本文主要是介绍深度学习--CNN应用--VGG16网络和ResNet18网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
我们在学习这两个网络时,应先了解CNN网络的相关知识
深度学习--CNN卷积神经网络(附图)-CSDN博客
这篇博客能够帮我们更好的理解VGG16和RetNet18
1.VGG16
1.1 VGG简介
VGG论文网址:VGG论文
大家有兴趣的可以去研读一下。
首先呢,我们先简单了解一下VGG网络的来源:
自2012年AlexNet在lmageNet图片分类比赛中大获成功以来,关于深度神经网络的研究又一次如火如茶般进行;
VGGNet 是由牛津大学视觉几何小组 (Visual Geometry Group,VGG)提出的一种深层卷积网络结构,他们以 7.32% 的错误率赢得了 2014年 ILSVRC 分类任务的亚军(冠军由 GoogLeNet 以 6.65% 的错误率夺得)
AlexNet的网络结构来提高自己的准确率,主要有两个方向:小卷积核和多尺度。而VGG的作者们则选择了另外一个方向,即加深网络深度。
VGG网络有一个特点:在每一次池化之后,经过卷积通道数都会翻倍,这样呢,就可以保留更多的特征。
1.2 VGG模型
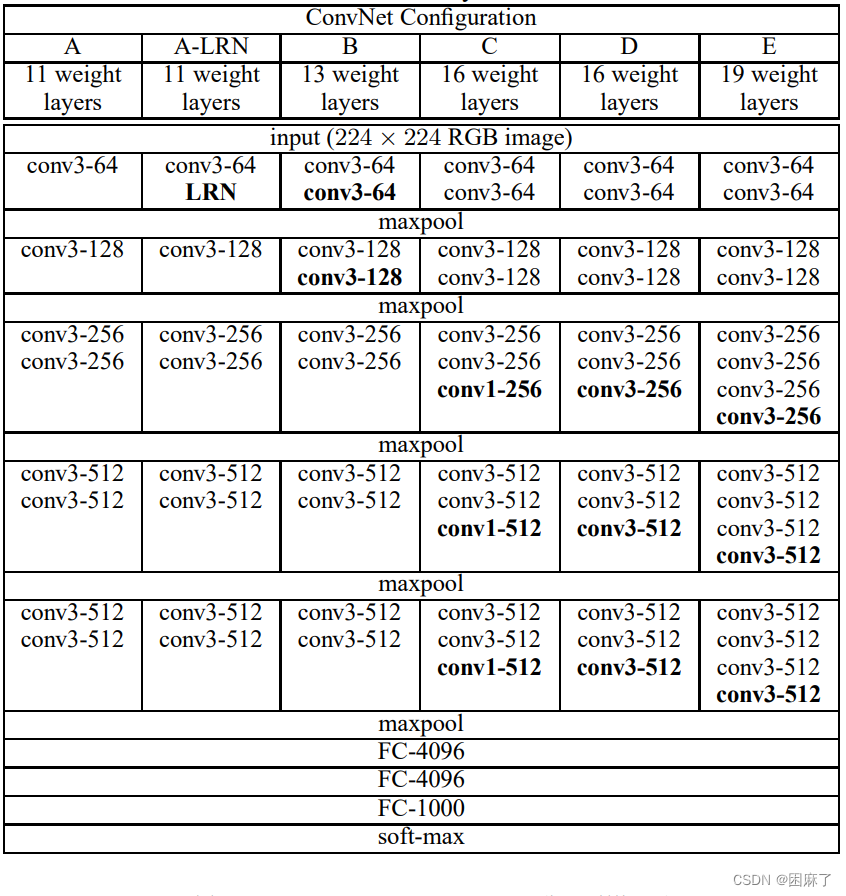
最上面我们可以看出VGG共有6中配置,分别为A,A-LRN,B,C,D,E,其中D和E两种最为常用,即我们所说的VGG16和VGG19。
而我们今天要学习的主要是D,即VGG16
下面是模型参数

这样看可能有点抽象,让我们结合下面的图片进行理解

我们结合图片对表进行理解:
“Weight layers” 在深度学习和神经网络的上下文中,通常指的是神经网络中的权重层。在神经网络中,每一层(无论是卷积层、全连接层还是其他类型的层)都有与之关联的权重矩阵(或权重张量,对于卷积层而言)。16Weight layers是指卷积层加上连接层共有16层,也就是对应着16个权重层。
con3-aaa,:卷积层全部都是3*3的卷积核,用上图中conv3-aaa表示,xxx表示通道数。其步长为1,用padding=same填充。池化层的池化核为2*2
maxpool :是指最大池化,在这里,pooling采用的是2*2的最大池化方法
FC-aaaa:指的是全连接层中有aaaa个节点
通俗地说,就是两组:两个卷积层接上一个池化层,
三组:三个卷积层接一个池化层,
最后是三个全连接层接上一个归一化处理,
这里的每一个卷积层和连接层后都要加上ReLu激活函数。
这样,我们对VGG16论文中的两个表格以及VGG16的框架就大体了解完了,接下来我们就具体分析它们,然后用代码实现它。
1.2.1 通道数
我们可以看出,初始的图片经过卷积层和池化层的处理,通道数在不断增加,有最开始输入的3个,变为了512个,再到4096个,最终的1000是指分类的类别数为1000个。
我们先要理解通道数指的是什么:通道数指的是同时处理的并发任务数量。
也就是说,通道数越多,同时处理的并发任务数量也就越多,
这样的好处也有很多,比如:
提高并发性:通过增加通道数,可以同时处理更多的任务,从而提高程序的并发性。这对于需要同时处理多个请求或任务的应用程序非常有用,例如网络服务器、数据处理等。
提高性能:增加通道数可以充分利用计算资源,提高程序的处理能力和响应速度。当程序中存在大量的IO操作时,通过增加通道数可以减少IO等待时间,提高整体性能。
提高资源利用率:通过增加通道数,可以更好地利用系统资源,充分发挥多核处理器的并行计算能力。这对于需要处理大量数据或计算密集型任务的应用程序非常有益。
支持高并发场景:在一些需要处理大量并发请求的场景下,增加通道数可以有效地提高系统的吞吐量和响应能力。例如,在Web服务器中,通过增加通道数可以同时处理更多的客户端请求,提供更好的用户体验。
1.2.3 最大池化层
通过最大池化层时,我们将池化层的大小和步长都设为2,这样可以将特征图的长和宽减半
不用多说,这样也有很多好处:
1. 降维与减少冗余信息:池化层通过下采样操作,有效地减少了特征图的维度,从而降低了数据的冗余性。这对于后续的卷积层或全连接层来说,可以显著减少计算量和内存消耗。
2. 扩大感知野:池化操作使得后续的卷积层能够看到更大范围的输入信息,即提高了网络的感知野。这有助于捕捉全局特征和上下文信息,从而增强网络的特征提取能力。
3. 防止过拟合:通过减少特征图的尺寸和参数数量,池化层有助于防止模型在训练过程中出现过拟合现象。过拟合是指模型在训练数据上表现良好,但在未见过的数据上性能较差的情况。
4. 提高鲁棒性:池化操作,尤其是最大池化,能够提取出输入中最显著的特征,对于输入中的微小变化(如平移、旋转或尺度变化)具有一定的不变性。这使得模型对于不同的输入变化更为鲁棒。
5. 加速计算:由于池化层减少了特征图的尺寸,后续的卷积或全连接层的计算量也会相应减少,从而提高了整体的计算速度。
1.2.4 ReLu函数
我们通过ReLu函数进行非线性激活,并且inplace选择了True,这样可以大大减少VGG16模型所需要的内存。
下面,我们就尝试用代码实现CNN网络
1.3 核心代码
import torch.nn
class VGG16(torch.nn.Module):def __init__(self):super(VGG16, self).__init__()self.conv1 = torch.nn.Conv2d(1, 64, kernel_size=3, stride=1, padding=1)self.relu1 = torch.nn.ReLU(inplace=True)self.conv2 = torch.nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)self.relu2 = torch.nn.ReLU(inplace=True)self.maxpl1 = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)self.relu3 = torch.nn.ReLU(inplace=True)self.conv4 = torch.nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1)self.relu4 = torch.nn.ReLU(inplace=True)self.maxpl2 = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.conv5 = torch.nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)self.relu5 = torch.nn.ReLU(inplace=True)self.conv6 = torch.nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)self.relu6 = torch.nn.ReLU(inplace=True)self.conv7 = torch.nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)self.relu7 = torch.nn.ReLU(inplace=True)self.maxpl3 = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.conv8 = torch.nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)self.relu8 = torch.nn.ReLU(inplace=True)self.conv9 = torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)self.relu9 = torch.nn.ReLU(inplace=True)self.conv10 = torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)self.relu10 = torch.nn.ReLU(inplace=True)self.maxpl4 = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.conv11 = torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)self.relu11 = torch.nn.ReLU(inplace=True)self.conv12 = torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)self.relu12 = torch.nn.ReLU(inplace=True)self.conv13 = torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)self.relu13 = torch.nn.ReLU(inplace=True)self.maxpl5 = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.fc1 = torch.nn.Linear(7*7*512, 4096)self.relu14 = torch.nn.ReLU(inplace=True)self.fc2 = torch.nn.Linear(4096, 4096)self.relu15 = torch.nn.ReLU(inplace=True)self.dropout = torch.nn.Dropout()self.fc3 = torch.nn.Linear(4096, 1000)def forward(self, x):x = self.conv1(x)x = self.relu1(x)x = self.conv2(x)x = self.relu2(x)x = self.maxpl1(x)x = self.conv3(x)x = self.relu3(x)x = self.conv4(x)x = self.relu4(x)x = self.maxpl2(x)x = self.conv5(x)x = self.relu5(x)x = self.conv6(x)x = self.relu6(x)x = self.conv7(x)x = self.relu7(x)x = self.maxpl3(x)x = self.conv8(x)x = self.relu8(x)x = self.conv9(x)x = self.relu9(x)x = self.conv10(x)x = self.relu10(x)x = self.maxpl4(x)x = self.conv11(x)x = self.relu11(x)x = self.conv12(x)x = self.relu12(x)x = self.conv13(x)x = self.relu13(x)x = self.maxpl5(x)x = x.view(-1,7*7*512)x = self.fc1(x)x = self.relu14(x)x = self.fc2(x)x = self.relu15(x)x = self.fc3(x)return x注意:
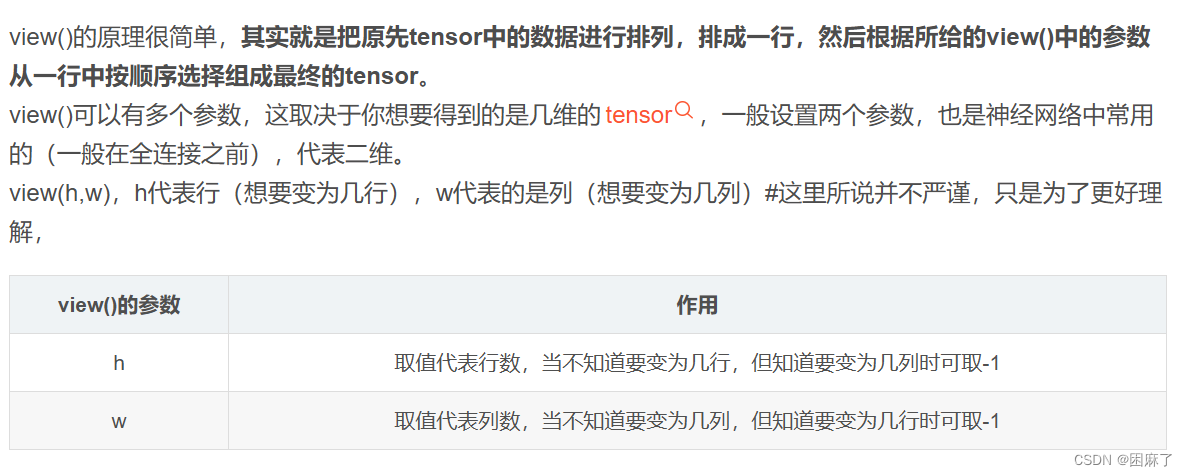
在实现全连接层之前,我们需要用view将x展平 原理如下:
1.4 实战实现猫狗数据集分类
1.4.1代码
import torch.nn
from PIL import Image # 这行代码从Pillow库中导入了Image模块,它提供了许多用于打开、操作和保存图像的函数。
import numpy as np
from torch.utils.data import Dataset # Dataset类是torch.utils.data模块中的一个抽象类,用于表示一个数据集
from torchvision import transforms
import os # os模块提供了与操作系统交互的函数,例如读取目录内容、检查文件是否存在等。
import torch
import matplotlib.pyplot as plt
import matplotlib
#设置字体为楷体
matplotlib.rcParams['font.sans-serif'] = ['KaiTi']# 自定义数据集
class mydataset(Dataset):def __init__(self,root_dir,lable_dir):self.root_dir=root_dir # 文件主路径dataset/trainself.label_dir=lable_dir # 分路径 cat 和 dogself.path=os.path.join(self.root_dir,self.label_dir) # 将文件路径的两部分连接起来self.img_path=os.listdir(self.path) # 查看self.transform = transforms.Compose([ # 包含:transforms.Resize((224,224)), # 统一大小为224*224transforms.ToTensor() # 转化为Tensor类型])def __len__(self):ilen=len(self.img_path)return ilen # 返回self.img_path列表的长度,即该数据集包含的图像数量。def __getitem__(self,item):img_name=self.img_path[item] # path路径中的第item个图像img_item_path=os.path.join(self.path,img_name) # 该图像的路径img=Image.open(img_item_path) # 打开并读取图像img=self.transform(img) # 转化为(224*224)并转化为Tensor类型if self.label_dir=="cat": # 如果是cat下的图片label=1 # label为猫狗的二分类值,因为二分类不能用文字“猫,狗”表示,所以这里我们用1来表示猫,0来表示狗else:label=0return img,label
root_dir="dataset/train"
lable_cat_dir="cat"
lable_dog_dir="dog"
cat_dataset=mydataset(root_dir,lable_cat_dir)
dog_dataset=mydataset(root_dir,lable_dog_dir)
train_dataset=cat_dataset+dog_dataset
class VGG16(torch.nn.Module):def __init__(self):super(VGG16, self).__init__()self.conv1 = torch.nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)self.relu1 = torch.nn.ReLU(inplace=True)self.conv2 = torch.nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)self.relu2 = torch.nn.ReLU(inplace=True)self.maxpl1 = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)self.relu3 = torch.nn.ReLU(inplace=True)self.conv4 = torch.nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1)self.relu4 = torch.nn.ReLU(inplace=True)self.maxpl2 = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.conv5 = torch.nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)self.relu5 = torch.nn.ReLU(inplace=True)self.conv6 = torch.nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)self.relu6 = torch.nn.ReLU(inplace=True)self.conv7 = torch.nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)self.relu7 = torch.nn.ReLU(inplace=True)self.maxpl3 = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.conv8 = torch.nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)self.relu8 = torch.nn.ReLU(inplace=True)self.conv9 = torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)self.relu9 = torch.nn.ReLU(inplace=True)self.conv10 = torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)self.relu10 = torch.nn.ReLU(inplace=True)self.maxpl4 = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.conv11 = torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)self.relu11 = torch.nn.ReLU(inplace=True)self.conv12 = torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)self.relu12 = torch.nn.ReLU(inplace=True)self.conv13 = torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)self.relu13 = torch.nn.ReLU(inplace=True)self.maxpl5 = torch.nn.MaxPool2d(kernel_size=2, stride=2)self.fc1 = torch.nn.Linear(7*7*512, 4096)self.relu14 = torch.nn.ReLU(inplace=True)self.fc2 = torch.nn.Linear(4096, 4096)self.relu15 = torch.nn.ReLU(inplace=True)self.dropout = torch.nn.Dropout()self.fc3 = torch.nn.Linear(4096, 2)def forward(self, x):x = self.conv1(x)x = self.relu1(x)x = self.conv2(x)x = self.relu2(x)x = self.maxpl1(x)x = self.conv3(x)x = self.relu3(x)x = self.conv4(x)x = self.relu4(x)x = self.maxpl2(x)x = self.conv5(x)x = self.relu5(x)x = self.conv6(x)x = self.relu6(x)x = self.conv7(x)x = self.relu7(x)x = self.maxpl3(x)x = self.conv8(x)x = self.relu8(x)x = self.conv9(x)x = self.relu9(x)x = self.conv10(x)x = self.relu10(x)x = self.maxpl4(x)x = self.conv11(x)x = self.relu11(x)x = self.conv12(x)x = self.relu12(x)x = self.conv13(x)x = self.relu13(x)x = self.maxpl5(x)x = x.view(-1,7*7*512)x = self.fc1(x)x = self.relu14(x)x = self.fc2(x)x = self.relu15(x)x = self.fc3(x)return x
trainloader=torch.utils.data.DataLoader(train_dataset,batch_size=4, shuffle=True)model=VGG16()
criterion = torch.nn.CrossEntropyLoss()
optimizer= torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)eopchs=6
for i in range(eopchs):sumloss=0for images, lables in trainloader:ypre=model(images)loss=criterion(ypre,lables)loss.backward()optimizer.step()optimizer.zero_grad()sumloss+=loss.item()print("Epoch {}, Loss: {}".format(i+1, sumloss/len(trainloader)))examples=enumerate(trainloader)
batch,(images,lables)=next(examples)fig=plt.figure()
for i in range(4):t=torch.unsqueeze(images[i],dim=0) # 增加一个维度,使t的形状与模型期望的形状相匹配logps=model(t)probab=list(logps.detach().numpy()[0])# logps.detach()从计算图中分离出logps,确保后续的操作不会影响到模型的梯度。# 接着,.numpy()将张量转换为NumPy数组。[0]取出第一个元素(因为t是一个批次大小为1的数据),# 最后list()将这个元素转换为一个列表。此时,probab是一个包含所有类别概率的列表。pred_label=probab.index(max(probab)) # 找出probab列表中概率最大的元素的索引,这个索引即代表模型预测的类别标签。if pred_label==0:pre="狗"else:pre="猫"img=torch.squeeze(images[i]) # 移除大小为1的维度,让它回到原来的形状img1=img.permute(1, 2, 0) # 将图像的维度从(channels, height, width)调整为(height, width, channels)img1=img1.numpy()plt.subplot(2,2,i+1) # 创建一个2*2的子图网格,并选择第i+1个子图作为当前绘图区域plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域并尽量减少重叠plt.imshow(img1,cmap='gray',interpolation='none')plt.title(f"预测值:{pre}")plt.xticks([]) # 设置x轴和y轴的刻度标签为空plt.yticks([])
plt.show()在第一层卷积层,我们需要根据图片原本的通道数进行修改,
最后的全连接层也要根据要分类的类的个数进行修改
注意:因为我们只是简单的进行示例,我们的循环次数就只循环了6次
大家可以根据自己的需要,来增加卷积层的层数来更好地获取图片特征,
或增加循环次数,来减少损失值
1.4.2 结果
Epoch 1, Loss: 0.6931928634643555
Epoch 2, Loss: 0.6932265162467957
Epoch 3, Loss: 0.6932326912879944
Epoch 4, Loss: 0.6933580279350281
Epoch 5, Loss: 0.6932826161384582
Epoch 6, Loss: 0.6932745337486267
因为我们的循环次数和卷积层层数过少,损失值仍然较大,所以即使我们训练集和测试集用的同一数据集 ,我们地预测仍然存在误差。
2. ResNet18
2.1 ResNet18简介
论文网址:
ResNet网络
让我们先来简单了解一下ResNet18
ResNet18是深度学习中的一个模型,它由残差网络(ResNet)和18层深度组成。
具体来说,ResNet18包含了4个卷积层,每个卷积层使用3x3的卷积核和ReLU激活函数来提取图像的局部特征。
同时,它还有8个残差块,每个残差块由两个卷积层和一条跳跃连接(恒等连接)构成,这有助于解决深度卷积神经网络中可能出现的梯度消失和梯度爆炸问题。
此外,ResNet18还包括全局平均池化层、一个大小为1000的全连接层以及输出层,后者使用softmax激活函数生成1000个类别的概率分布。
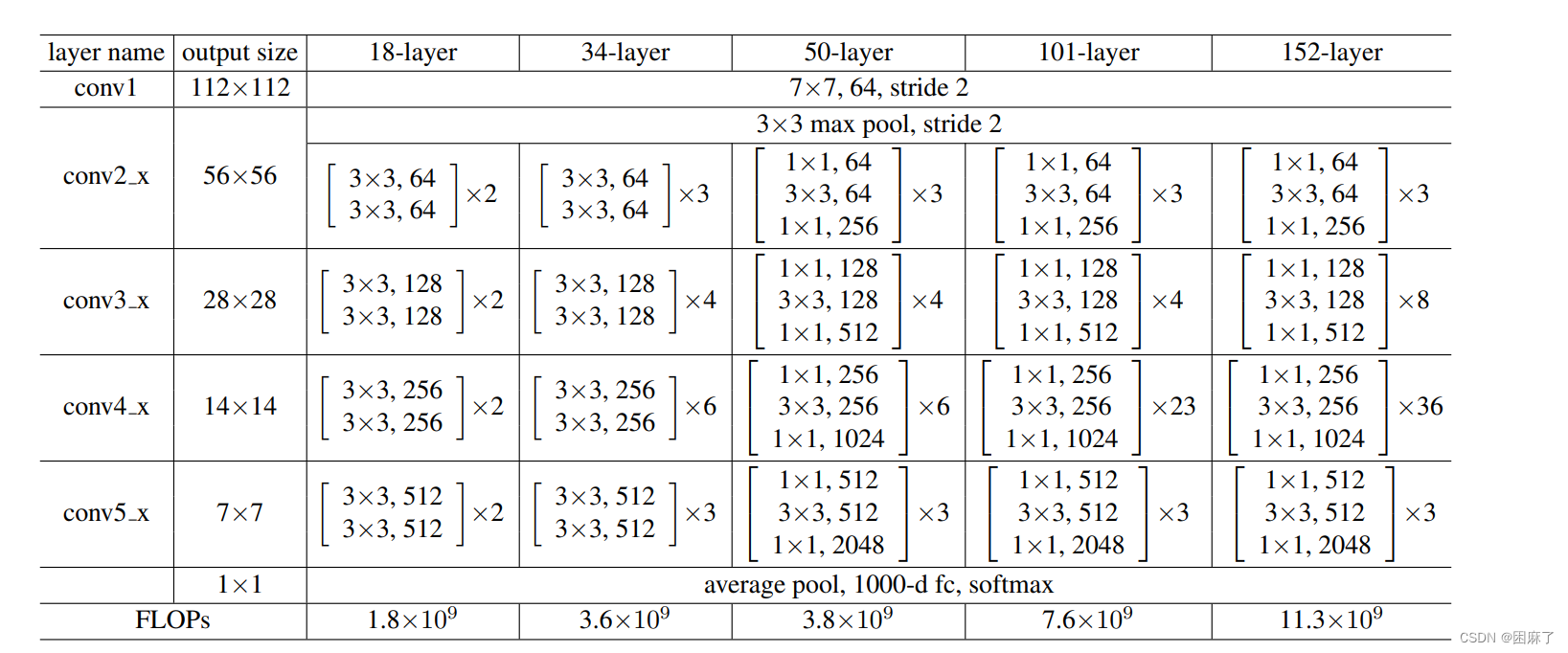
这这里,我们主要学习ResNet18,即18-layer
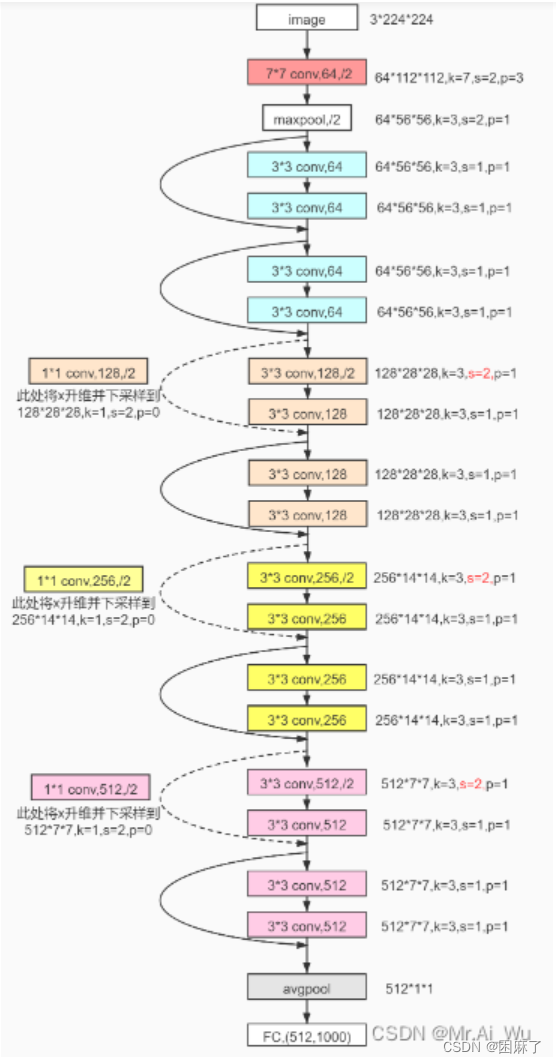
我们的代码主要围绕这部分展开
实线代表卷积直接进行相加,虚线代表要先将长和宽转化一下(使前一个和下一个能够相加),在求和
2.2 结构图
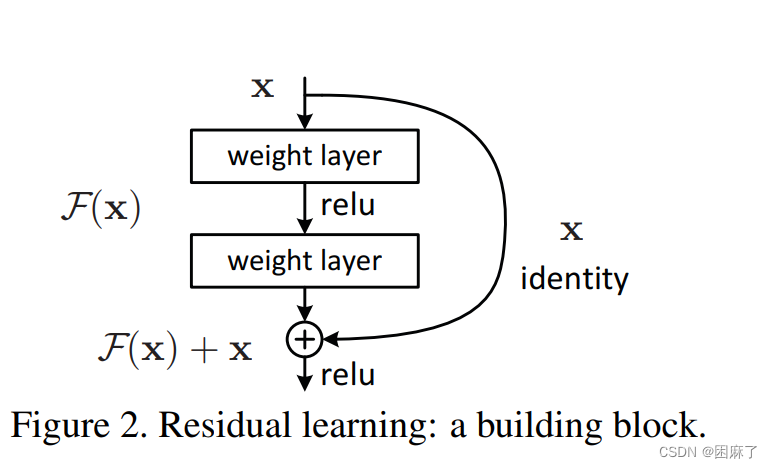
这个结构图是引入了一个快捷连接来解决深度神经网络训练中的梯度消失和梯度爆炸等问题,从而构建深层的神经网络 。
这部分也是残差函数的相关内容。
那么,什么是残差函数呢

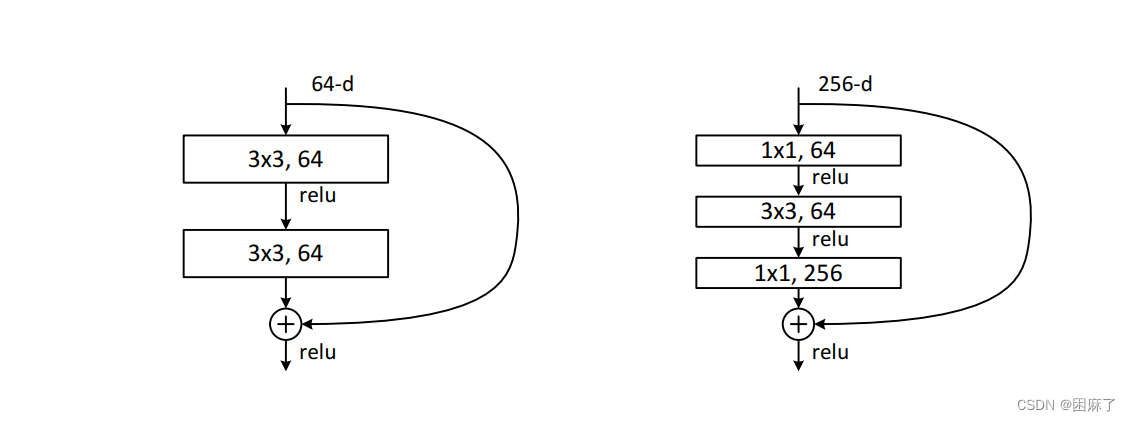
2.3 代码
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import font_manager
from sklearn.metrics import accuracy_score
import torch
from torch.utils.data import DataLoader, Dataset
import torchvision
from torchvision import transforms
from PIL import Image
import torch.nn.functional as F
import osclass CommonBlock(torch.nn.Module):def __init__(self, in_channel, out_channel, stride):super(CommonBlock, self).__init__()self.conv1 = torch.nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, bias=False)self.bn1 = torch.nn.BatchNorm2d(out_channel) # 添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定self.conv2 = torch.nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, bias=False)self.bn2 = torch.nn.BatchNorm2d(out_channel)def forward(self, x):identity = xx = F.relu(self.bn1(self.conv1(x)), inplace=True)x = self.bn2(self.conv2(x))x += identityreturn F.relu(x, inplace=True)class SpecialBlock(torch.nn.Module):def __init__(self, in_channel, out_channel, stride):super(SpecialBlock, self).__init__()self.change_channel = torch.nn.Sequential(torch.nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride[0], padding=0, bias=False),torch.nn.BatchNorm2d(out_channel))self.conv1 = torch.nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride[0], padding=1, bias=False)self.bn1 = torch.nn.BatchNorm2d(out_channel) # 添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定self.conv2 = torch.nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride[1], padding=1, bias=False)self.bn2 = torch.nn.BatchNorm2d(out_channel)def forward(self, x):identity = self.change_channel(x)x = F.relu(self.bn1(self.conv1(x)), inplace=True)x = self.bn2(self.conv2(x))x += identityreturn F.relu(x, inplace=True)class ResNet18(torch.nn.Module):def __init__(self, classes_num):super(ResNet18).__init__()# 定义网络模块self.prepare = torch.nn.Sequential(torch.nn.Conv2d(3, 64, 7, 2, 3),torch.nn.BatchNorm2d(64), # Batch Normanlization简称 BN,也就是数据归一化torch.nn.ReLU(inplace=True),torch.nn.MaxPool2d(3, 2, 1))self.layer1 = torch.nn.Sequential(CommonBlock(64, 64, 1),CommonBlock(64, 64, 1))self.layer2 = torch.nn.Sequential(SpecialBlock(64, 128, [2, 1]),CommonBlock(128, 128, 1))self.layer3 = torch.nn.Sequential(SpecialBlock(128, 256, [2, 1]),CommonBlock(256, 256, 1))self.layer4 = torch.nn.Sequential(SpecialBlock(256, 512, [2, 1]),CommonBlock(512, 512, 1))self.pool = torch.nn.AdaptiveAvgPool2d(output_size=(1, 1))self.fc = torch.nn.Sequential(torch.nn.Linear(256, classes_num))def forward(self, x):x = self.prepare(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.pool(x)x = x.reshape(x.shape[0], -1)x = self.fc(x)return x
有几个我们需要注意的点:
class SpecialBlock(torch.nn.Module):def __init__(self, in_channel, out_channel, stride):super(SpecialBlock, self).__init__()self.change_channel = torch.nn.Sequential(torch.nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride[0], padding=0, bias=False),torch.nn.BatchNorm2d(out_channel))self.conv1 = torch.nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride[0], padding=1, bias=False)self.bn1 = torch.nn.BatchNorm2d(out_channel) # 添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定self.conv2 = torch.nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride[1], padding=1, bias=False)self.bn2 = torch.nn.BatchNorm2d(out_channel)def forward(self, x在下面,stride传入的是一个列表,分别表示横向滑动和纵向滑动的步长,当 stride=stride[0]时表示的是横向滑动,另一个则是纵向滑动。
self.change_channel = torch.nn.Sequential
它允许用户将多个计算层按照顺序组合成一个模型。在深度学习中,模型可以是由各种不同类型的层组成的,例如卷积层、池化层、全连接层等。nn.Sequential()方法可以将这些层组合在一起,形成一个整体模型。
这篇关于深度学习--CNN应用--VGG16网络和ResNet18网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






