本文主要是介绍node.js项目中基于mysql利用sequelize-auto对照数据库自动生成相应的models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
node.js项目中利用sequelize-auto对照数据库自动生成相应的models,使用sequelize-auto对照数据库自动生成相应的models减少了对数据库进行增删改查时的sql语句的编写。
以下为sequelize-auto对照数据库自动生成相应的models的步骤(由于我使用的数据库是MySQL,本篇介绍的是基于mysql)
1.创建数据库(推荐使用SQLyog工具来可视化操作数据库,方便好用)
2.创建所需的表
3.若本地没有全局安装过sequelize-auto,则需要安装sequelize-auto(若是全局安装过请跳过此步骤)
全局安装sequelize-auto命令:
打开cmd,输入 npm install -g sequelize-auto
4.使sequelize-auto命令操作数据库:
MSSQL数据库:npm install -g tedious
5.在本地的工作空间中选择需要生成models的项目,shift+右键---》在此处打开窗口命令
在窗口输入命令:
sequelize-auto -h localhost -d login_demo -u root -x root -p 3306 -t user
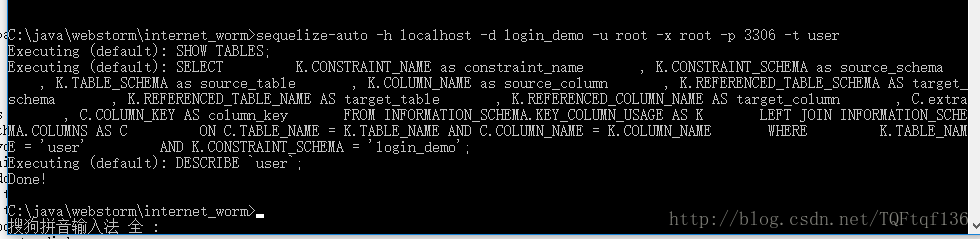
出现如图结果,然后去项目中查看有没有生成名为models目录,里面有没有为user.js文件
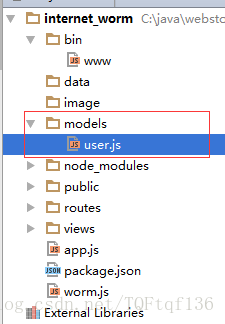
若出现,说明生成成功
6.命令中相关参数介绍:
Options:
-h, --host IP/Hostname for the database. [required]
-d, --database Database name. [required]
-u, --user Username for database.
-x, --pass Password for database.
-p, --port Port number for database.
-c, --config JSON file for Sequelize's constructor "options" flag object as defined here: https://sequelize.readthedocs.org/en/latest/api/sequelize/
-o, --output What directory to place the models.
-e, --dialect The dialect/engine that you're using: postgres, mysql, sqlite
-a, --additional Path to a json file containing model definitions (for all tables) which are to be defined within a model's configuration parameter. For more info: https://sequelize.readthedocs.org/en/latest/docs/models-definition/#configuration
-t, --tables Comma-separated names of tables to import
-T, --skip-tables Comma-separated names of tables to skip
-C, --camel Use camel case to name models and fields
-n, --no-write Prevent writing the models to disk.
-s, --schema Database schema from which to retrieve tables
详情请见官网:https://www.npmjs.com/package/sequelize-auto
这篇关于node.js项目中基于mysql利用sequelize-auto对照数据库自动生成相应的models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






