本文主要是介绍【Node.js从基础到高级运用】二十五、Node.js中Cluster的作用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
Node.js中的
cluster模块允许您轻松创建共享服务器端口的子进程。这是一个核心模块,用于在Node.js应用程序中实现多进程架构,以充分利用多核CPU系统的计算能力。
cluster介绍
当您启动一个Node.js应用程序时,默认情况下它运行在单个进程中。对于多核CPU系统来说,这意味着您可能没有充分利用系统的全部潜力。通过使用cluster模块,您可以启动一个主进程(通常称为“master”或“主”进程),它可以分叉多个工作进程(“workers”或“工作进程”),每个工作进程都是应用程序的一个实例,运行在自己的进程中。
主进程不负责处理实际的工作负载,而是负责监控和管理工作进程。例如,它可以根据需要创建新的工作进程或替换已经崩溃的工作进程。这样,即使某个工作进程崩溃,整个应用程序也可以继续运行。
cluster模块的基本使用步骤如下:
- 引入
cluster模块。 - 使用
cluster.isMaster属性检查当前进程是否是主进程。 - 在主进程中,使用
cluster.fork()方法创建工作进程。 - 设置必要的事件监听,以便于主进程可以响应工作进程的启动、退出等事件。
- 在工作进程中,编写实际处理客户端请求的代码。
使用cluster模块的好处包括:
- 提高性能:通过在多个核心上并行运行,可以更有效地利用服务器的硬件资源。
- 提高可靠性:如果一个工作进程崩溃,它可以被新的工作进程替换,而不会影响其他工作进程或主进程。
- 负载分配:Node.js的
cluster模块可以在工作进程之间自动分配连接,以实现负载均衡。
基础使用
使用 cluster 模块来创建一个能够处理多核 CPU 的服务器。
// 导入http和cluster模块
const http = require('http');
const cluster = require('cluster');
const numCPUs = require('os').cpus().length; // 获取CPU的核心数if (cluster.isMaster) {console.log(`主进程 ${process.pid} 正在运行`);// 衍生工作进程。for (let i = 0; i < numCPUs; i++) {cluster.fork();}cluster.on('exit', (worker, code, signal) => {console.log(`工作进程 ${worker.process.pid} 已退出`);});
} else {// 工作进程可以共享任何TCP连接。// 在本例中,它是一个HTTP服务器http.createServer((req, res) => {res.writeHead(200);res.end('Hello World!');}).listen(3000);console.log(`工作进程 ${process.pid} 已启动`);
}
代码解释:
- 引入模块: 引入
http,cluster, 和os模块。 - 主进程与工作进程逻辑: 使用
cluster.isMaster来区分代码执行是在主进程还是工作进程中。 - 主进程逻辑:
- 主进程负责打印当前进程的 PID,并根据 CPU 核心数衍生相应数量的工作进程。
- 监听
exit事件以打印退出的工作进程信息。
- 工作进程逻辑:
- 每个工作进程都设置了一个 HTTP 服务器监听同一个端口(3000端口)。
- 工作进程的启动会被记录在日志中。
使用这种方法,Node.js 应用可以有效地利用多核 CPU,提高应用的处理能力和响应速度。
进阶使用:零停机重启
const http = require("http");
const cluster = require("cluster");
const os = require("os");//cpu数量(几核)
const cpus = os.cpus().length;
// console.log(`Clustering to ${cpus} CPUS`);
var express = require("express")();
//主进程
if (cluster.isMaster) {console.log("master process id :", process.pid);for (let i = 0; i < cpus; i++) {//分派子进程cluster.fork();}//服务器收到这个消息,退出任务process.on("SIGINT", function () {console.log("ctrl+c");process.exit();});express.listen(9000);// 当主进程收到指定消息时(访问restart),开始“零停机重启”操作。express.get("/restart", function (req, res, next) {const workers = Object.keys(cluster.workers);// console.log('workers',workers)//重启函数function restart_worker(i) {if (i >= workers.length) return;//第i个工作进程var worker = cluster.workers[workers[i]];console.log(`Stoping worker:${worker.process.pid}`);//中断工作进程worker.disconnect();//工作进程退出时worker.on("exit", function () {//启动工作进程const new_worker = cluster.fork();//当新的工作进程,准备好,并开始监听新的连接时,迭代重启下一个工作子进程new_worker.on("listening", function () {restart_worker(i + 1);})});}//重启第一个工作进程restart_worker(0);res.end("restart ok");});} else {//子进程执行内容const pid = process.pid;http.createServer(function (req, res) {console.log(`Handing request from ${pid}`);res.end(`Hello from ${pid}\n`);}).listen(8000, function () {console.log(`Started ${pid}`);})}
代码解析:
集群主进程用express提供web服务;
集群子工作进程用http提供web服务;
当主进程收到指定消息时(访问restart路径),开始“零停机重启”操作。
实现重点是:停掉一个工作进程,并重启一个新的工作进程,当新的工作进程启动好,并进入监听状态时(即:可正常提供Web服务时),再重启下一个工作进程,直到全部重启完成。
执行效果:
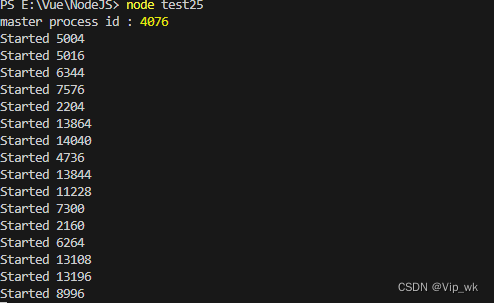
为了更直观展示效果加入一行代码:
http.createServer(function (req, res) {console.log(`Handing request from ${pid}`);res.end(`Hello from ${pid}\n`);}).listen(8000, function () {console.log(`Started ${pid}`);console.log(`${pid} hello 7777777777777777777777`)})
此时先启动服务:
node test25
再次修改代码:
http.createServer(function (req, res) {console.log(`Handing request from ${pid}`);res.end(`Hello from ${pid}\n`);}).listen(8000, function () {console.log(`Started ${pid}`);console.log(`${pid} hello 8888888888888888888888`)})
通过网页打开http://localhost:9000/restart触发重启:

结果:
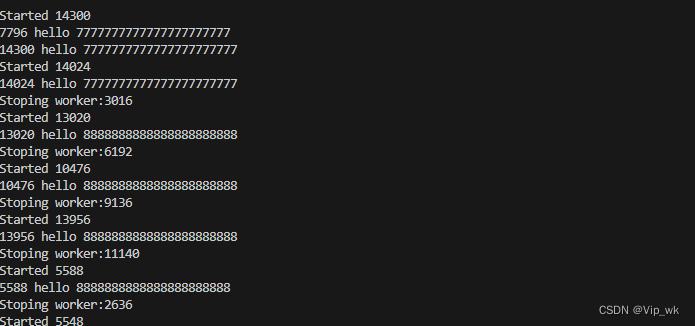
总结
需要注意的是,cluster模块并不是万能的。例如,在有状态的应用程序中,您可能需要考虑如何在工作进程之间共享状态。此外,如果您的应用程序主要受到I/O限制而不是CPU限制,那么增加更多的工作进程可能不会带来太大的性能提升。
参考
Nodejs教程63:零停机重启
这篇关于【Node.js从基础到高级运用】二十五、Node.js中Cluster的作用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




