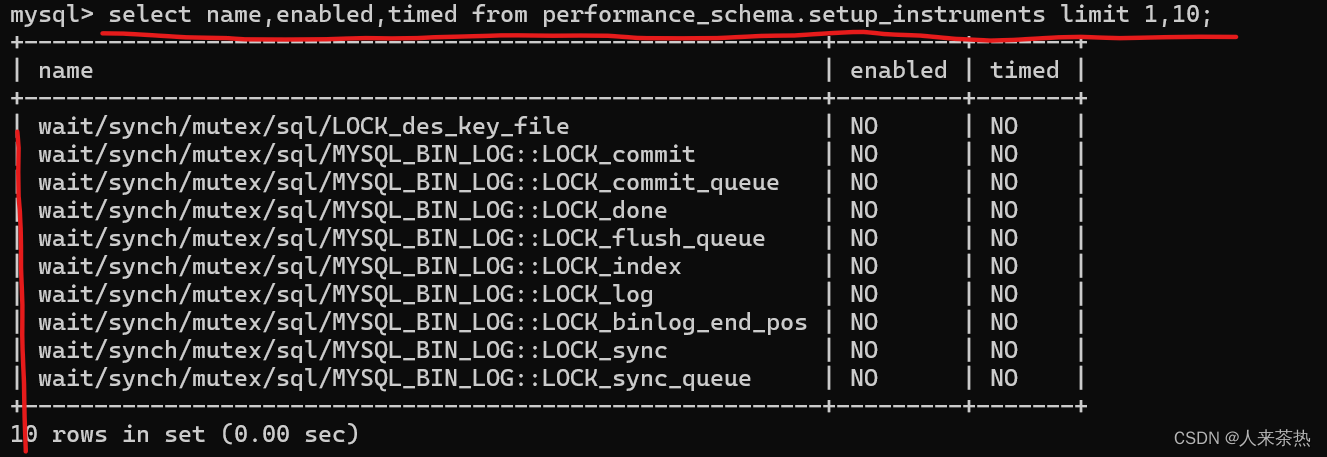
启用所有事件的监控
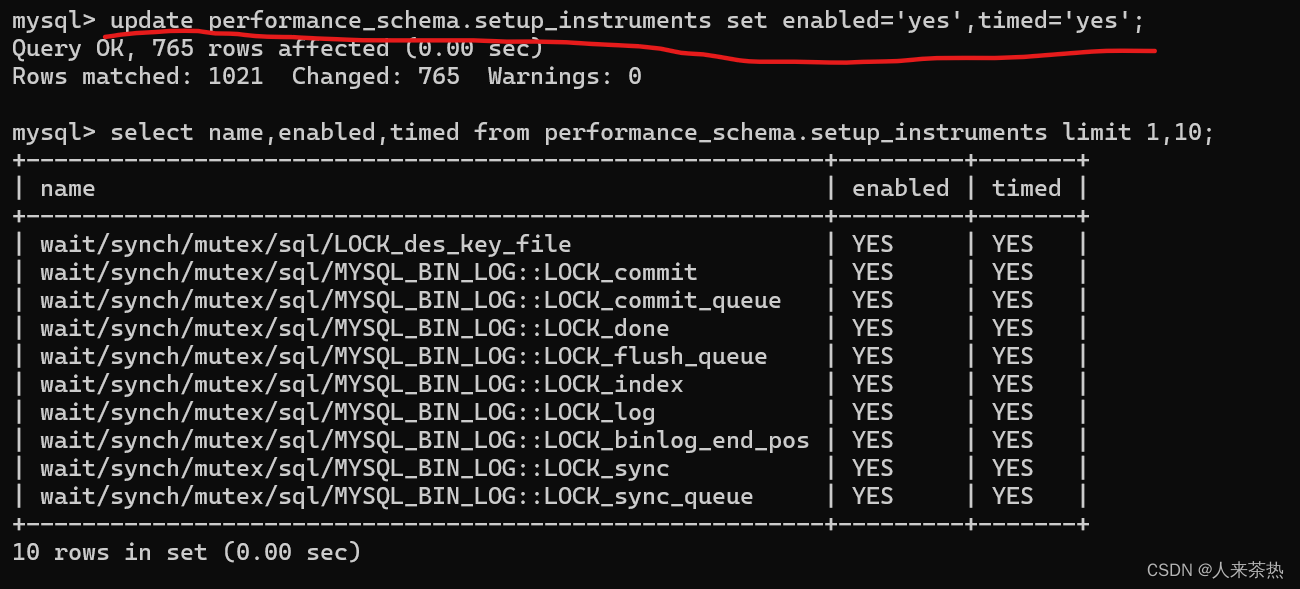
setup_consumers保存的数据表示是否保存监控事件发生的信息
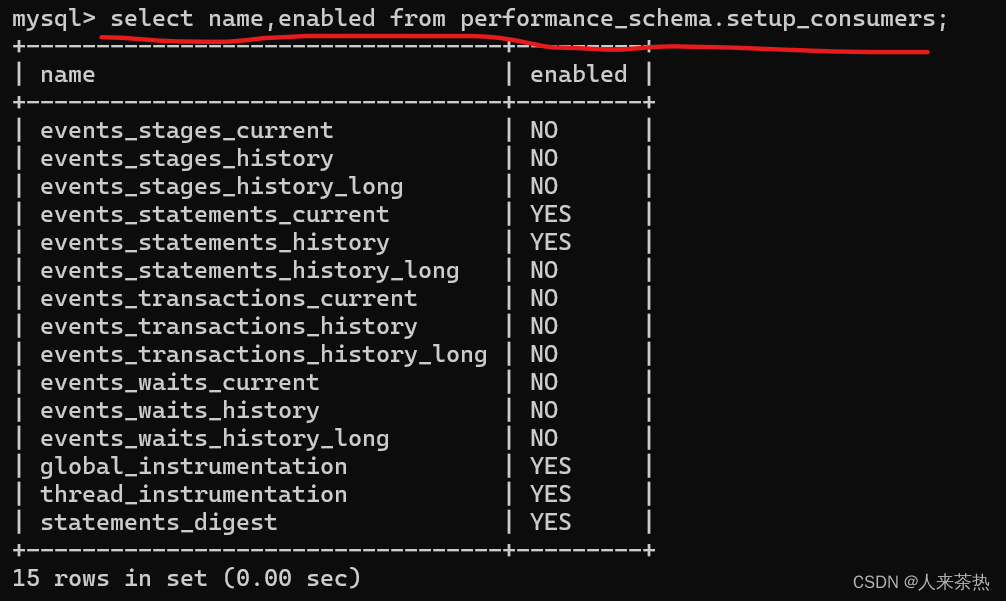
使系统保存全部事件信息
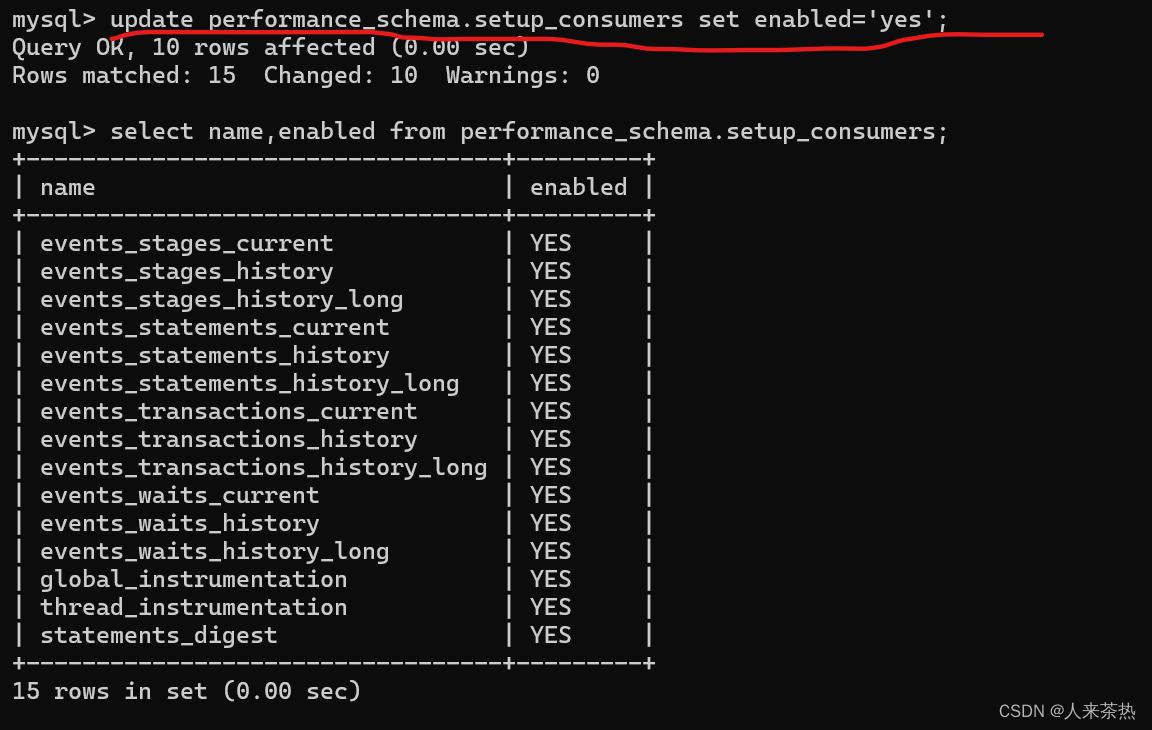
利用以上监控信息诊断问题
数据表performance schema.events_statements_current 记录当前系统中的查询事件 每一行对应一个进程 ,一个进程只有1行数据 显示的是每个进程中被监控到的查询事件
数据表performance schema.events_statements_history 记录的是当前系统中所有进程中最近发生的查询事件 包含的查询事件都是已经完成了的 表中每个进程保存的最大记录数由系统变量决定
查询当前系统中可以为每个进程保存的最大记录数的值 10

数据表performance schema.events_statements_history_long 记录的是系统中所有进程中最近发生的查询事件 包含的查询事件都是已经完成了的 表中保存的记录数由系统变量决定
查询当前系统中该表可以保存的最大记录数的值 10000

根据以上信息发现是哪些查询消耗了最多的cpu资源 针对性地优化
若遇到无法控制cpu使用率导致系统崩溃首先想到是应用本身存在问题
这篇关于mysql基础24——充分利用系统资源,优化系统配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







