本文主要是介绍Python获取上市公司报告,AI分析助力投资决策,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
折腾了几天,通过从巨潮信息网上获取上市公司的报告,然后实现调用大语言模型的API去分析报告内容,下面把相应的代码和过程分享给对这个感兴趣的兄弟姐妹们,希望能帮到大家。
1,首先去巨潮信息网首页,右上角有个查询,输入相应的关键字就能获取上市公司的公告,比如我这里输入“变更会计师事务所
 可以看到下面的内容
可以看到下面的内容
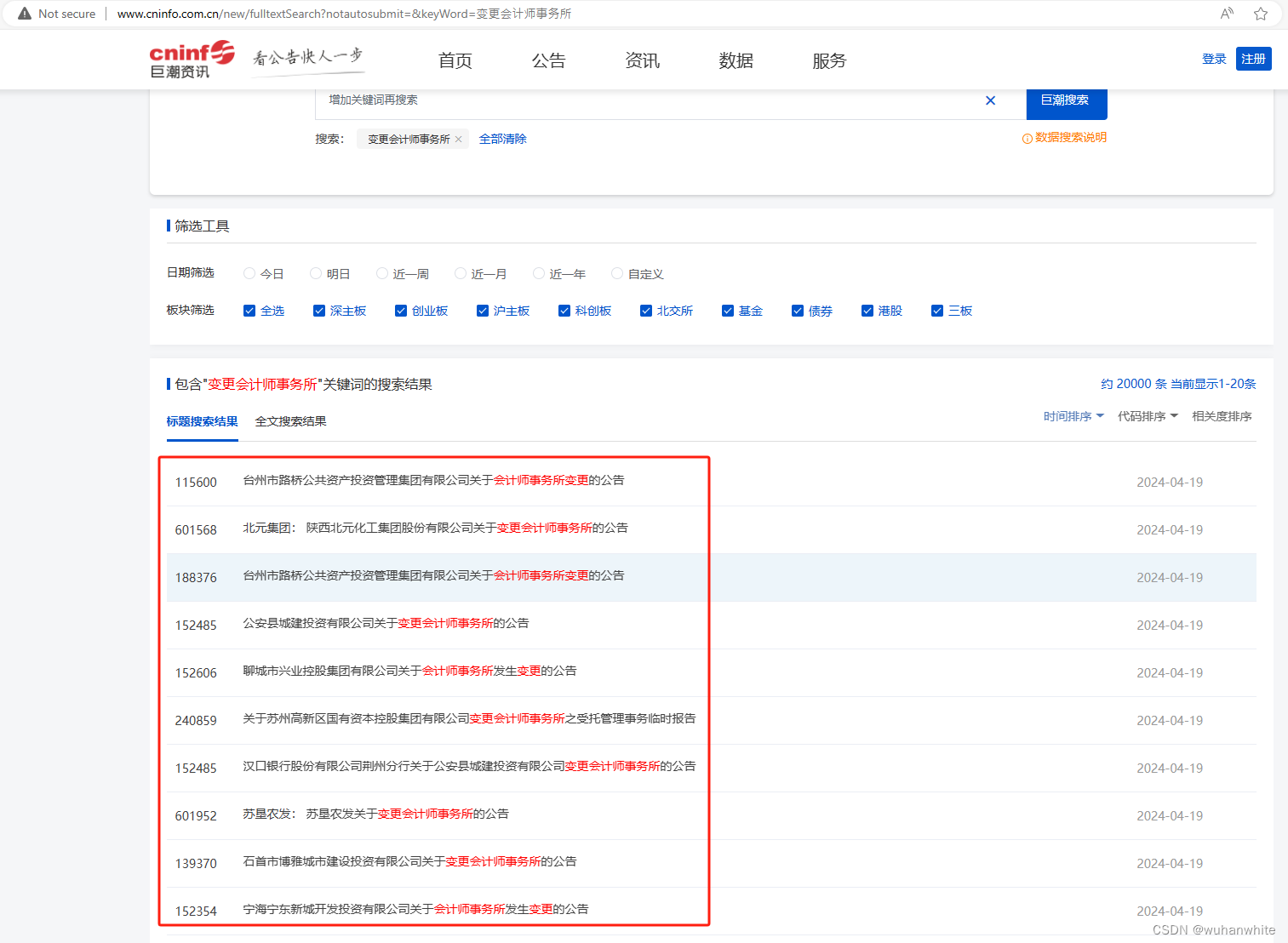
这些链接打开后,就是一个个的pdf报告
如何批量下载这些报告呢,可以用python去实现,
可以先找到这个pdf文件的data-id值,
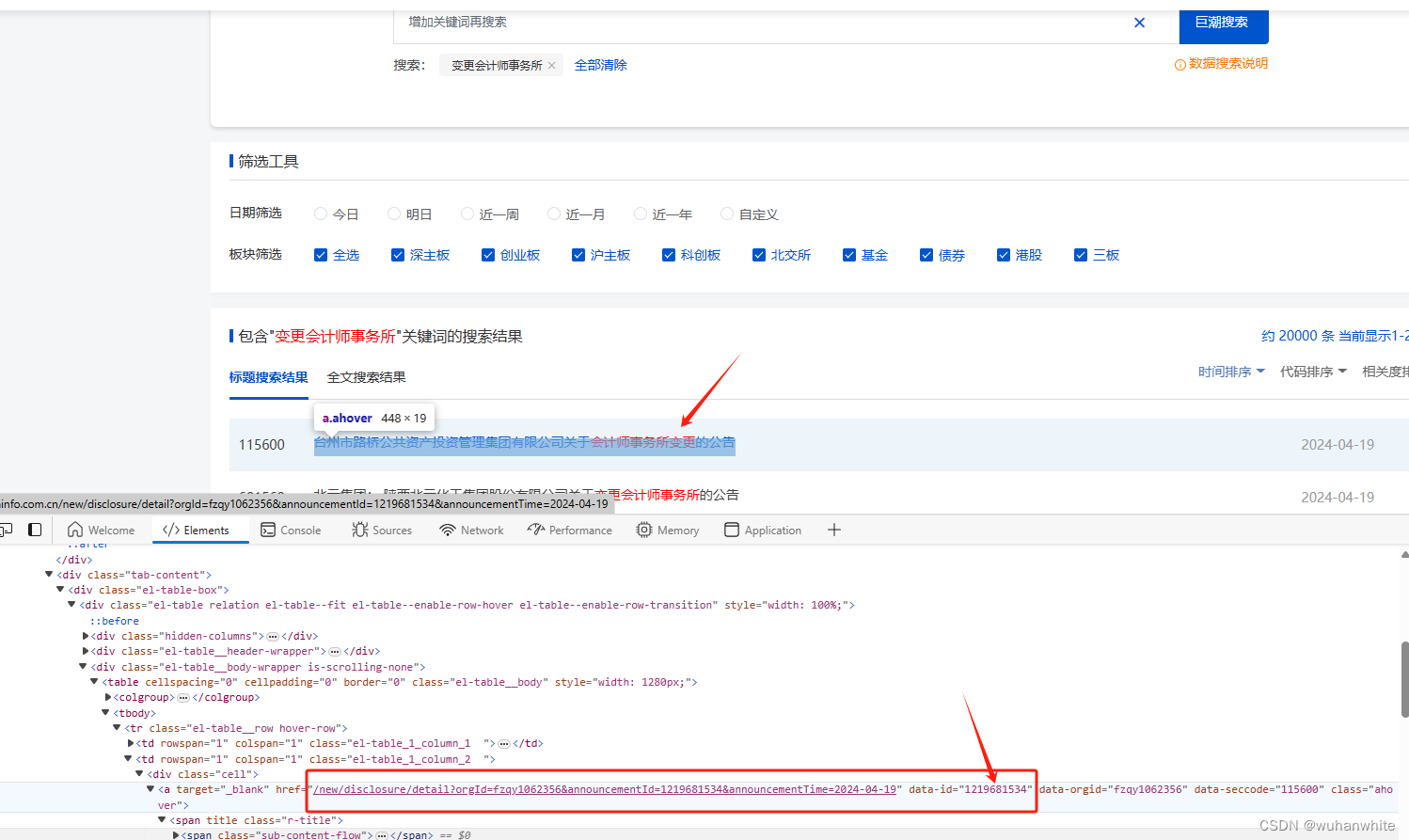
然后在idm下载地址中发现下载地址都是下面的格式,最后就是data-id加pdf命名
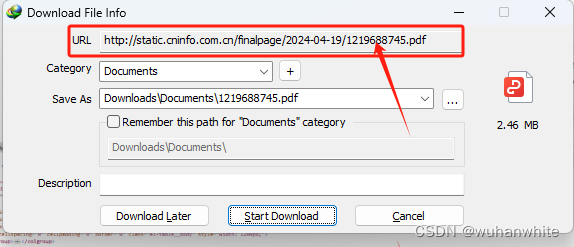
找到这个规律后,写出python代码如下:
import os
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from bs4 import BeautifulSoup
import timefrom selenium.webdriver.chrome.options import Options # 导入Options类def download_pdfs_after_n_pages(start_click, max_clicks, url, save_dir, temp_dir):# 设置Selenium选项,以无头模式运行Chromeoptions = Options()options.headless = Trueoptions.add_argument("--window-size=1920,1080")# 创建WebDriver实例driver = webdriver.Chrome(options=options)# 打开网页driver.get(url)# 用于存储所有页面的链接all_links = []# 设置翻页计数器click_counter = 0# 循环直到达到最大翻页次数while click_counter < max_clicks:# 如果当前点击次数大于或等于指定的开始点击次数,则开始收集链接if click_counter >= start_click:soup = BeautifulSoup(driver.page_source, 'html.parser')a_tags = soup.select("#fulltext-search > div:nth-child(2) > div > div > div:nth-child(3) > div.tab-content > div.el-table-box > div > div.el-table__body-wrapper.is-scrolling-none > table > tbody > tr > td.el-table_1_column_2 > div > a")for a in a_tags:href_parts = a['href'].split('&')announcement_id = href_parts[1].split('=')[1]announcement_time = href_parts[2].split('=')[1]pdf_url = f"http://static.cninfo.com.cn/finalpage/{announcement_time}/{announcement_id}.PDF"sec_name_span = a.select_one("span > span > span.secNameSuper")if sec_name_span:file_name = sec_name_span.get('title').replace(":", "")pdf_file_name = f"{file_name}.PDF"else:pdf_file_name = f"{announcement_id}.PDF"all_links.append((pdf_url, pdf_file_name))# 检查是否存在下一页按钮try:next_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, 'btn-next')))except TimeoutException:break# 如果下一页按钮存在,模拟点击,并增加点击计数器if next_button:next_button.click()click_counter += 1time.sleep(5)else:break# 关闭WebDriverdriver.quit()# 创建新的保存目录new_save_dir = os.path.join(save_dir, 'new')os.makedirs(new_save_dir, exist_ok=True)# 下载PDF文件for link, pdf_file_name in all_links:# 清理文件名,移除特殊字符和大写字母A或Bclean_file_name = "".join(char for char in pdf_file_name if char.isalnum() or char in ('.', '_'))clean_file_name = clean_file_name.replace('A', '').replace('B', '')pdf_file_path = os.path.join(new_save_dir, clean_file_name)# 检查临时目录中是否已存在该文件temp_file_path = os.path.join(temp_dir, clean_file_name)if not os.path.exists(temp_file_path):print(f"Downloading {link}")try:response = requests.get(link, stream=True)if response.status_code == 200:with open(pdf_file_path, 'wb') as f:for chunk in response.iter_content(chunk_size=8192):f.write(chunk)# 等待1秒钟再继续下载time.sleep(1)except requests.exceptions.RequestException as e:print(f"An error occurred: {e}")print("Download completed.")# 调用函数,指定不需要点击翻页就开始下载链接,且只点击一次翻页按钮(实际上不点击)
download_pdfs_after_n_pages(0, 1, 'http://www.cninfo.com.cn/new/fulltextSearch?notautosubmit=&keyWord=%E5%8F%98%E6%9B%B4%E4%BC%9A%E8%AE%A1%E5%B8%88%E4%BA%8B%E5%8A%A1%E6%89%80', r'C:\temp\123\pdf\', r'C:\temp\123\pdf\old\')
运行效果如下,自动翻页去获取dom:

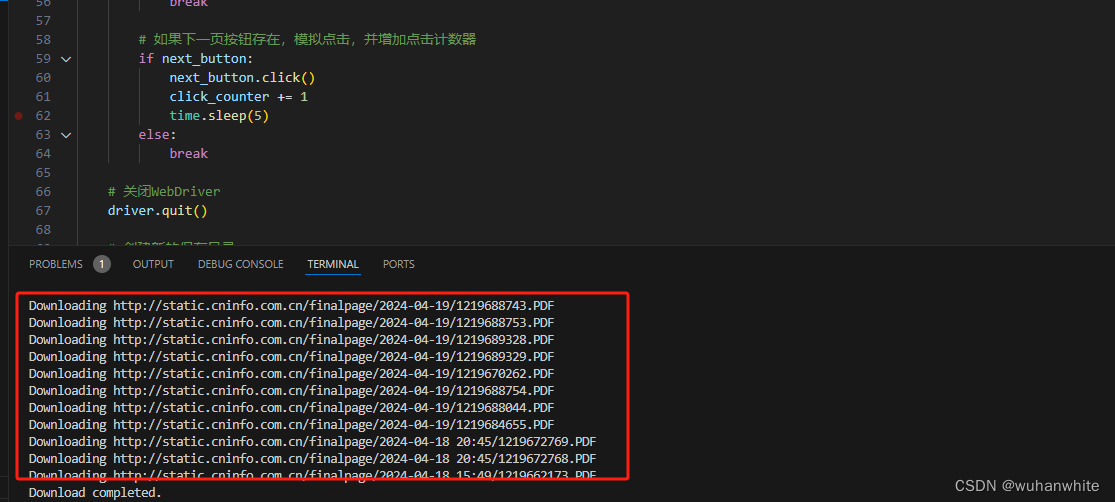
将pdf下载到设定的文件夹下
2,开始将pdf转换成txt文件,代码如下:
import os
import PyPDF2def process_pdfs_in_folder(pdf_folder_path, output_folder_path):# 确保输出文件夹存在if not os.path.exists(output_folder_path):os.makedirs(output_folder_path)# 遍历文件夹中的所有PDF文件for file_name in os.listdir(pdf_folder_path):if file_name.lower().endswith('.pdf'):pdf_file_path = os.path.join(pdf_folder_path, file_name)# 获取PDF文件名(不带扩展名)pdf_file_name = os.path.splitext(file_name)[0]try:# 打开PDF文件with open(pdf_file_path, 'rb') as file:reader = PyPDF2.PdfReader(file)text = ""# 遍历PDF中的每一页for page in reader.pages:text += page.extract_text()# 去掉空格和回车text = text.replace(" ", "").replace("\n", "")# 将提取的文本保存到文本文件output_file_path = os.path.join(output_folder_path, f"{pdf_file_name}.txt")with open(output_file_path, 'w', encoding='utf-8') as file:file.write(text)except PyPDF2.errors.PdfReadError as e:print(f"Error processing file {pdf_file_path}: {e}")# 调用方法
pdf_folder = r'C:\temp\123\pdf\' # 替换为PDF文件所在的文件夹路径
output_text_folder = r'C:\temp\123\txt' # 输出文本文件的文件夹路径
process_pdfs_in_folder(pdf_folder, output_text_folder)
运行后将相应的pdf文件变成了txt文件:
3,利用python读取txt文本的内容,将文本内容发送给大语言模型,让大语言模型分析文字内容,输出相应的json格式的数据,将json数据写入到excel中,代码如下:
我这里用的是零一万物的api,目前开发者申请送60元调用额度,这个调用方法和chatgpt一样的代码,只需要换 key和模型名称就行了,然后,prompt可以要求大模型按照需求输出json格式的数据,我的prompt是这样的。
“请你根据我提供给你的文字,不用其他废话,只需要从我给的文字中提取4个字段,1,这个公告的证券代码,2这个公告的证券名称,3,这个公告聘任的2024年的会计师事务所的名称。,4,2024年聘任的会计师事务所的审计费用。将这4个字段生成json格式给我。回答只需要json格式的数据,如果没找到值就为null,其他不用废话。严格按照这下面4个字段返回数据,'证券代码', '证券名称','会计师事务所名称','审计费用'。”
import pandas as pd
import os
import json
import time
from openai import OpenAI# 设置延迟时间,单位为秒
delay_time = 2 # 等待3秒def chat_with_kimi(user_input):client = OpenAI(api_key="api key",base_url="https://api.lingyiwanwu.com/v1",)try:completion = client.chat.completions.create(model="yi-34b-chat-0205", #模型名称messages=[{"role": "system", "content": "请你根据我提供给你的文字,不用其他废话,只需要从我给的文字中提取4个字段,1,这个公告的证券代码,2这个公告的证券名称,3,这个公告聘任的2024年的会计师事务所的名称。,4,2024年聘任的会计师事务所的审计费用。将这4个字段生成json格式给我。回答只需要json格式的数据,如果没找到值就为null,其他不用废话。严格按照这下面4个字段返回数据,'证券代码', '证券名称','会计师事务所名称','审计费用'。"},{"role": "user", "content": user_input}],temperature=0.3,)response = completion.choices[0].message.contentprint(f"Received response: {response}")time.sleep(delay_time)return responseexcept Exception as e:if "Rate limit reached" in str(e):print("Rate limit reached. Waiting for 30 seconds before retrying.")time.sleep(30) # 增加等待时间以避免频繁的API调用return chat_with_kimi(user_input)else:print(f"Error during API call: {e}")return None# 遍历指定文件夹下的txt文件
for filename in os.listdir('C:/temp/123/txt'):if os.path.splitext(filename)[1].lower() == '.txt':try:with open(os.path.join('C:/temp/123/txt', filename), 'r', encoding='utf-8') as file:user_input = file.read()print(f"Processing file: {filename}")# 运行聊天函数获取JSON数据response = chat_with_kimi(user_input)if response is None:continue # 如果API调用失败,则跳过当前文件# 尝试解析JSON数据try:# 移除响应中的反引号response_cleaned = response.replace('```json', '').replace('```', '')json_data = json.loads(response_cleaned)print(f"JSON data extracted: {json_data}")# 将JSON数据转换为DataFramedf = pd.DataFrame([json_data])# 检查文件是否存在if os.path.exists('b.xlsx'):# 如果文件存在,读取现有数据existing_df = pd.read_excel('b.xlsx')# 将新数据追加到现有数据df = pd.concat([existing_df, df], ignore_index=True)# 将DataFrame写入Excel文件df.to_excel('b.xlsx', sheet_name='sheet1', index=False)print(f"Data saved to b.xlsx")except json.JSONDecodeError:print("Error decoding JSON from response. Skipping this file.")# 删除已处理的txt文件os.remove(os.path.join('C:/temp/123/txt', filename))print(f"File {filename} has been deleted.")except Exception as e: # 捕获所有可能的文件处理错误print(f"Error processing file {filename}: {e}")print("Processing complete.")
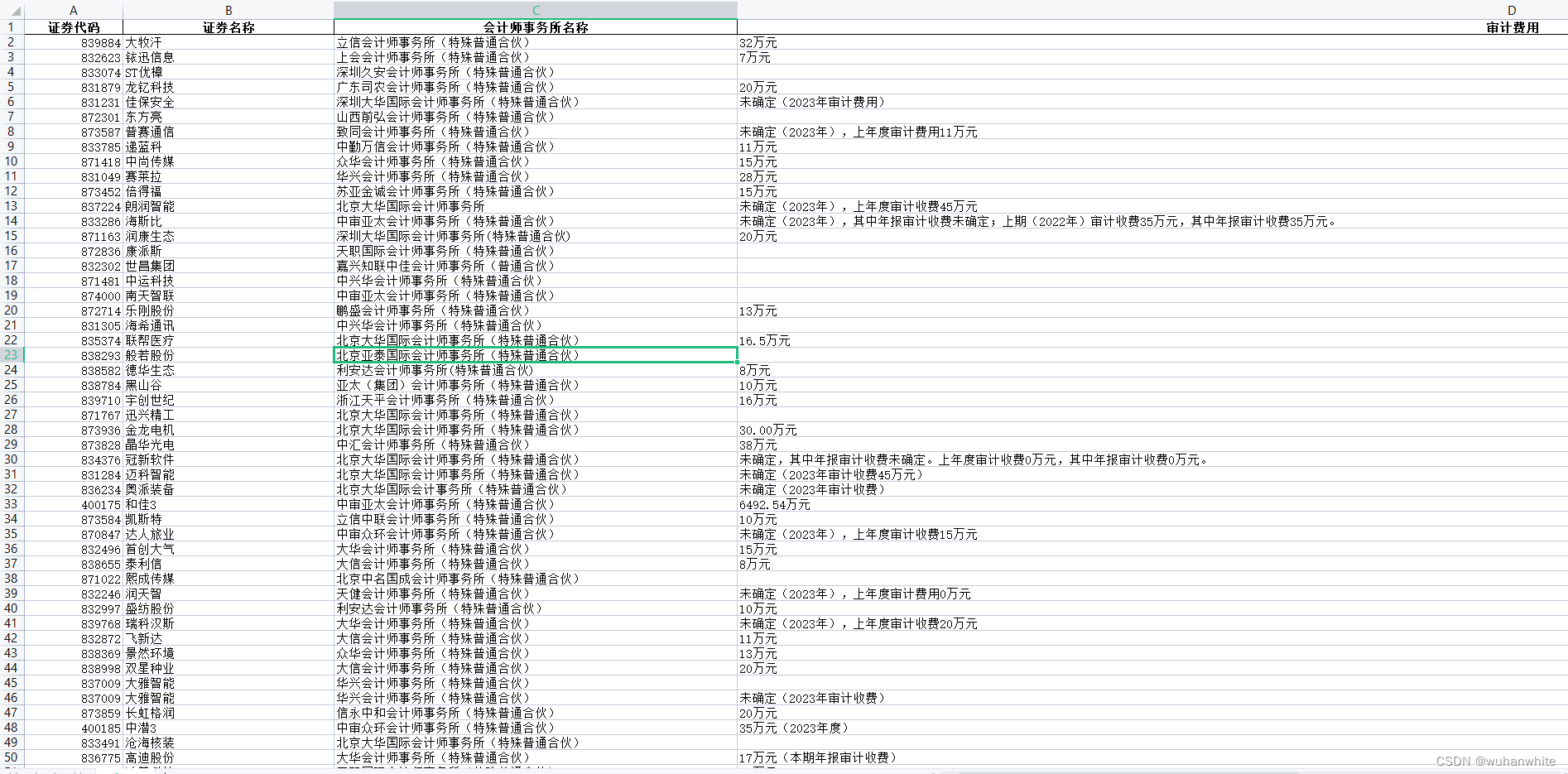
运行后,就在运行的目录下生成了一个b.xlsx文件,打开文件就可以看到如下数据
我感觉用这个方法,可以分析上市公司公布的减持或者预增公告,然后让大语言模型去分析这些公告,给出一些投资建议,今天分享就是这些,希望能帮到有需要的朋友们。
这篇关于Python获取上市公司报告,AI分析助力投资决策的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






