本文主要是介绍17行代码实现kmeans,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
恩,当然是用库了。计算点与点之间距离,用scipy中的cdist,这点是半年前吧看的一篇代码学的。
kmeans原理就不介绍了,很简单的。代码如下:
def kmeans(k,data):length = len(data)# width = len(data[0])zeros = np.array([0]*length)new_data = np.column_stack((data,zeros))# print(new_data)for itera_num in range(0,30,1): if itera_num==0:#第一次循环,随机选择均值import random#随机选择K个不重复的随机数 random_nums = random.sample([i for i in range(0,length,1)],k)#用这k个随机数选择初始的均值向量 mean_vector_list=[data[random_nums[i]] for i in range(0,k,1)]else:#从已有的计算平均值,mean_vector_list.clear()for i in range(0,k,1):box = [new_data[j][:-1] for j in range(0,length) if new_data[j][-1]==i]#取得标记为i所有的行avg = np.average(np.array(box),axis=0)#矩阵按照列求平均值mean_vector_list.append(avg)#重新进行归类,此时应该:1,算出距离2,追个数据判断,加入盒子distances = cdist(new_data[:,:-1],np.array(mean_vector_list))minDinstanceIndex = np.argmin(distances,axis=1)#axis为1表示按行取最小的indexnew_data = np.column_stack((new_data[:,:-1],minDinstanceIndex))#更新最后一行的标记数据return new_data[:,-1] #返回最后一列
下面是完整的代码,导入数据和可视化,最后结果输出。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from scipy.spatial.distance import cdist
from sklearn.cluster import KMeans
plt.figure(figsize=(12, 12))n_samples = 1500
random_state = 170
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
#print(X[0])# Incorrect number of clusters
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X)'''kmeans就是要迭代进行计算,主要步骤是:
数据的形式:data:ndarray
X:[[0,0,1,y0],[0,0,2,y1],[0,1,2,y2]...]这是某个空盒子中的形式
1,循环开始前,先选定k个重心点
2循环,迭代的次数选择重心,当迭代为1,则随机选,否则追个遍历box中空盒子的元素的平均值//计算每个点与k个点的距离,哪个距离小则将这个点,将最后一位的标记修改计算新的重心输出:ndarray#循环结束,返回一个盒子集合:每个数据都放在一个盒子中#实际要求的是,对于X的每个数值,输入一个类别,上述的过程还要一部处理。考#考虑方案X后面直接加y是不是好些呢???直接加类型,算距离时候不能用用啊。#还是可以这么搞的,对矩阵进行分片嘛
'''def kmeans(k,data):length = len(data)# width = len(data[0])zeros = np.array([0]*length)new_data = np.column_stack((data,zeros))# print(new_data)for itera_num in range(0,30,1): if itera_num==0:#第一次循环,随机选择均值import random#随机选择K个不重复的随机数 random_nums = random.sample([i for i in range(0,length,1)],k)#用这k个随机数选择初始的均值向量 mean_vector_list=[data[random_nums[i]] for i in range(0,k,1)]else:#从已有的计算平均值,mean_vector_list.clear()for i in range(0,k,1):box = [new_data[j][:-1] for j in range(0,length) if new_data[j][-1]==i]#取得标记为i所有的行avg = np.average(np.array(box),axis=0)#矩阵按照列求平均值mean_vector_list.append(avg)#重新进行归类,此时应该:1,算出距离2,追个数据判断,加入盒子distances = cdist(new_data[:,:-1],np.array(mean_vector_list))minDinstanceIndex = np.argmin(distances,axis=1)#axis为1表示按行取最小的indexnew_data = np.column_stack((new_data[:,:-1],minDinstanceIndex))#更新最后一行的标记数据return new_data[:,-1] #返回最后一列mypredict_y = kmeans(3,X)
transformation = [[0.2, -0.2], [-0.40887718, 0.2]]
X_aniso = np.dot(X, transformation)
mypredict_y2 =kmeans(3,X_aniso)# Different variance
X_varied, y_varied = make_blobs(n_samples=n_samples,cluster_std=[1.0, 2.5, 0.5],random_state=random_state)
mypredict_y3 = kmeans(3,X_varied)# Unevenly sized blobs
X_filtered = np.vstack((X[y == 0][:500], X[y == 1][:100], X[y == 2][:10]))
mypredict_y4 = kmeans(3,X_filtered)plt.subplot(221)
plt.scatter(X[:, 0], X[:, 1], c=mypredict_y)
plt.subplot(222)
plt.scatter(X_aniso[:, 0], X_aniso[:, 1], c=mypredict_y2)
plt.subplot(223)
plt.scatter(X_varied[:, 0], X_varied[:, 1], c=mypredict_y3)
plt.subplot(224)
plt.scatter(X_filtered[:, 0], X_filtered[:, 1], c=mypredict_y4)plt.show()分类结果展示:
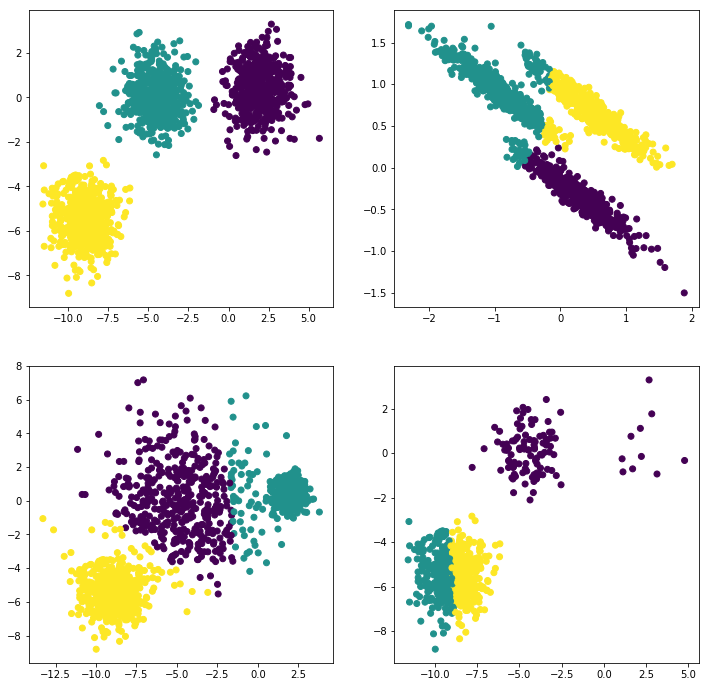
对第四类效果并不好,因为我的kmeans没有对中心点进行一些处理,导致不好。
这篇关于17行代码实现kmeans的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






