本文主要是介绍telegraph + influxdb + grafana 实现交换机流量展示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实验环境
influxdb2:2.7.5
telegraf:1.30.1
grafana:10.4.2
influxdb
官方文档见https://docs.influxdata.com/influxdb/v2/,网络上很多文档比较老,可能是v1版本的influxdb。
部署方法1:二进制
从https://www.influxdata.com/downloads/可以查看不同版本的下载地址
下载压缩包并解压、复制二进制文件至默认bin目录下
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.7.6_linux_amd64.tar.gz
tar -zxf influxdb2-2.7.6_linux_amd64.tar.gz
cp influxdb2-2.7.6/usr/bin/influxd /usr/local/bin/
此后就可以通过influxd启动,通过--http-bind-address可以修改端口,通过--reporting-disabled可以不发送telemetry数据,例如:
influxd --http-bind-address=:8089
influxd --reporting-disabled
部署方法2:RPM包部署
按照官网说明下载及安装即可
cat <<EOF | sudo tee /etc/yum.repos.d/influxdata.repo
[influxdata]
name = InfluxData Repository - Stable
baseurl = https://repos.influxdata.com/stable/\$basearch/main
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdata-archive_compat.key
EOF
sudo yum install influxdb2
此后即可通过service或者systemctl操作influxdb,service influxdb start或者systemctl start influxdb
如果想要修改配置,修改配置文件/etc/influxdb/config.toml,例如增加配置如下:
http-bind-address = ":8089"
reporting-disabled = false
测试
启动完成后,可以通过8089端口进行管理,例如http://192.168.101.91:8089/
本次实验中,设置
Username: test
Password: teStUsEr
Organization: test
Bucket: traffic-test
记录下API token,后面telegraf和grafana连接influxdb要用,也可以创建一个All Access API Token。
influxdb启动后,可以参考官方文档的 Get Started ——> Write Data和Query Data进行写入数据和查询数据的测试,按照文档操作即可,唯一要注意的是,官网的样例数据是以秒为单位的,所以load data时精度一定要选择秒,否则数据都会被丢弃
telegraph
安装
配置yum源并安装:
cat <<EOF | sudo tee /etc/yum.repos.d/influxdb.repo
[influxdb]
name = InfluxData Repository - Stable
baseurl = https://repos.influxdata.com/stable/\$basearch/main
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdata-archive_compat.key
EOF
sudo yum install telegraf
配置
默认配置文件位置为/etc/telegraf/telegraf.conf,默认的telegraf是不产生日志的,需要z在telegraf.conf`修改如下配置手工开启:
logtarget = "file"
logfile = "/var/log/telegraf/telegraf.log"
原始配置文件内容极多,可以仅生成需要的配置,例如:
telegraf --input-filter snmp --output-filter file config > test.conf
则只会生成一个输入为snmp,输出为file的配置文件test.conf。可以测试此配置文件是否正确,如果正确则会完成一次采集:
telegraf -config test.conf -input-filter snmp -test
每次修改配置文件后,telegraf都需要重启才能生效。如果使用systemctl启动telegraf,则会应用/etc/telegraf/telegraf.conf和/etc/telegraf/telegraf.d下的所有*.conf配置文件。如果有多个不同的采集任务,可以在一个配置文件中写多个Inputs插件,也可以在/etc/telegraf/telegraf.d下写多个配置文件,但是要注意,telegraf.d目录可以为空,telegraf.conf文件是必需的。
示例
输出
influxdb输出插件配置如下:
[[outputs.influxdb_v2]]urls = ["http://127.0.0.1:8089"]token = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"organization = "test"bucket = "traffic-test"
流量采集(32位计数器版本)
实验示例为采集192.168.101.229、228两台交换机流量,关键配置如下:
[[inputs.snmp]]agents = ["udp://192.168.101.229:161","udp://192.168.101.228:161"]version = 2community = "public"agent_host_tag = "source"fieldpass = ["ifOutOctets", "ifInOctets"][[inputs.snmp.field]]oid = "RFC1213-MIB::sysName.0"name = "sysName"is_tag = true[[inputs.snmp.table]]oid = "IF-MIB::ifTable"name = "traffic"inherit_tags = ["sysName"][[inputs.snmp.table.field]]oid = "IF-MIB::ifDescr"name = "ifDescr"is_tag = true[inputs.snmp.tagpass]ifDescr = ["GigabitEthernet*", "XGigabitEthernet*"]
关键配置说明如下:fieldpass会只保留ifOutOctets和ifInOctets两个字段,即流量计数,过滤掉查看流量所不需要的带宽、错包等其他信息;is_tag表示此字段将会成为一个tag;inherit_tags表示将会继承上层tag,此处即为sysName;tagpass会只保留ifDescrtag值为GigabitEthernet开头或者XGigabitEthernet开头,去掉loopback或者vlanif等其他端口。
流量采集(64位计数器版本)
64位计数器版本配置如下,与32位版本的区别是换了oid和过滤器:
[[inputs.snmp]]agents = ["udp://192.168.101.229:161"]version = 2community = "public"agent_host_tag = "source"fieldpass = ["ifHCOutOctets", "ifHCInOctets"][[inputs.snmp.field]]oid = "RFC1213-MIB::sysName.0"name = "sysName"is_tag = true[[inputs.snmp.table]]oid = "IF-MIB::ifXTable"name = "traffic"inherit_tags = ["sysName"][[inputs.snmp.table.field]]oid = "IF-MIB::ifName"name = "ifName"is_tag = true[[inputs.snmp.table.field]]oid = "IF-MIB::ifAlias"name = "ifAlias"is_tag = true[inputs.snmp.tagpass]ifName = ["GigabitEthernet*", "XGigabitEthernet*"]
示例数据
一条数据示例如下:
traffic,host=net-229,ifDescr=GigabitEthernet0/0/14,ifIndex=19,source=192.168.101.229,sysName=H3C-.S5320-01 ifOutOctets=4189261175i,ifInOctets=3989823012i 1713344116000000000
该数据遵守influxdb的行协议(line protocol):

grafana
启动
可以直接yum安装,也可以下载后手动安装
yum install -y https://dl.grafana.com/oss/release/grafana-10.4.2-1.x86_64.rpm
如果想要修改默认端口号,修改/etc/grafana/grafana.ini 文件中[server]下的http_port项,将
;http_port = 3000
修改为需要的端口号
http_port = 4000
重启服务即可
systemctl restart grafana-server
默认账号密码是admin/admin,但是登录会建议修改。
添加数据源
Connections—>Addd new connection,选择 InfluxDB
Query language 选择 Flux,填好URL、Organization、Token、Default Bucket,点击Save & test,即可。
添加可视化
Query需要填写Flux语言的查询语句。
由于通过snmp协议获取值仅为当前流量计数器的总值,获取流量还需要通过计数器差值并计算速率,需要用到derivative()函数。
示例代码(32位计数器版本)如下:
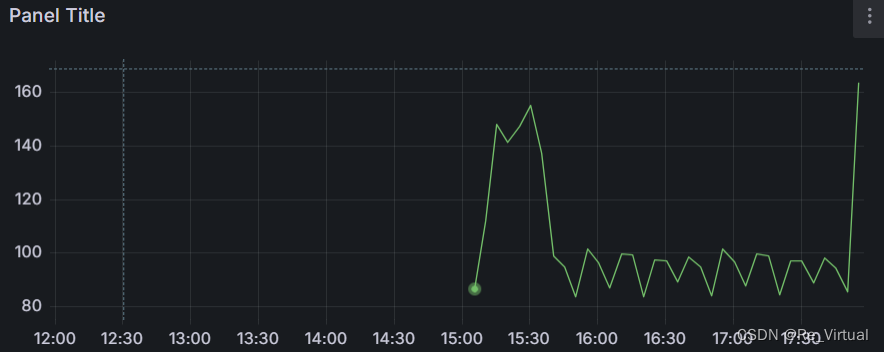
from(bucket: "traffic-test")|> range(start: -3h)|> filter(fn: (r) => r["_measurement"] == "traffic")|> filter(fn: (r) => r["_field"] == "ifInOctets")|> filter(fn: (r) => r["source"] == "192.168.101.229")|> filter(fn: (r) => r["ifDescr"] == "GigabitEthernet0/0/10")|> derivative(unit: 1s)
即可显示图形
这篇关于telegraph + influxdb + grafana 实现交换机流量展示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






