本文主要是介绍超星图书转成PDF格式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转为pdf
为避免浪费您的时间,本篇转载文章不值得花费您的宝贵时间阅读
方法一
感谢@医学插画动画杜鹏 @Roison An两位提供的方法,经试验后简化了一下,得出以下方法:1、使用超星打开你想要转换的图书 2、依次打开本书的所有页面,不要关闭超星(后面图片的清晰度取决于打开超星图书放大的倍数,超星里放大的倍数越大越清晰,但同时文件里的图片也越大,所以超星放大的倍数自行取舍)
2、依次打开本书的所有页面,不要关闭超星(后面图片的清晰度取决于打开超星图书放大的倍数,超星里放大的倍数越大越清晰,但同时文件里的图片也越大,所以超星放大的倍数自行取舍)
 3、打开路径C:\Users\Administrator\AppData\Local\Temp\buffer,“Administrator”为Windows当前用户名,不清楚用户名的打开路径打开路径C:\Users回车就可以看到你的用户名,选择你用户名的文件夹再把后面\AppData\Local\Temp\buffer复制粘贴进去就好了(不打开超星在电脑上是找不到这个路径的,所以一定要先打开超星)
3、打开路径C:\Users\Administrator\AppData\Local\Temp\buffer,“Administrator”为Windows当前用户名,不清楚用户名的打开路径打开路径C:\Users回车就可以看到你的用户名,选择你用户名的文件夹再把后面\AppData\Local\Temp\buffer复制粘贴进去就好了(不打开超星在电脑上是找不到这个路径的,所以一定要先打开超星)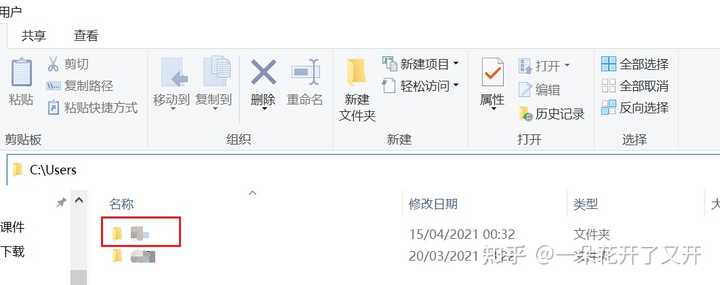
 4、打开路径C:\Users\Administrator\AppData\Local\Temp\buffer后就可以看到整本书的图片版了
4、打开路径C:\Users\Administrator\AppData\Local\Temp\buffer后就可以看到整本书的图片版了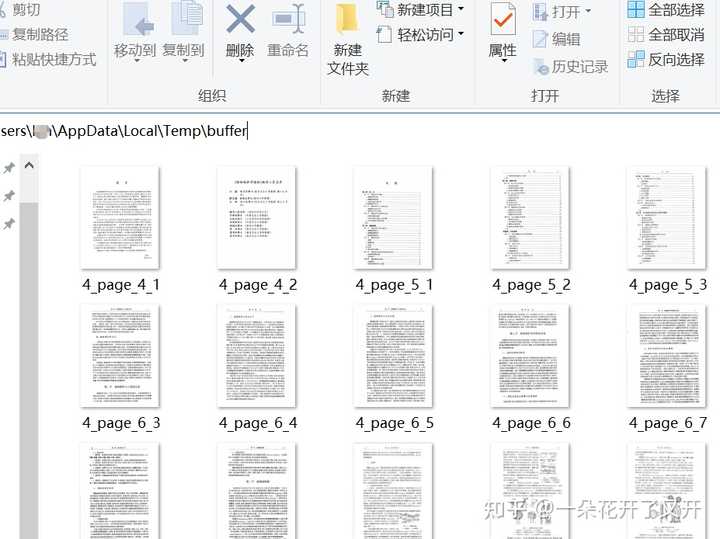 5、ctrl+A全选图片复制到你自己新建的文件夹中(复制保存完文件就可以关闭超星了),再打开你新建的文件夹,全选图片,右击,如果你是WPS会员直接多图片转PDF即可。
5、ctrl+A全选图片复制到你自己新建的文件夹中(复制保存完文件就可以关闭超星了),再打开你新建的文件夹,全选图片,右击,如果你是WPS会员直接多图片转PDF即可。 PS:6、如果你不是WPS会员就找个可以多图片合成PDF的软件或者网站都行,或者用Adobe Acrobat 9 Pro合成(不一定是这个版本),打开Adobe Acrobat 9 Pro,选择文件选项卡→合并→合并文件到单个PDF→将新建文件夹的图片全选拖到合并框里,选择文件大小,点击合并文件,等待文件合成完毕即可。Adobe Acrobat 9 Pro的下载推荐一个公众号,软件安装师,里面可以找到你想要的应用程序,具体安装参考他的说明。
PS:6、如果你不是WPS会员就找个可以多图片合成PDF的软件或者网站都行,或者用Adobe Acrobat 9 Pro合成(不一定是这个版本),打开Adobe Acrobat 9 Pro,选择文件选项卡→合并→合并文件到单个PDF→将新建文件夹的图片全选拖到合并框里,选择文件大小,点击合并文件,等待文件合成完毕即可。Adobe Acrobat 9 Pro的下载推荐一个公众号,软件安装师,里面可以找到你想要的应用程序,具体安装参考他的说明。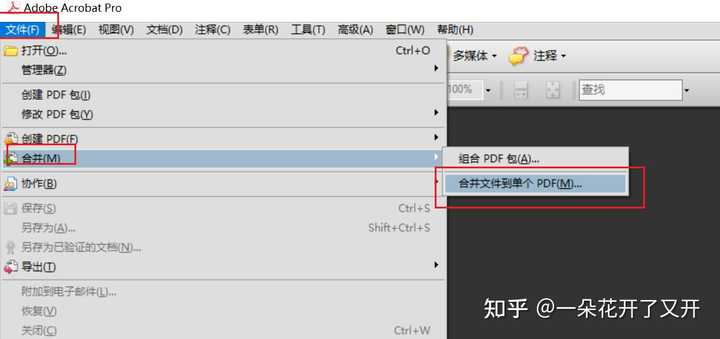
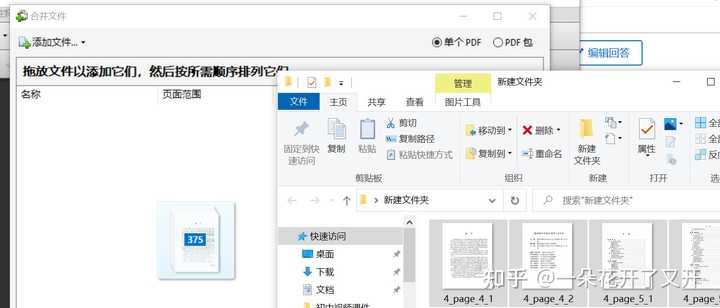
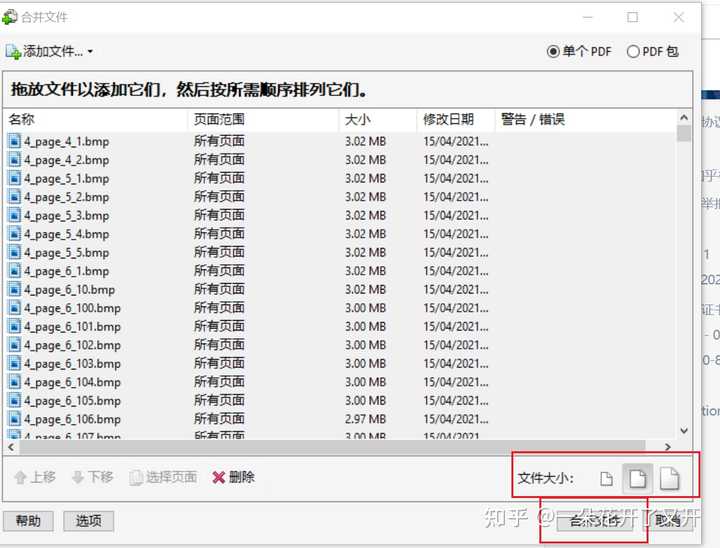
7、使用Adobe Acrobat 9 Pro合并时可能会出现页数乱码的情况,这是因为系统文件名排序默认依据的原因,这时只要选择排序依据为修改日期即可,只要你打开超星图书时是按页码依次打开的就不会乱码了。
方法二
方法二用打印功能:打印成.xps格式,再打印成PDF格式
别问我为什么不直接转成PDF
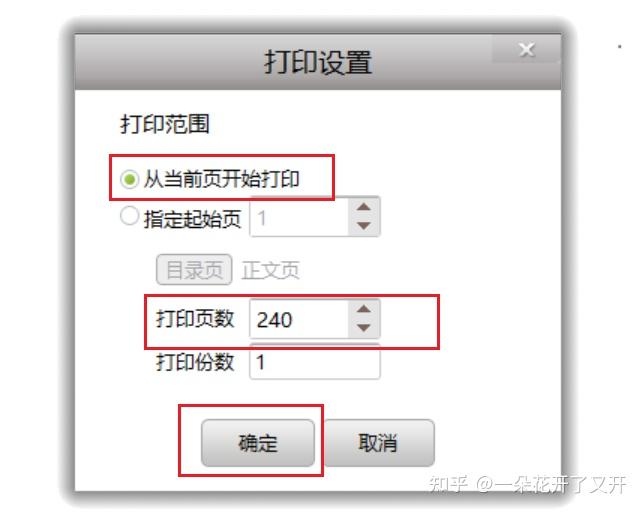
1、设置打印参数:打开超星阅读器,选择你要转成PDF的图书,调到前言第一页,右键选择打印功能,选择从当前页开始打印,设置打印页数=前言页数+目录页数+正文页数,确定。
2、简单操作 随便一页上面,鼠标右键,打印,选择从指定起始页1,打印页数(通过目录跳转到最后一页,查看有多少页) ,点击打印。
 2、选择打印机:选择Microsoft XPS document writer打印机,打印。
2、选择打印机:选择Microsoft XPS document writer打印机,打印。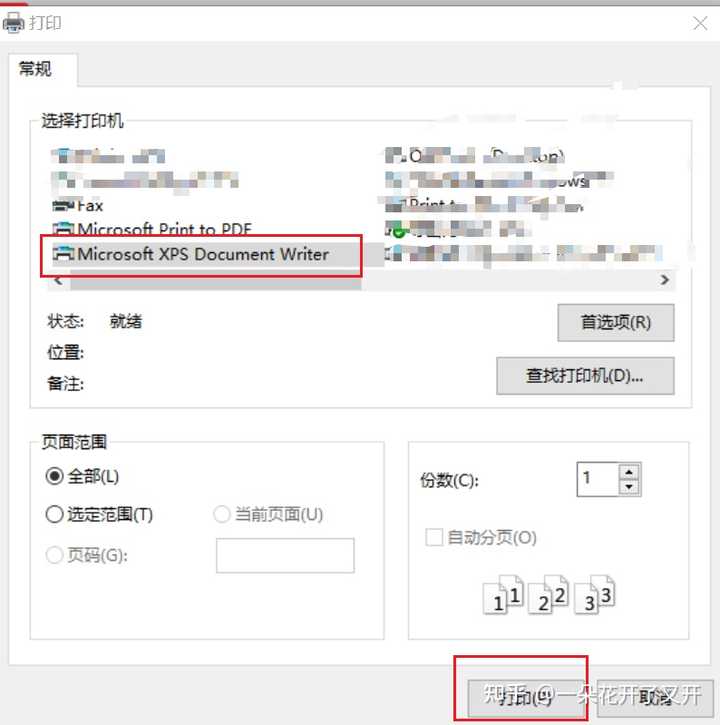 3、设置文件名与保存格式.xps
3、设置文件名与保存格式.xps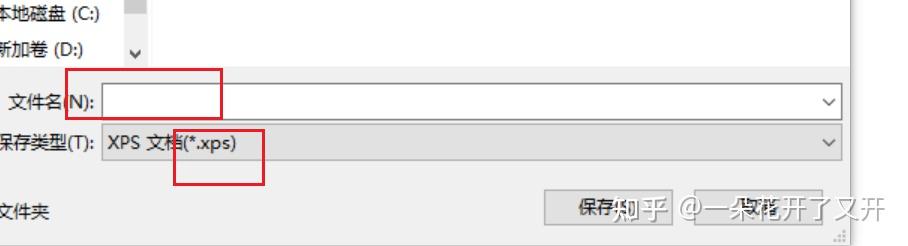 4、打开保存的.xps格式文件,选择打印功能,选择导出为PDF文件,完成。
4、打开保存的.xps格式文件,选择打印功能,选择导出为PDF文件,完成。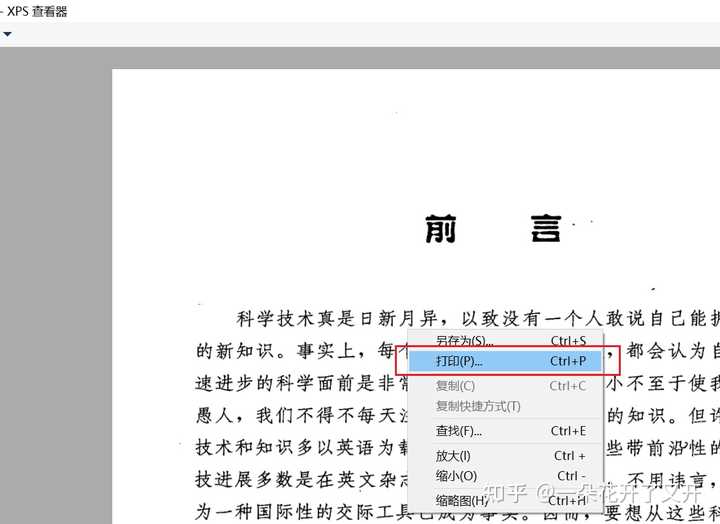
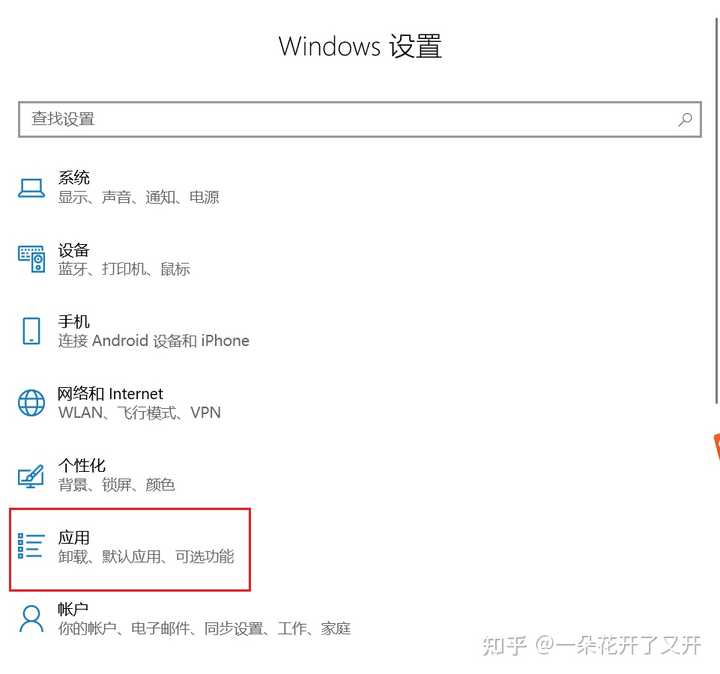
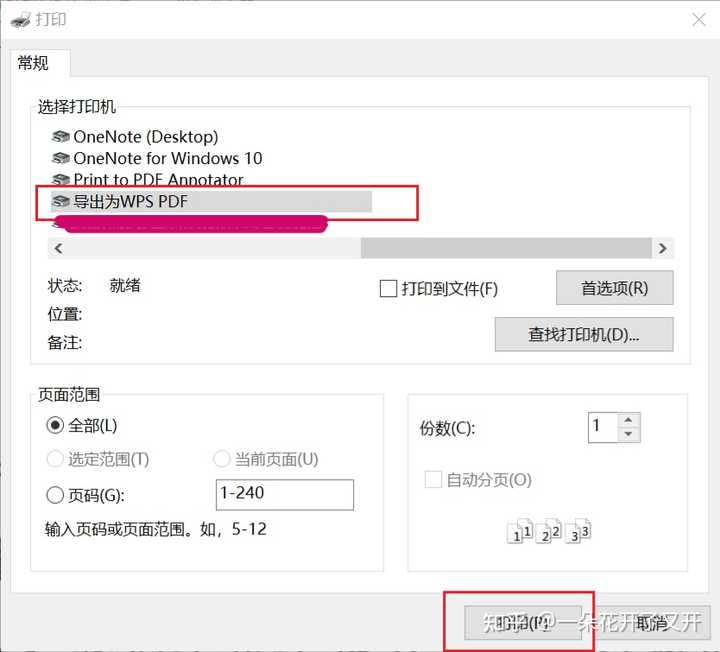 PS:.xps格式文件可用win10内置查看器打开。安装步骤:点击WIN→设置→应用→应用和功能→可选功能→添加可选功能→找到XPS查看器→安装→完成。
PS:.xps格式文件可用win10内置查看器打开。安装步骤:点击WIN→设置→应用→应用和功能→可选功能→添加可选功能→找到XPS查看器→安装→完成。


pdf生成目录
参考文献:PDF 能一键生成书签-PdgCntEditor https://www.jianshu.com/p/9683e7094871
这篇关于超星图书转成PDF格式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





