本文主要是介绍动态渲染页面的爬取(项目案例:爬取今日头条热点新闻),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:本文内容来自 张涛的《从零开始学Scrapy网络爬虫》
- 在使用Selenium的过程中,我们驱动的都是Chrome、FireFox等有界面的浏览器,效率极低。对爬虫来说,只要能高效地获取数据,有无界面根本无关紧要,因此本项目选择使用无界面的浏览器PhantomJS。
1.准备工作
- 项目开始强,要保证必要的环境已经成功搭建。主要有Selenium和PhantomJS。
- (1)使用pip安装Selenium。
pip install selenium
- (2)下载PhantomJS驱动并配置环境。

2.创建Scrapy项目
- 创建一个名为toutiao的scrapy项目。
scrapy startproject toutiao
3.使用Item封装数据
- 打开项目toutiao中的items.py源文件,添加新闻字段,实现代码如下:
import scrapyclass ToutiaoItem(scrapy.Item):title = scrapy.Field() # 标题source = scrapy.Field() # 来源comment = scrapy.Field() # 评论数
4.创建Spider源文件及Spider类
- 在Spider文件夹中新建toutiao_spier.py文件。在toutiao_spider.py中创建爬虫类ToutiaoSpider,实现代码如下:
from scrapy import Request
import sys
sys.path.append('D:\\pythonProject\\scrapy\\toutiao')
from scrapy.spiders import Spiderfrom toutiao.items import ToutiaoItem # 导入Item模块
from selenium import webdriver # 导入浏览器引擎模块class ToutiaoSpider(Spider):# 定义爬虫名称name = 'toutiao'# 构造函数def __init__(self):# 生成PhantomJS的对象driverself.driver = webdriver.PhantomJS()# 获取初始的Requestdef start_requests(self):url = "https://www.toutiao.com/?channel=hot&source=ch" # 生成请求对象,设置urlyield Request(url)# 数据解析方法def parse(self,response):pass- 首先,导入必要的模块;接着,定义ToutiaoSpider类,类中定义了3个方法:
- (1)init():构建函数 中生成了phantomjs的对象driver。
- (2)start_requests():生成初始Request对象,虽然会被拦截,还是需要这一步。
- (3)parse():数据解析功能暂不实现。
5.实现下载器中间件
- 在新建项目时,自动生成了一个middlewares.py的源文件,叫做中间件。中间件包含爬虫中间件和下载器中间件,分别对应源文件中ToutiaoSpiderMiddleware 类 和 ToutiaoDownloaderMiddleware 类。下面就在ToutiaoDownloaderMiddleware类中实现使用Selenium请求和下载页面。
- 以下为ToutiaoDownloaderMiddleware类实现的代码:
import time # 时间模块
from scrapy.http import HtmlResponse # html响应模块
from selenium.webdriver.common.by import By # By模块
from selenium.webdriver.support.wait import WebDriverWait # 等待模块
from selenium.webdriver.support import expected_conditions as EC # 预期条件模块# 异常模块
from selenium.common.exceptions import TimeoutException,NoSuchElementException
class ToutiaoDownloaderMiddleware(object):def process_request(self,request,spider):# 判断name是toutiao的爬虫if spider.name == "toutiao":# 打开URL对应的页面spider.driver.get(request.url)try:# 设置显式等待,最长等待5秒wait = WebDriverWait(spider.driver,5)# 等待新闻列表容器加载完成wait.until(EC.presence_of_element_located((By.XPATH,"//div[@class='wcommonFeed']")))# 使用JS的scrollTo方法实现将页面向下滚动到中间spider.driver.execute_script('window.scrollTo(0,document.body.scrollHeight/2)')for i in range(10):time.sleep(5)# 使用JS的scrollTo方法将页面滚动到最底端spider.driver.execute_script('window.scrollTo(0,document.body.scrollHeignt)')# 获取加载完成的页面源代码origin_code = spider.driver.page_source# 将源代码构造成一个Response对象并返回res = HtmlResponse(url=request.url,encodings="utf8",body=origin_code,request=request)return resexcept TimeoutException: # 超时print("time out")except NoSuchElementException: # 无此元素print("no such element")return None
- 首先导入必要的模块,有时间模块、响应模块、By模块、等待模块、预期条件模块和异常模块。
- ToutiaoDownloaderMiddleware 类中的process_request(self,request,spider)方法专门用于处理从爬虫发送过来的HTTP请求,共有两个参数:参数request传递HTTP请求对象;参数spider传递爬虫对象(一个项目可以有多个爬虫)。所有的功能都是在该方法中实现。
- 在方法process_request()中,首先,通过spider.name == toutiao来确定要处理的请求是从名为toutiao的爬虫处传递的;然后,通过driver的get()方法实现使用Selenium获取指定的URL页面,并通过WebDriverWait()方法设置最长等待时间,等待新闻列表的div容器加载完成;接着,使用driver的execute_script()方法执行JS命令,将页面滚动到底部,无法加载更多内容);再每隔5秒钟,将页面滚动到最底部(重复10次),这样页面就会不断加载更多新闻内容;最后,通过driver.page_source()方法获取加载完整的页面文档构造一个Response对象,返回给爬虫。
6.开启下载器中间件
- 下载器中间件默认关闭,需要手动开启。在settings.py中将对应的注释放开即可,代码如下:

7.解析数据(我写的是完整代码)
- 下载器中间件构造一个Response对象后,将其发送给ToutiaoSpider爬虫类的parse()方法,实现数据的解析。再回到ToutiaoSpider类,完成parse()方法。parse()方法的实现代码如下:
from scrapy import Request
import sys
sys.path.append('D:\\pythonProject\\scrapy\\toutiao')
from scrapy.spiders import Spiderfrom toutiao.items import ToutiaoItem # 导入Item模块
from selenium import webdriver # 导入浏览器引擎模块class ToutiaoSpider(Spider):# 定义爬虫名称name = 'toutiao'# 构造函数def __init__(self):# 生成PhantomJS的对象driverself.driver = webdriver.PhantomJS()# 获取初始的Requestdef start_requests(self):url = "https://www.toutiao.com/?channel=hot&source=ch" # 生成请求对象,设置urlyield Request(url)# 数据解析方法def parse(self,response):item = ToutiaoItem()list_selector = response.xpath("//div[@class='wcommonFeed']/u1/li")for li in list_selector:try:# 标题title = li.xpath(".//a[@class='link title']/text()").extract()# 去除空格title = title[0].strip(" ")# 来源source = li.xpath(".//a[@class='lbtn source']/text()").extract()# 去除点号和全角空格source = source[0].strip(". ").strip(" ")# 评论数comment = li.xpath(".//a[@class='lbtn comment']/text()")# 去除文字及空格comment = comment.re("(.*?)评论")[0]comment = "".join(comment.split()) # 去除空格: item["title"] = title # 标题item["source"] = source # 来源item["comment"] = comment # 评论数yield itemexcept:continue- 在Chrome浏览器的“开发者工具”中的Element选项卡中,显示的就是加载完全的HTML代码(包括AJAX加载的数据),如下图所示。通过对HTML代码的分析,就能很容易地实现数据解析了。
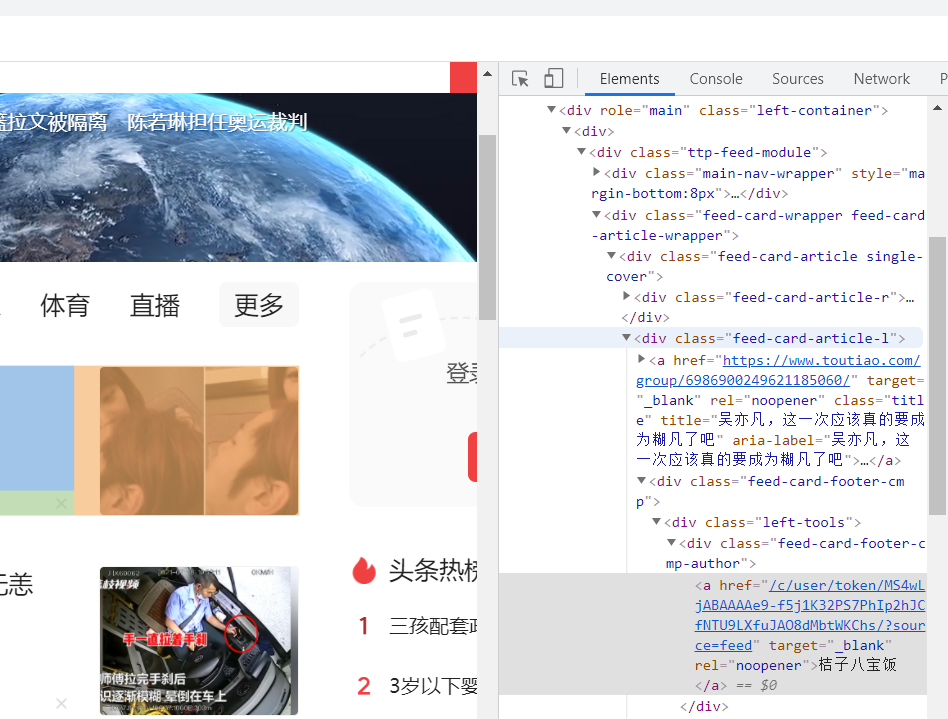
我一直没找到div[@class=‘wcommonFeed’],希望大佬们可以看看,这个属性是在哪里的?
8.运行爬虫
- 通过命令运行爬虫,将数据保存于toutiao.csv文件中。
scrapy crawl toutiao -o toutiao.csv
- 第一次运行,出现以下报错信息

- 解决措施,详见https://blog.csdn.net/u010358168/article/details/79749149

- 再次运行,虽然没有报错,但是得到仍然是空的csv文件,按照书上建议(1)

- 仍然是没有数据结果,希望发现问题所在的大佬解答哈
这篇关于动态渲染页面的爬取(项目案例:爬取今日头条热点新闻)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







