本文主要是介绍送书|一文教你用 Python 对 Excel文件进行批量操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
👆点击“Python乱炖”,获取更多书讯

工作中遇到需要需要批量处理Excel文件的情况,你还在手动一个一个地处理吗?赶紧学会下面的自动化批量处理方法,告别机械式的低效工作吧!
01
OS 库介绍
OS(Operation System)指操作系统。在 Python 中,OS 库主要提供了与操作系统即电脑系统之间进行交互的一些功能。很多自动化操作都会依赖该库的功能。
02
OS 库基本操作
1 获取当前工作路径
我们在《对比Excel,轻松学习Python报表自动化》一书的第2章介绍了如何安装Anaconda,以及如何利用Jupyter Notebook写代码。
可是你们知道写在 Jupyter Notebook 中的代码存储在电脑的哪里吗?是不是很多读者不知道?想要知道也很简单,只需要在 Jupyter Notebook 中输入如下代码,然后运行。
import os
os.getcwd()运行上面代码会得到如下结果。
'C:\\Users\\zhangjunhong\\python 库\\Python 报表自动化'上面这个文件路径就是此时 Notebook 代码文件所在的路径,你的代码存储在哪个文件路径下,运行就会得到对应结果。
2 获取一个文件夹下的所有文件名
我们经常会将电脑本地的文件导入 Python 中来处理,在导入之前需要知道文件的存储路径及文件名。如果只有一两个文件,那直接手动输入文件名和文件路径即可,但有时需要导入的文件有很多。手动输入效率就会比较低,需要借助代码来提高效率。
图1 所示文件夹中有 4 个 Excel 文件。
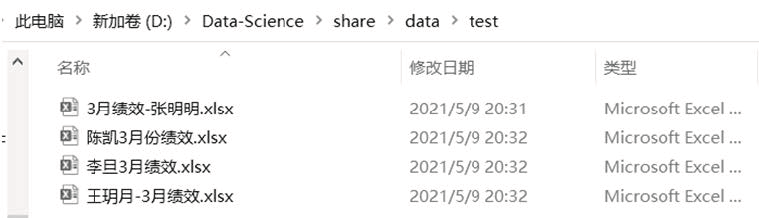
图 1
我们可以使用 os.listdir(path)来获取 path 路径下所有的文件名。具体实现代码如下。
import os
os.listdir('D:/Data-Science/share/data/test')运行上面代码会得到如下结果。
['3 月绩效-张明明.xlsx', '李旦 3 月绩效.xlsx', '王玥月-3 月绩效.xlsx', '陈凯 3 月份绩效.xlsx']3 对文件进行重命名
对文件进行重命名是比较高频的需求,我们可以利用 os.rename('old_name','new_name') 来对文件进行重命名。old_name 就是旧文件名,new_name 就是新文件名。
我们先在 test 文件夹下新建一个名为 test_old 的文件,然后利用如下代码,就可以把 test_old 文件名改成 test_new。
os.rename('D:/Data-Science/share/data/test/test_old.xlsx','D:/Data-Science/share/data/test/test_new.xlsx')运行上面代码以后,再到 test 文件夹下面,就可以看到 test_old 文件已经不存在了,只有test_new。
4 创建一个文件夹
当我们想要在指定路径下创建一个新的文件夹时,可以选择手动新建文件夹,也可以利用 os.mkdir(path)新建,只需要指明具体的路径(path)即可。
当运行下面代码时,就表示在 D:/Data-Science/share/data 路径下新建一个名为test11 的文件夹,效果如图 2 所示。
os.mkdir('D:/Data-Science/share/data/test11')
图2
5 删除一个文件夹
删除文件夹与创建文件夹是相对应的。当然,我们也可以选择手动删除一个文件夹,也可以利用 os.removedirs(path)进行删除,指明要删除的路径(path)。
当运行如下代码时,就表示把刚刚创建的 test11 文件夹删除了。
os.removedirs('D:/Data-Science/share/data/test11')6 删除一个文件
删除文件是删除一个具体的文件,而删除文件夹是将整个文件夹,包含文件夹中的所有文件进行删除。删除文件利用的是 os.remove(path),指明文件所在的路径(path)。
当我们运行如下代码时,就表示将 test 文件夹中 test_new 文件删除了。
os.remove('D:/Data-Science/share/data/test/test_new.xlsx')03
批量操作
1 批量读取一个文件夹下的多个文件
有时一个文件夹下会包含多个类似的文件,比如一个部门不同人的绩效文件,我们需要把这些文件批量读取到 Python 中,然后进行处理。
我们在前面学过,如何读取一个文件,可以用 load_work(),也可以用 read_excel(),不管采用哪种方式,都只需要指明要读取文件的路径即可。
那如何批量读取呢?先获取该文件夹下的所有文件名,然后遍历读取每一个文件。
具体实现代码如下所示。
import pandas as pd
#获取文件夹下的所有文件名
name_list = os.listdir('D:/Data-Science/share/data/test')
#for 循环遍历读取
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/test/' + i)
print('{}读取完成!'.format(i))如果要对读取的文件的数据进行操作,那么只需把具体的操作实现代码放置在读取代码之后即可。比如我们要对每一个读取进来的文件进行删除重复值处理,实现代码如下。
import pandas as pd
#获取文件夹下的所有文件名
name_list = os.listdir('D:/Data-Science/share/data/test')
#for 循环遍历读取
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/test/' + i)
df = df.drop_duplicates() #删除重复值处理
print('{}读取完成!'.format(i))2 批量创建文件夹
有时我们需要根据特定的主题来创建特定的文件夹,比如需要根据月份创建 12个文件夹。我们前面介绍过如何创建单个文件夹,如果要批量创建多个文件夹,则只需要遍历执行单个文件夹的语句即可。具体实现代码如下。
month_num = ['1 月','2 月','3 月','4 月','5 月','6 月','7 月','8 月','9 月','10 月','11
月','12 月']
for i in month_num:
os.mkdir('D:/Data-Science/share/data/' + i)
print('{}创建完成!'.format(i))运行上面代码以后就会在该文件路径下新建 12 个文件夹,如图3 所示。
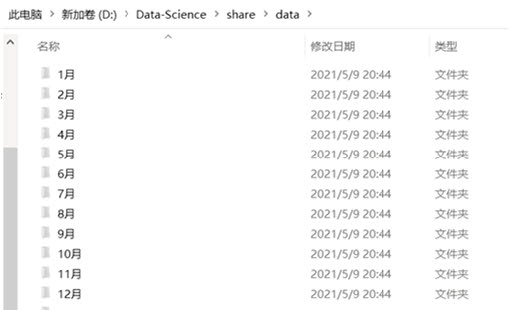
图 3
3 批量重命名文件
有时我们有好多相同主题的文件,但是这些文件的文件名比较混乱,比如图4所示文件,是各个员工的 3 月绩效情况,但是命名格式都不太一样,我们要将其统一成“名字+3 月绩效”这样的格式。要达到这种效果,可以通过前面学到的对文件进行重命名的操作来实现,前面只介绍了对单一文件的操作,那如何同时对多个文件进行批量操作呢?

图 4
具体实现代码如下。
import os
#获取指定文件夹下所有文件名
old_name = os.listdir('D:/Data-Science/share/data/test')
name = ["张明明","李旦","
玥
王 月
","陈凯"]
#遍历每一个姓名
for n in name:
#遍历每一个旧文件名
for o in old_name:
#判断旧文件名中是否包含特定的姓名
#如果包含就进行重命名
if n in o:
os.rename('D:/Data-Science/share/data/test/' + o, 'D:/Data-Science/
share/data/test/' + n +"3 月绩效.xlsx")运行上面代码以后可以看到文件夹下的原文件名已被全部重命名完成,如图5所示。

图 5
04
其他批量操作
1 批量合并多个文件
图6 所示文件夹下面有 1—6 月的分月销售日报,已知这些日报的结构是相同的,只有“日期”和“销量”两列,现在我们想要把这些不同月份的日报合并成一份。

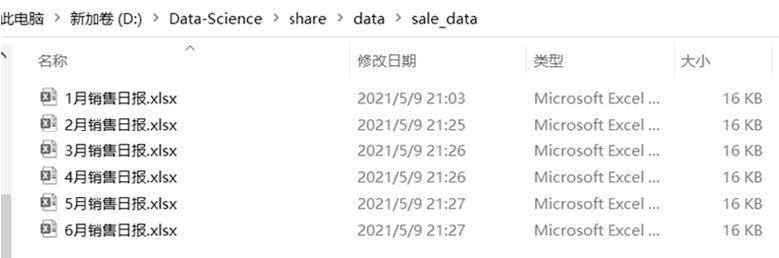
图 6
将分月销售日报合并成一份文件的具体实现代码如下。
import os
import pandas as pd
#获取指定文件下所有文件名
name_list = os.listdir('D:/Data-Science/share/data/sale_data')
#创建一个相同结构的空 DataFrame
df_o = pd.DataFrame({'日期':[],'销量':[]})
#遍历读取每一个文件
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/sale_data/' + i)
#进行纵向拼接
df_v = pd.concat([df_o,df])
#把拼接后的结果赋值给 df_o
df_o = df_v
df_o运行上面代码,就会得到合并后的文件 df_o,如图 7 所示。
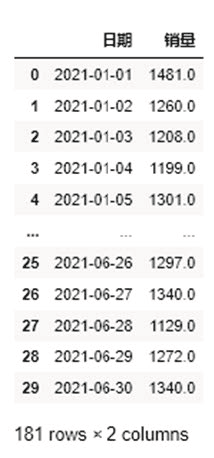

图 7
2 将一份文件按照指定列拆分成多个文件
上面介绍了如何批量合并多个文件,我们也有合并多个文件的逆需求,即按照指定列将一个文件拆分成多个文件。
还是上面的数据集,假设我们现在拿到了一份 1—6 月的文件,这份文件除了“日期”和“销量”两列,还多了一列“月份”。现在需要做的是,根据“月份”列将这一份文件拆分成多个文件,每个月份单独存储为一个文件。
具体实现代码如下。
#生成一列新的“月份”列
df_o['月份'] = df_o['日期'].apply(lambda x:x.month)
#遍历每一个月份值
for m in df_o['月份'].unique():
#将特定月份值的数据筛选出来
df_month = df_o[df_o['月份'] == m]
#将筛选出来的数据进行保存
df_month.to_csv(r'D:/Data-Science/share/data/split_data/' + str (m) + '月销售日报_拆分后.csv')运行上面代码,就可以在目标路径下看到拆分后的多个文件,如图8 所示。
图 8
*本文节选自《对比Excel,轻松学习Python报表自动化》一书,更多关于使用Python进行报表自动化的内容,欢迎阅读本书!


▊《对比Excel,轻松学习Python报表自动化》
张俊红 著
对比Excel系列畅销超15万册
零基础系统学Excel/Python数据处理和格式设置
人人都能学会的数据分析工具,加薪不加班
赠199元配套视频课
这本《对比Excel,轻松学习Python 报表自动化》继承了对比学习的特点,全书内容围绕Excel 功能区的各个模块,通过对比Excel 的方式来详细讲解每个模块中对应的Python 代码如何实现,轻松、快速地帮助职场人实现报表自动化,提高工作效率。本书主要分为4 个部分:第1 部分介绍Python 基础知识,让读者对Python 中常用的操作和概念有所了解;第2 部分介绍格式相关的设置方法,包括字体设置、条件格式设置等内容;第3 部分介绍各种类型的函数;第4 部分介绍自动化相关的其他技能,比如自动发送邮件、自动打包等操作。
本书适合每天需要做很多报表,希望通过学习报表自动化来提高工作效率的所有读者,包括但不限于分析师、数据运营、财务等人群。

(京东满100减50,快快扫码抢购吧!)
如果喜欢本文
欢迎 在看丨留言丨分享至朋友圈 三连文末福利公众号回复:送书 ,参与抽奖(共3本)
点击下方回复:送书 即可!大家如果有什么建议,欢迎扫一扫二维码私聊小编~
回复:加群 可加入Python技术交流群这篇关于送书|一文教你用 Python 对 Excel文件进行批量操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





