本文主要是介绍人脸识别之特征脸方法(Eigenface),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
人脸识别之特征脸方法(Eigenface)
zouxy09@qq.com
http://blog.csdn.net/zouxy09
因为需要,花了一点时间写了下经典的基于特征脸(EigenFace)的人脸识别方法的Matlab代码。这里仅把该代码分享出来。其实,在较新版本的OpenCV中已经提供了FaceRecognizer这一个类,里面不仅包含了特征脸EigenFace,还有FisherFace和LBPHFace这三种人脸识别方法,有兴趣的可以参考OpenCV的API手册,里面都有很详细的使用例程了。
一、特征脸
特征脸EigenFace从思想上其实挺简单。就相当于把人脸从像素空间变换到另一个空间,在另一个空间中做相似性的计算。这么说,其实图像识别的基本思想都是一样的,首先选择一个合适的子空间,将所有的图像变换到这个子空间上,然后再在这个子空间上衡量相似性或者进行分类学习。那为什么要变换到另一个空间呢?当然是为了更好的做识别或者分类了。那为什么变换到一个空间就好识别或者分类了呢?因为变换到另一个空间,同一个类别的图像会聚到一起,不同类别的图像会距离比较远,或者在原像素空间中不同类别的图像在分布上很难用个简单的线或者面把他们切分开,然后如果变换到另一个空间,就可以很好的把他们分开了。有时候,线性(分类器)就可以很容易的把他们分开了。那既然人类看起来同类的图像本来就是相似的,不同类的图像就不太相似,那为什么在原始的像素空间他们同类不会很近,不同类不会很远,或者他们为什么不好分开呢?因为图像各种因素的影响,包括光照、视角、背景和形状等等不同,会造成同一个目标的图像都存在很大的视觉信息上的不同。如下图所示。

世界上没有存在任何两片完全相同的叶子,虽然他们都是叶子。万千世界,同一类事物都存在共性,也存在个性,这就是这个世界多彩的原因。那怎么办呢?很自然,只要在我们想要的粒度上把同一类目标的共性找出来就好了,而且这个共性最好和我们要区分的类是不一样的。什么叫我们想要的粒度?我理解和我们的任务相关的。例如我们要区分人和车,那人的共性就是有脸、有手、有脚等等。但如果我们要区分亚洲人和非洲人,那么亚洲人的共性就是黄色皮肤等等。可以试着想象,上帝把世界万物组织成一个树状结构,树的根就是万物之源,下一层可以分成生物和非生物,再下一层将生物分为……(囧,想象不到),直到最底层,万物,你我,为树的一片普通得再普通的叶子。树越往下,粒度越小,分类越细(哈哈,自己乱扯的)。停!废话多了点,跑题了,回到刚才的问题,重头戏来了,要变换到什么空间,才具备上述这种良好类内相似、类间区分的效果?到这,我就只能say sorry了。计算机视觉领域发展了几十年,就为了这一个问题倾注了无数研究者的智慧与心血。当然了,也诞生和孕育了很多经典和有效的解答。(个人理解,上述说的实际上就是特征提取)。从一开始的颜色特征(颜色直方图)、纹理特征(Harr、LBP、HOG、SIFT等)、形状特征等到视觉表达Bag of Words,再到特征学习Deep Learning,技术的发展总能带给人希望,曙光也越来越清晰,但路还很远,是不?
扯太多了,严重离题了。上面说到,特征脸EigenFace的思想是把人脸从像素空间变换到另一个空间,在另一个空间中做相似性的计算。EigenFace选择的空间变换方法是PCA,也就是大名鼎鼎的主成分分析。它广泛的被用于预处理中以消去样本特征维度之间的相关性。当然了,这里不是说这个。EigenFace方法利用PCA得到人脸分布的主要成分,具体实现是对训练集中所有人脸图像的协方差矩阵进行本征值分解,得对对应的本征向量,这些本征向量(特征向量)就是“特征脸”。每个特征向量或者特征脸相当于捕捉或者描述人脸之间的一种变化或者特性。这就意味着每个人脸都可以表示为这些特征脸的线性组合。实际上,空间变换就等同于“搞基”,原始像素空间的基就是单位“基”,经过PCA后空间就是以每一个特征脸或者特征向量为基,在这个空间(或者坐标轴)下,每个人脸就是一个点,这个点的坐标就是这个人脸在每个特征基下的投影坐标。哦噢,说得有点绕。
下面就直接给出基于特征脸的人脸识别实现过程:
1)将训练集的每一个人脸图像都拉长一列,将他们组合在一起形成一个大矩阵A。假设每个人脸图像是MxM大小,那么拉成一列后每个人脸样本的维度就是d=MxM大小了。假设有N个人脸图像,那么样本矩阵A的维度就是dxN了。
2)将所有的N个人脸在对应维度上加起来,然后求个平均,就得到了一个“平均脸”。你把这个脸显示出来的话,还挺帅的哦。
3)将N个图像都减去那个平均脸图像,得到差值图像的数据矩阵Φ。
4)计算协方差矩阵C=ΦΦT。再对其进行特征值分解。就可以得到想要的特征向量(特征脸)了。
5)将训练集图像和测试集的图像都投影到这些特征向量上了,再对测试集的每个图像找到训练集中的最近邻或者k近邻啥的,进行分类即可。
算法说明白了都是不明白的,所以还是得去看具体实现。因此,可以对照下面的代码来弄清楚这些步骤。
另外,对于步骤4),涉及到求特征值分解。如果人脸的特征维度d很大,例如256x256的人脸图像,d就是65536了。那么协方差矩阵C的维度就是dxd=65536x65536。对这个大矩阵求解特征值分解是很费力的。那怎么办呢?如果人脸的样本不多,也就是N不大的话,我们可以通过求解C’=ΦTΦ矩阵来获得同样的特征向量。可以看到这个C’=ΦTΦ只有NxN的大小哦。如果N远远小于d的话,那么这个力气就省得很值了。那为什么求解C’=ΦTΦ矩阵的特征向量可以获得C=ΦΦT的特征向量?万众瞩目时刻,数学以完美舞姿登上舞台。证明如下:

其中,ei是C’=ΦTΦ的第i个特征向量,vi是C=ΦΦT的第i个特征向量,由证明可以看到,vi=Φei。所以通过求解C’=ΦTΦ的特征值分解得到ei,再左乘Φ就得到C=ΦΦT的特征向量vi了。也就是我们想要的特征脸。
二、Matlab实现
下面的代码主要是在著名的人脸识别数据库YaleB中进行实现。用的是裁切后的人脸数据库,可以点击CroppedYale下载。共有38个人的人脸,人脸是在不同的光照下采集的,每个人脸图像是32x32个像素。实验在每一个的人脸图像中随机取5个作为训练图像,剩下的作为测试图像。当然了,实际过程中这个过程需要重复多次,然后得到多次准确率的均值和方差才有参考意义,但下面的demo就不做这个处理了。计算相似性用的是欧氏距离,但编程实现的时候为了加速,用的是简化版,至于如何简化的,考验你的时候到了。
% Face recognition using eigenfacesclose all, clear, clc;%% 20 random splits
num_trainImg = 5;
showEigenfaces = true;%% load data
disp('loading data...');
dataDir = './CroppedYale';
datafile = 'Yale.mat';
if ~exist(datafile, 'file')readYaleDataset(dataDir, datafile);
end
load(datafile);%% Five images per class are randomly chosen as the training
%% dataset and remaining images are used as the test dataset
disp('get training and testing data...');
num_class = size(unique(labels), 2);
trainIdx = [];
testIdx = [];
for i=1:num_classlabel = find(labels == i);indice = randperm(numel(label));trainIdx = [trainIdx label(indice(1:num_trainImg))];testIdx = [testIdx label(indice(num_trainImg+1:end))];
end%% get train and test data
train_x = double(data(:, trainIdx));
train_y = labels(trainIdx);
test_x = double(data(:, testIdx));
test_y = labels(testIdx);%% computing eigenfaces using PCA
disp('computing eigenfaces...');
tic;
[num_dim, num_imgs] = size(train_x); %% A: #dim x #images
avg_face = mean(train_x, 2); %% computing the average face
X = bsxfun(@minus, train_x, avg_face); %% computing the difference images%% PCA
if num_dim <= num_imgs C = X * X';[V, D] = eig(C);
elseC = X' * X; [U, D] = eig(C);V = X * U;
end
eigenfaces = V;
eigenfaces = eigenfaces ./ (ones(size(eigenfaces,1),1) * sqrt(sum(eigenfaces.*eigenfaces)));
toc;%% visualize the average face
P = sqrt(numel(avg_face));
Q = numel(avg_face) / P;
imagesc(reshape(avg_face, P, Q)); title('Mean face');
colormap('gray');%% visualize some eigenfaces
figure;
num_eigenfaces_show = 9;
for i = 1:num_eigenfaces_showsubplot(3, 3, i)imagesc(reshape(eigenfaces(:, end-i+1), P, Q));title(['Eigenfaces ' num2str(i)]);
end
colormap('gray');%% transform all training images to eigen space (each column for each image)
disp('transform data to eigen space...');
X = bsxfun(@minus, train_x, avg_face);
T = eigenfaces' * X;%% transform the test image to eigen space
X_t = bsxfun(@minus, test_x, avg_face);
T_t = eigenfaces' * X_t;%% find the best match using Euclidean distance
disp('find the best match...');
AB = -2 * T_t' * T; % N x M
BB = sum(T .* T); % 1 x M
distance = bsxfun(@plus, AB, BB); % N x M
[score, index] = min(distance, [], 2); % N x 1%% compute accuracy
matchCount = 0;
for i=1:numel(index)predict = train_y(index(i));if predict == test_y(i)matchCount = matchCount + 1;end
endfprintf('**************************************\n');
fprintf('accuracy: %0.3f%% \n', 100 * matchCount / numel(index));
fprintf('**************************************\n');下面是将CroppedYale的图像读入matlab的代码。
function readYaleDataset(dataDir, saveName)dirs = dir(dataDir);data = [];labels = [];for i = 3:numel(dirs)imgDir = dirs(i).name;imgDir = fullfile(dataDir, imgDir);imgList = dir(fullfile(imgDir, '*.pgm'));for j = 1:numel(imgList)imgName = imgList(j).name;if strcmp('Ambient.pgm', imgName(end-10:end))continue;endim = imread(fullfile(imgDir, imgName));if size(im, 3) ==3im = rgb2gray(im);endim = imresize(im, [32 32]);im = reshape(im, 32*32, 1);data = [data im];endlabels = [labels ones(1, numel(imgList)-1) * (i-2)];endsave(saveName, 'data', 'labels');
end
三、实验结果
首先来个帅帅的平均脸:

然后来9个帅帅的特征脸:
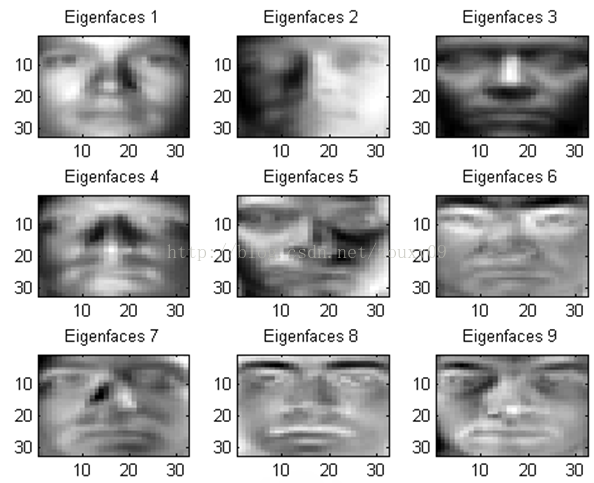
在本实验中,实验结果是30.126%左右。如果加上了某些预处理,这个结果就可以跑到62%左右。只是这个预处理我有点解析不通,所以就没放在demo上了。
本文如果有什么不对的地方,还望大家指正。
这篇关于人脸识别之特征脸方法(Eigenface)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



