本文主要是介绍【项目实战】记录一次PG数据库迁移至GaussDB测试(下),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一篇分享了安装、迁移,本篇将继续分享迁移前操作、 DRS迁移数据、迁移后一致性检查、问题总结及解决方法。
目录
四、迁移前操作
4.1 源端(PG)
4.2 目标端(GaussDB库)
五、DRS迁移数据
5.1 创建复制用户
5.2创建迁移任务。
六、迁移后一致性检查
6.1使用DRS工具对比
6.2手动对比
七、问题总结及解决方法
7.1 用户迁移
7.2 序列迁移
7.3 分区表迁移
7.4 函数迁移
7.5 外键改造
7.6 索引改造
四、迁移前操作
4.1 源端(PG)
确定迁移的对象
统计源数据库对象
1、统计数据库个数
psql –d postgres -p 15432\l+ --统计数据库名称以及大小
\du –统计数据库所有用户
\c 数据库名称 --
\dn 统计数据中schema的名称
3.1.1.2 创建迁移用户及赋权
创建只读用户用于读取数据库全部对象,该用户用于DRS工具迁移数据
Create user drs_read password ‘Drs_read#2023’;grant usage on schema power_tf,power_reliability,power_work,power_ds,power_tech,power_quality,power_sch,power_common to drs_read;grant usage on schema power_tf,power_reliability,power_work,power_ds,power_tech,power_quality,power_sch,power_common to drs_read;grant select on all sequence in schema power_common,power_tf,power_reliability,power_work,power_ds,power_tech,power_quality,power_sch to drs_read;grant select on all sequences in schema power_work,power_ds,power_tech,power_quality,power_sch to drs_read;grant select on all tables in schema power_work,power_ds,power_tech,power_quality,power_sch to drs_read;4.2 目标端(GaussDB库)
创建复制用户及赋权
gsql –d postgres –p 15432gauss=#create user drs_rep password ‘Drs_rep#2023’;gauss=#alter user drs_rep sysadmin;UGO迁移表结构
使用UGO工具,可以迁移数据库结构、表结构、索引、函数等元数据。
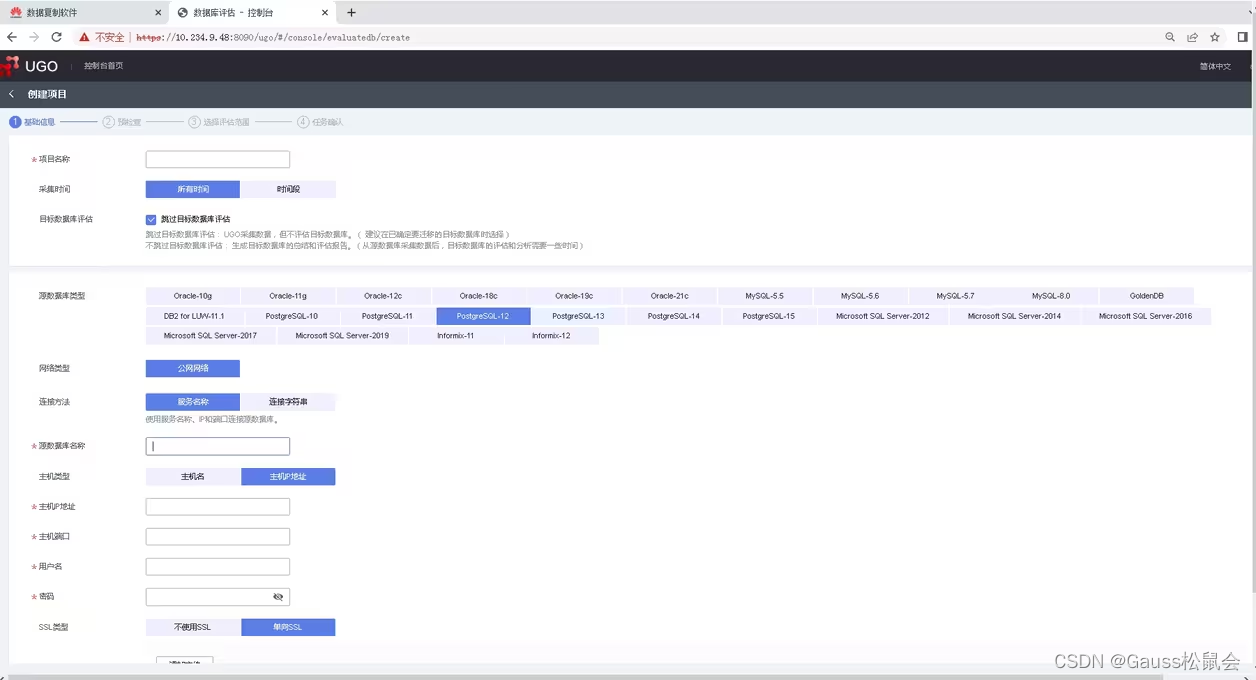
1、创建项目,进行源端数据库评估。

迁移结构后会提示迁移成功和失败的对象百分比,如图所示:
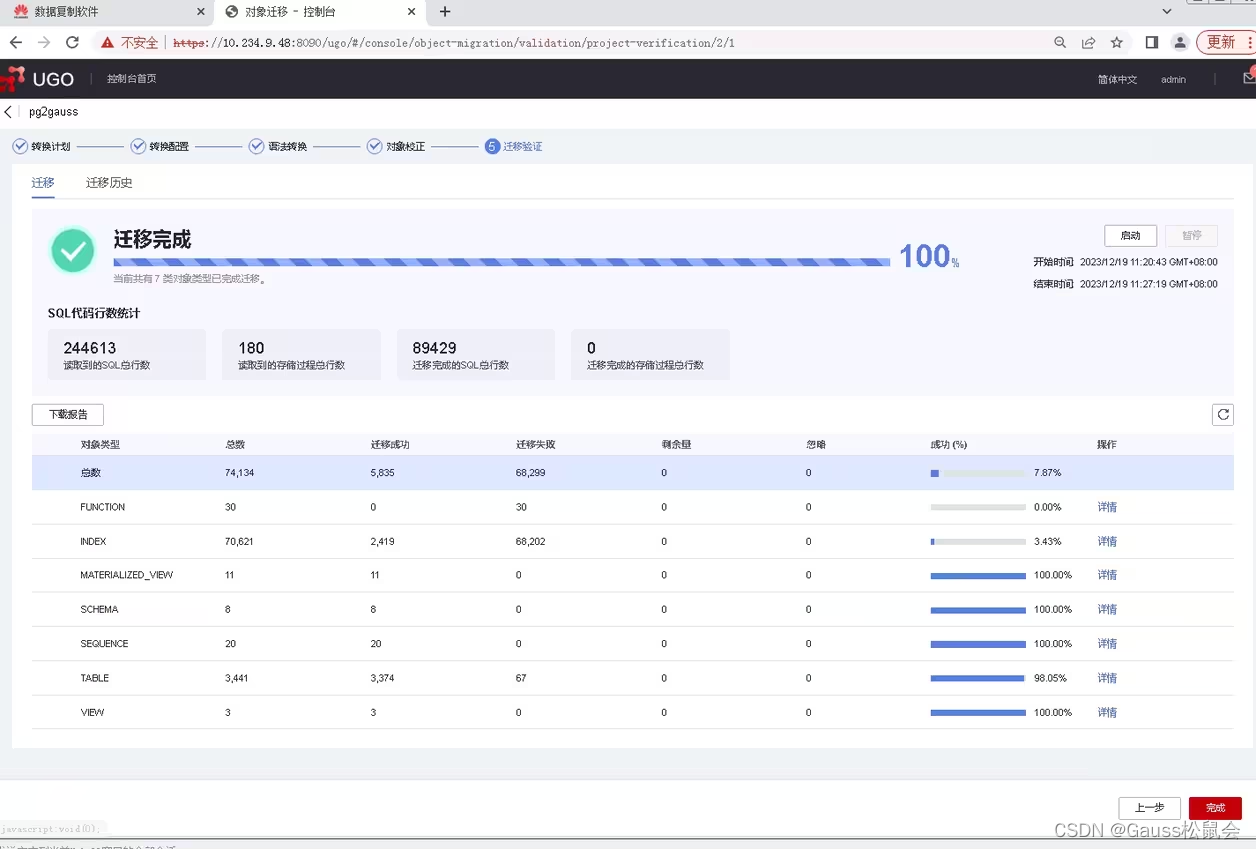
五、DRS迁移数据
5.1 创建复制用户
通过管理员账号登录
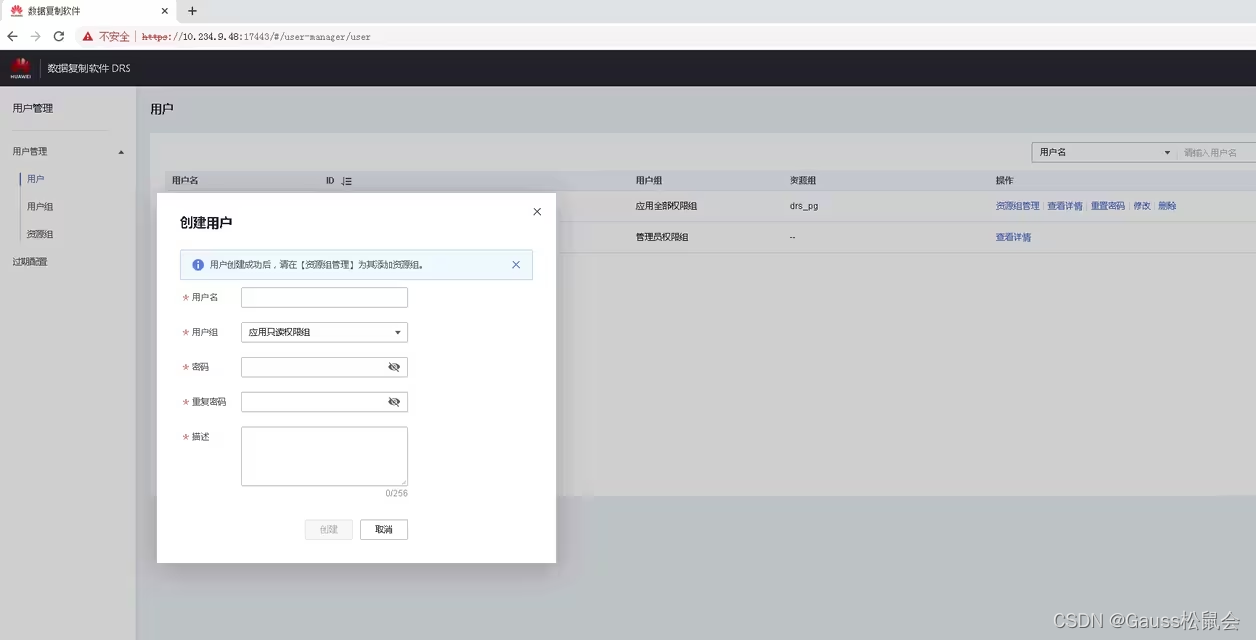
创建资源组

5.2创建迁移任务。
使用复制账号drs登录,创建同步任务
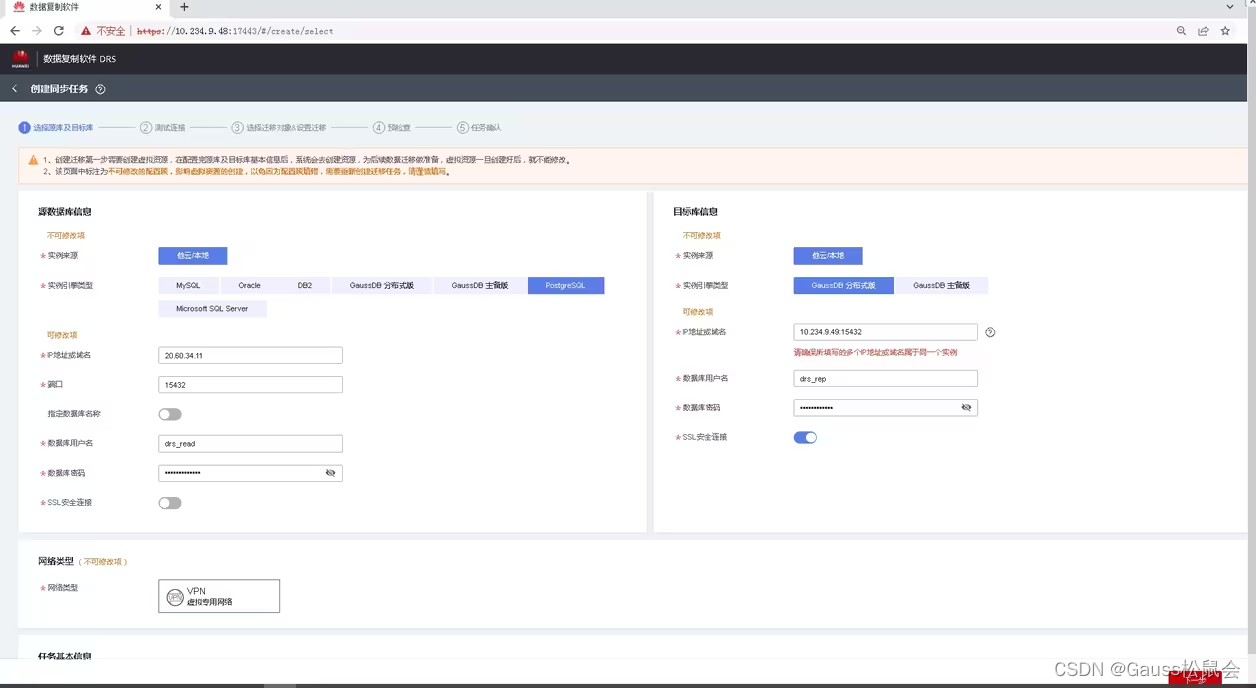

点击测试连接,成功后执行下一步
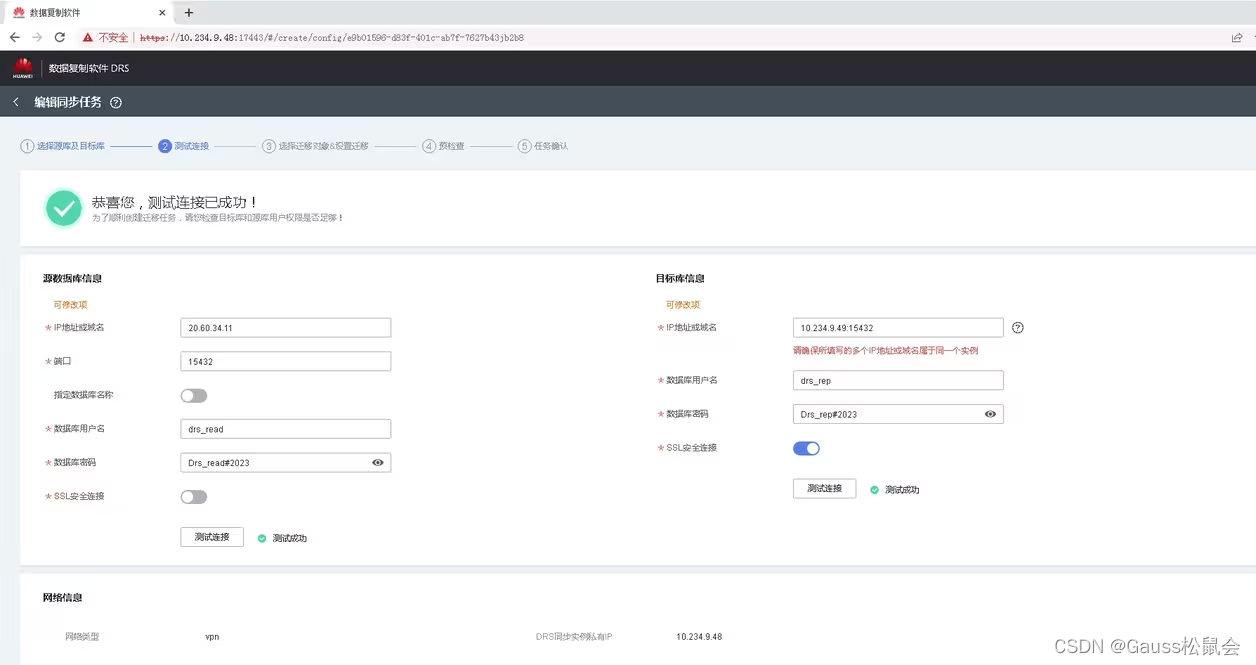
选择要迁移的对象
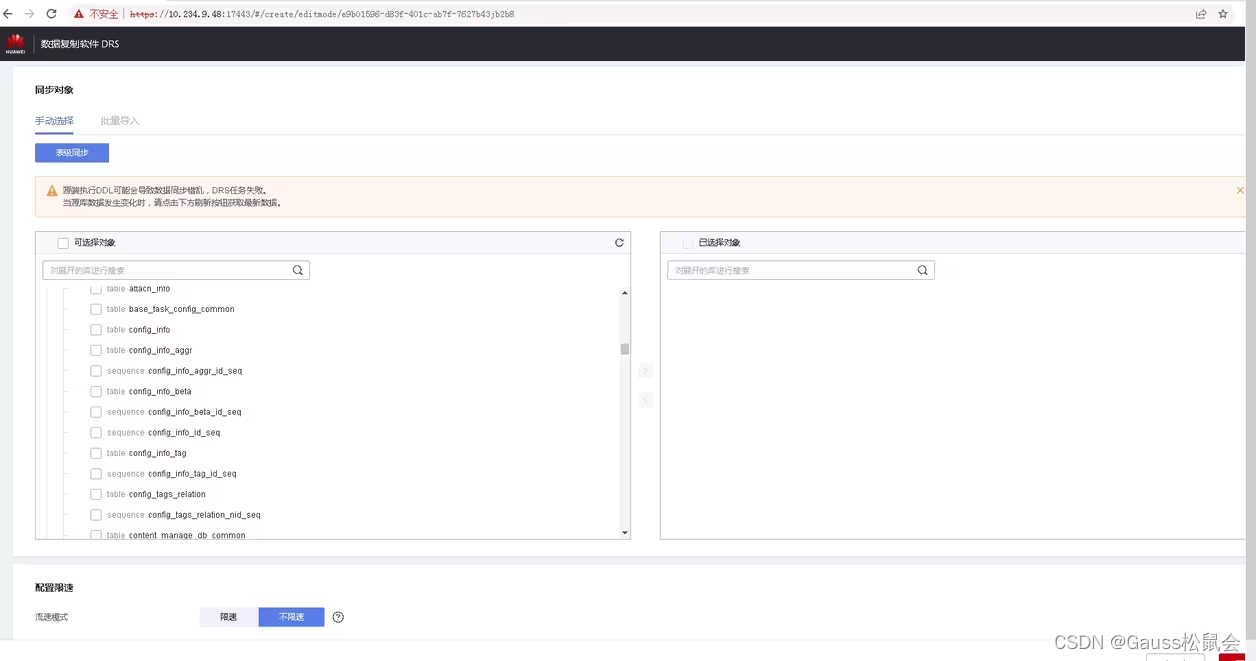
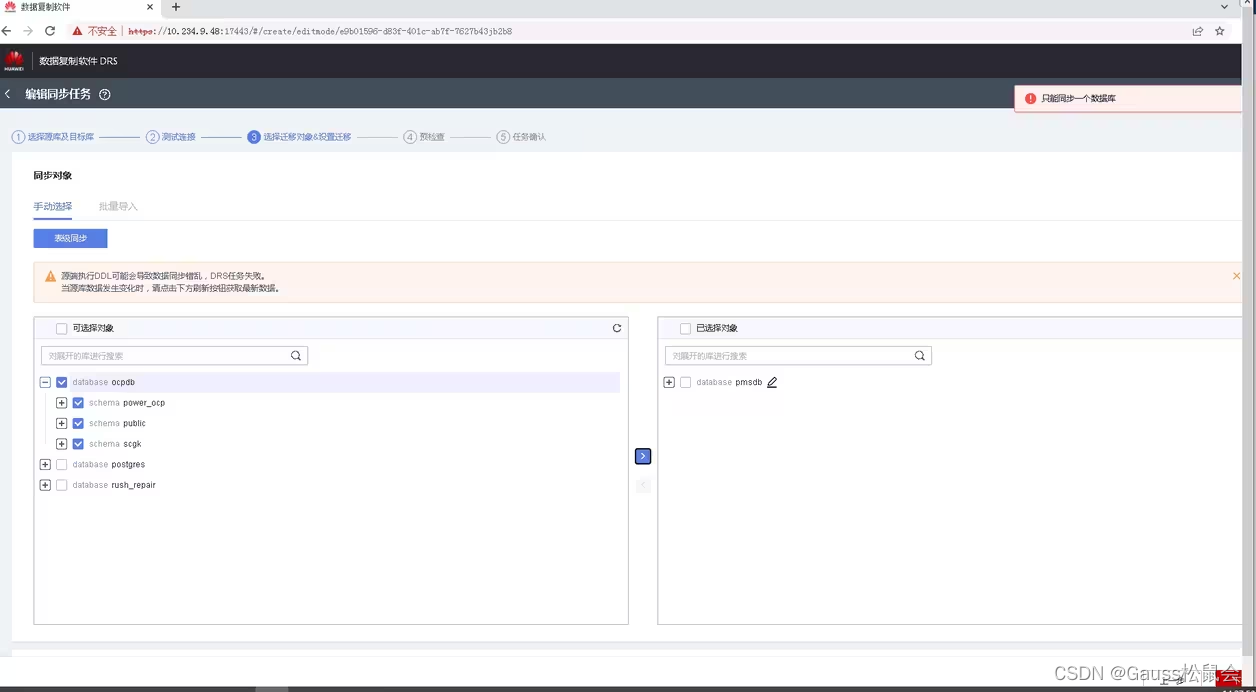
从列表中可以看出,工具仅支持表和序列的迁移,同时只能迁移一个库。下方限速可针对迁移带宽速率进行调整。

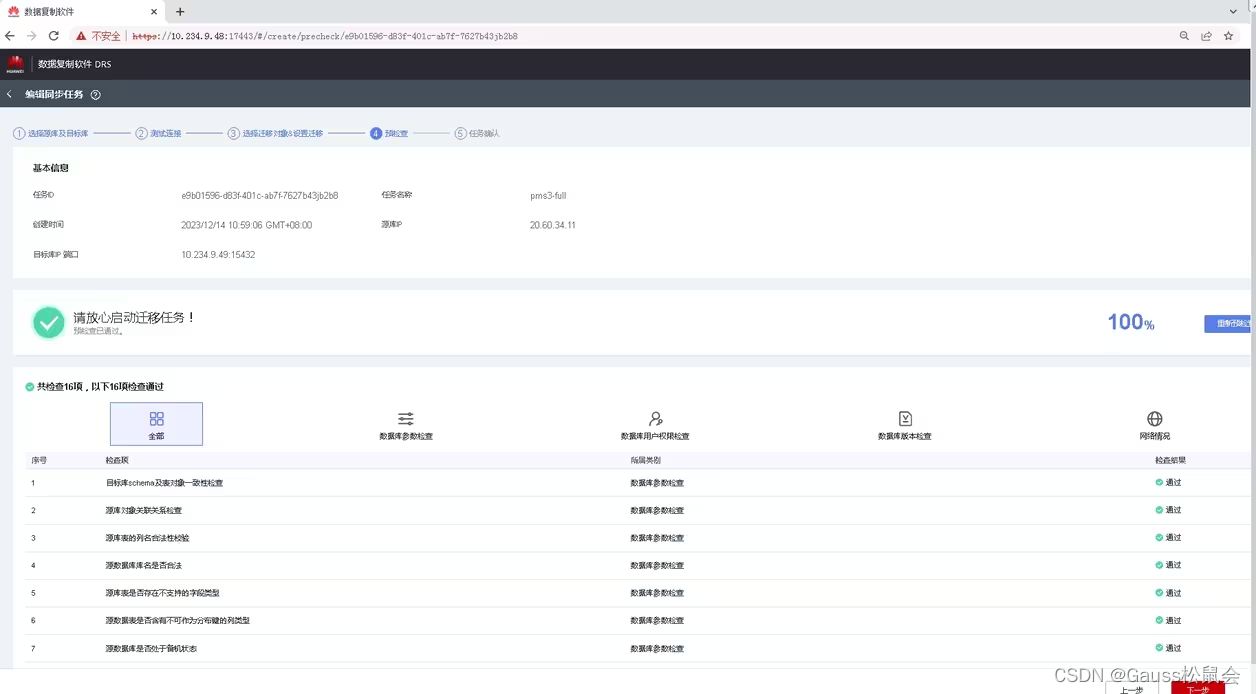
下一步进入迁移前的检查,如果权限不足会提示需要哪些权限,需完成整改后进入下一步
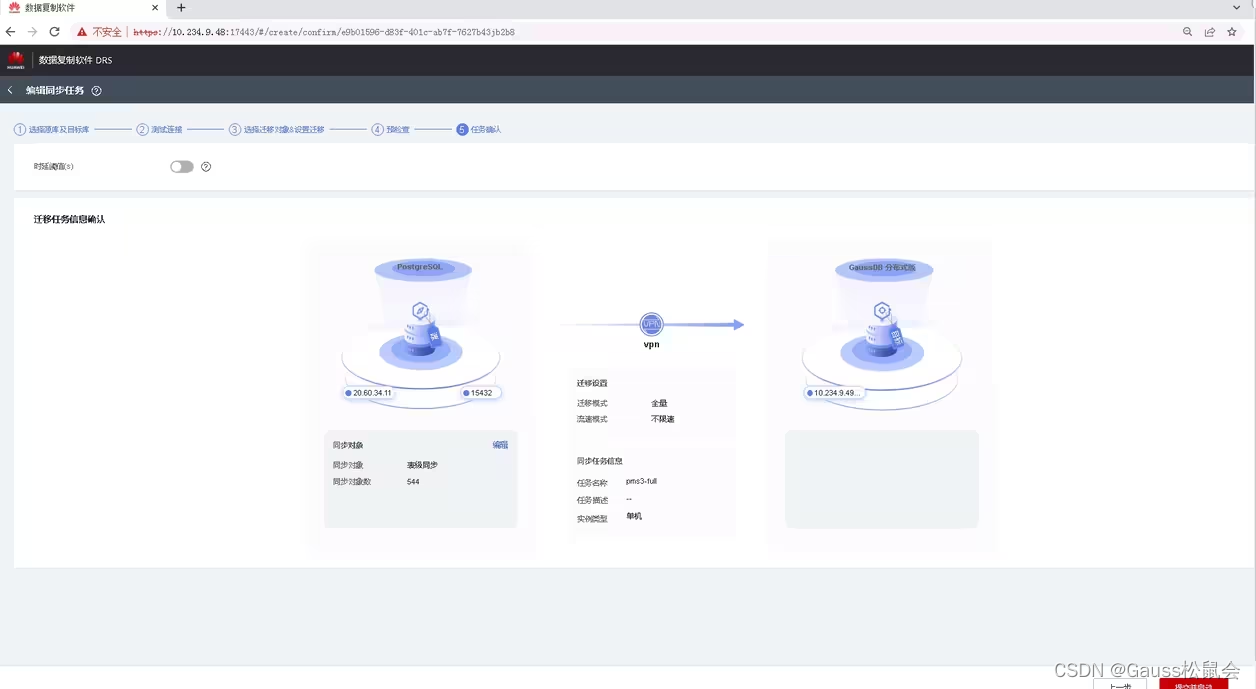
六、迁移后一致性检查
6.1使用DRS工具对比
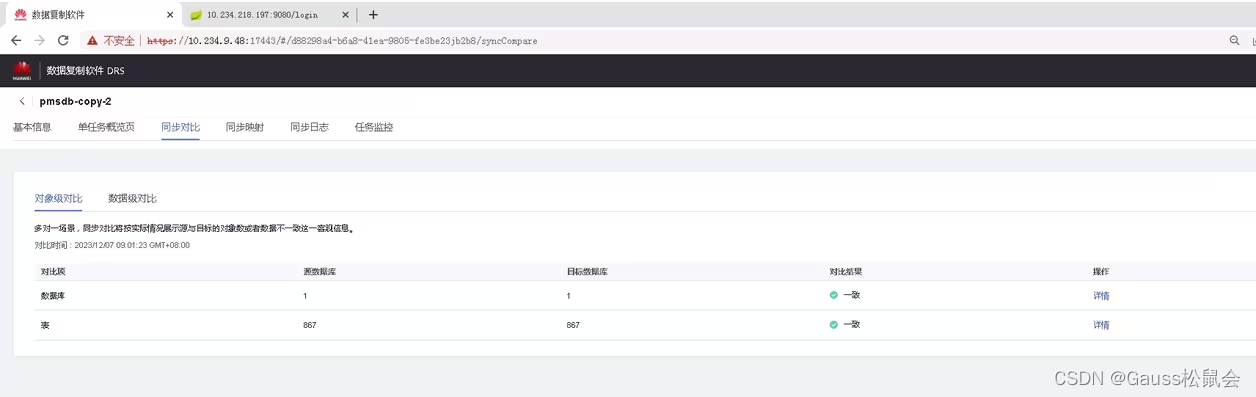
在DRS任务管理中,可以看到数据迁移进度,在任务结束后可以进行数据对比,如图所示
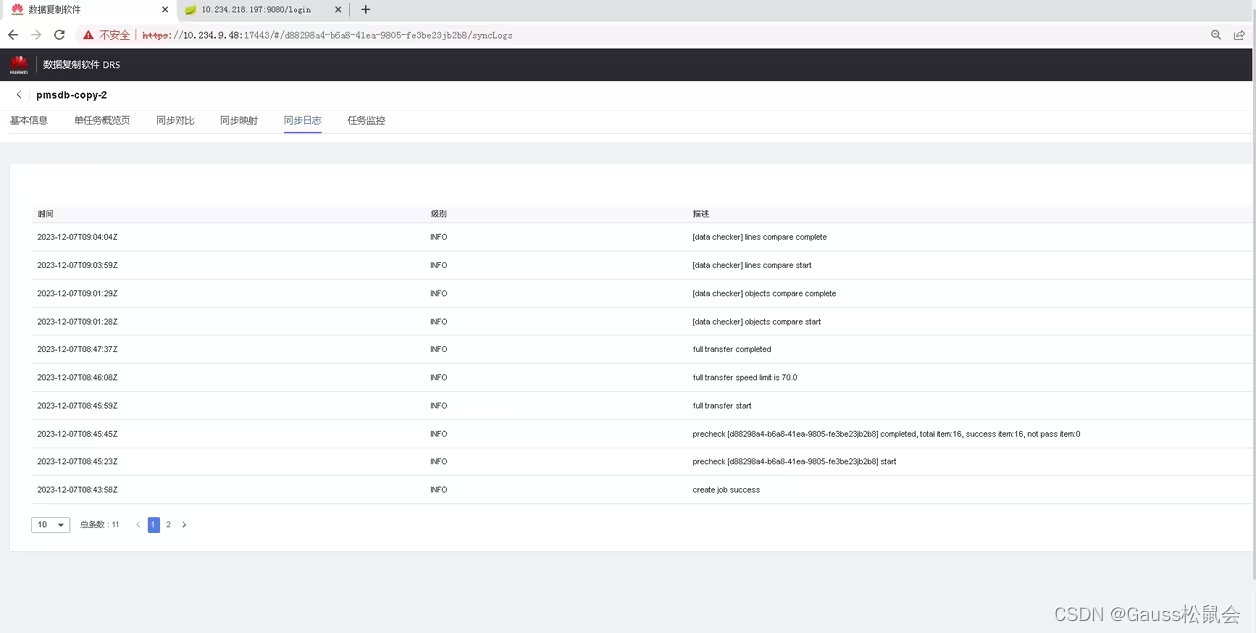
也可以通过日志看到迁移结果,如图所示:
6.2手动对比
通过登录源库和目标库,分别使用脚本统计各个对象数量。
七、问题总结及解决方法
7.1 用户迁移
问题描述:DRS工具和UGO工具无法迁移用户,需在目标库创建用户以及授权。
处理方法:手动创建。
# su – ommgsql –d postgres –p 15432 –rcreate user drmc password 'PAssw0rd_2023';
授权连接测试
gsql -d postgres -p 15432 -U drmc -W PAssw0rd_2023 -r 7.2 序列迁移
问题描述:DRS工具或UGO工具迁移序列到目标库,序列会重新从初始值开始递增,如果业务切换至目标库会导致采用序列做为主键的列值冲突
解决方法:列举所有scheme的序列,收集当前序列值,在目标库重置当前值。
源库收集序列当前值select * from pg_sequence;收集每个序列last_value目标库重置每个序列的当前值Select setval(‘序列名称’,‘当前值’);Gsql –p 15432 –d postgres -rGaussdb=#\d+ 序列名---查看当前值7.3 分区表迁移
问题描述:DRS工具在迁移分区表时会将分区表转化成普通表。UGO在PG迁移至GaussDB数据库中,由于语法不兼容问题,需要手动修改语法来实现。
解决方法:1、手动创建分区表,然后导入数据。
# su – opostgres收集所有分区表select nmsp_parent.nspname asparent_schema,parent.relname as parent,nmsp_child.nspname as child_schema,child.relname as child_namefrom pg_inheritsjoin pg_class parenton pg_inherits.inhparent=parent.oidjoin pg_class childon pg_inherits.inhrelid=child.oidjoin pg_namespace nmsp_parenton nmsp_parent.oid=parent.relnamespacejoin pg_namespace nmsp_childon nmsp_child.oid=child.relnamespace;手动创建分区表示例:CREATE TABLE power_sch.abc (obj_id NVARCHAR2(42) NOT NULL,sun_year_month NVARCHAR2(42)CONSTRAINT " abc_pkey" PRIMARY KEY (sun_year_month, obj_id))PARTITION BY LIST (sun_year_month);添加分区:alter table power_sch.abc add partition abc_201201 VALUES ('201201');7.4 函数迁移
问题描述:支持迁移普通自定义函数,依赖PG插件的函数需手动改写。
解决方法:1、手动改写实现相关功能。
select a.usename,b.proname from pg_user a,pg_proc b where a.usesysid=b.proowner and a.usename<>'postgres';7.5 外键改造
问题描述:在迁移中发现GaussDB分布式数据库不支持外键,需要将表的外键用触发器形式实现,在UGO迁移过程中提示:FOREIGN KEY …REFERENCES constraint is not yet supported.
解决方法1:使用GaussDB集中式支持外键约束。
解决方法2:GaussDB分布式数据库处理外键约束的方法。
场景1:一个父表,一个子表,trigger完全等价
1.创建两个表,一个主表和一个从表,主表中包含主键列,从表中包含外键列。
CREATE TABLE parent (id INT PRIMARY KEY,name VARCHAR(50) NOT NULL);CREATE TABLE child (id INT,parent_id INT,name VARCHAR(50) NOT NULL,FOREIGN KEY (parent_id) REFERENCES parent(id)); 2.向主表中插入数据。
INSERT INTO parent (id, name) VALUES (1, 'John');INSERT INTO parent (id, name) VALUES (2, 'Jane');INSERT INTO parent (id, name) VALUES (3, 'Jane'); 3.向从表中插入数据,其中外键列的值应该与主表中的主键列的值相匹配。
INSERT INTO child (id, parent_id, name) VALUES (1, 1, 'Tom');INSERT INTO child (id, parent_id, name) VALUES (2, 2, 'Jerry');4.尝试插入一条不匹配的从表数据,即外键列的值与主表中不存在的主键列的值相匹配。此时应该抛出异常。
INSERT INTO child (id, parent_id, name) VALUES (4, 4, 'Spike');---结果:ORA-02291: 违反完整约束条件 (UGO.SYS_C0087731) - 未找到父项关键字5.update子表,无法成功
update child set parent_id=22 where id=2;---结果:ORA-02291: 违反完整约束条件 (UGO.SYS_C0087731) - 未找到父项关键字1.2GaussDB替代方案:分布式不支持外键,使用trigger保证外键约束的一致性,如果依赖的父表存在,insert,不存在raise
1.创建两个表,一个主表和一个从表,主表中包含主键列,从表中包含外键列。
CREATE TABLE parent (id INT PRIMARY KEY,name VARCHAR(50) NOT NULL);CREATE TABLE child (id INT PRIMARY KEY,parent_id INT,name VARCHAR(50) NOT NULL/*,FOREIGN KEY (parent_id) REFERENCES parent(id)*/ --注释掉外键);使用trigger实现等价功能--外键一致性--触发函数create or replace function func_child() return triggerasid_values int;BEGINSELECT COUNT(id) INTO id_valuesFROM parentWHERE id = NEW.parent_id;IF id_values=0 THENRAISE EXCEPTION '%' , 'Foreign key constraint violated because the id column value does not exist in the parent table.';elseRETURN NEW;END IF;end;/--触发器DROP TRIGGER if exists tri_child on child;CREATE TRIGGER tri_childbefore insert or update on childFOR EACH ROWEXECUTE PROCEDURE func_child();2.向主表中插入数据。
INSERT INTO parent (id, name) VALUES (1, 'John');INSERT INTO parent (id, name) VALUES (2, 'Jane');INSERT INTO parent (id, name) VALUES (3, 'Jane'); 3.向从表中插入数据,其中外键列的值应该与主表中的主键列的值相匹配。
INSERT INTO child (id, parent_id, name) VALUES (1, 1, 'Tom');INSERT INTO child (id, parent_id, name) VALUES (2, 2, 'Jerry'); 4.尝试插入一条不匹配的从表数据,即外键列的值与主表中不存在的主键列的值相匹配。此时应该抛出异常。
INSERT INTO child (id, parent_id, name) VALUES (4, 4, 'Spike');ugo=> INSERT INTO child (id, parent_id, name) VALUES (4, 4, 'Spike');ERROR: Foreign key constraint violated because the id column value does not exist in the parent table. 5.update子表,无法成功
update child set parent_id=22 where id=2;ugo=> update child set parent_id=22 where id=2;ERROR: Foreign key constraint violated because the id column value does not exist in the parent table. 场景2:多个父表,一个子表,trigger完全等价
2.1多外键:
1.创建两个表,两个主表和一个从表,主表中包含主键列,从表中包含外键列。
drop table parent;CREATE TABLE parent (id INT PRIMARY KEY,name VARCHAR(50) NOT NULL);drop table parent1;CREATE TABLE parent1 (id INT ,idname VARCHAR(50) PRIMARY KEY);drop table child;CREATE TABLE child (id INT ,parent_id INT,name VARCHAR(50) NOT NULL,FOREIGN KEY (parent_id) REFERENCES parent(id),FOREIGN KEY (name) REFERENCES parent1(idname));2.向主表中插入数据。
INSERT INTO parent (id, name) VALUES (1, 'John');INSERT INTO parent (id, name) VALUES (2, 'Jane');INSERT INTO parent (id, name) VALUES (3, 'Jane');INSERT INTO parent1 (id, idname) VALUES (1, 'John1');INSERT INTO parent1 (id, idname) VALUES (2, 'Jane1');INSERT INTO parent1 (id, idname) VALUES (3, 'xxJane1');3.向从表中插入数据,其中外键列的值应该与主表中的主键列的值相匹配。
INSERT INTO child (id, parent_id, name) VALUES (1, 1, 'John1');INSERT INTO child (id, parent_id, name) VALUES (2, 2, 'xxJane1'); 4.尝试插入一条不匹配的从表数据,即外键列的值与主表中不存在的主键列的值相匹配。此时应该抛出异常。
INSERT INTO child (id, parent_id, name) VALUES (1, 1, 'Tom');INSERT INTO child (id, parent_id, name) VALUES (1, 4, 'John1');INSERT INTO child (id, parent_id, name) VALUES (4, 4, 'Spike');---结果:ORA-02291: 违反完整约束条件 (UGO.SYS_C0087731) - 未找到父项关键字5.update子表,无法成功
update child set parent_id=22 where id=2;---结果:ORA-02291: 违反完整约束条件 (UGO.SYS_C0087731) - 未找到父项关键字 2.2GaussDB替代方案:分布式,使用trigger完全等价
1.创建两个表,两个主表和一个从表,主表中包含主键列,从表中包含外键列。
drop table parent;CREATE TABLE parent (id INT PRIMARY KEY,name VARCHAR(50) NOT NULL);drop table parent1;CREATE TABLE parent1 (id INT ,idname VARCHAR(50) PRIMARY KEY);drop table child;CREATE TABLE child (id INT ,parent_id INT,name VARCHAR(50) NOT NULL/*,FOREIGN KEY (parent_id) REFERENCES parent(id),FOREIGN KEY (name) REFERENCES parent1(idname)*/);trigger实现等价功能--触发函数create or replace function func_child() return triggerasparent_id_values int;name_values int;BEGINSELECT COUNT(id) INTO parent_id_valuesFROM parentWHERE id = NEW.parent_id;SELECT COUNT(idname) INTO name_valuesFROM parent1WHERE idname = NEW.name;IF parent_id_values=0 or name_values=0 THENRAISE EXCEPTION '%', 'Foreign key constraint violated because the id column value and idname column value does not exist in the parent table and parent1 table .';elseRETURN NEW;end if;end;/--触发器DROP TRIGGER if exists tri_child on child;CREATE TRIGGER tri_childbefore insert or update on childFOR EACH ROWEXECUTE PROCEDURE func_child(); 2.向主表中插入数据。
INSERT INTO parent (id, name) VALUES (1, 'John');INSERT INTO parent (id, name) VALUES (2, 'Jane');INSERT INTO parent (id, name) VALUES (3, 'Jane');INSERT INTO parent1 (id, idname) VALUES (1, 'John1');INSERT INTO parent1 (id, idname) VALUES (2, 'Jane1');INSERT INTO parent1 (id, idname) VALUES (3, 'xxJane1'); 3.向从表中插入数据,其中外键列的值应该与主表中的主键列的值相匹配。
INSERT INTO child (id, parent_id, name) VALUES (1, 1, 'John1');INSERT INTO child (id, parent_id, name) VALUES (2, 2, 'xxJane1');4.尝试插入一条不匹配的从表数据,即外键列的值与主表中不存在的主键列的值相匹配。此时应该抛出异常。
INSERT INTO child (id, parent_id, name) VALUES (1, 1, 'Tom');INSERT INTO child (id, parent_id, name) VALUES (1, 4, 'John1');INSERT INTO child (id, parent_id, name) VALUES (4, 4, 'Spike');ugo=> INSERT INTO child (id, parent_id, name) VALUES (1, 1, 'Tom');ERROR: Foreign key constraint violated because the id column value and idname column value does not exist in the parent table and parent1 table .ugo=> INSERT INTO child (id, parent_id, name) VALUES (1, 4, 'John1');ERROR: Foreign key constraint violated because the id column value and idname column value does not exist in the parent table and parent1 table .ugo=> INSERT INTO child (id, parent_id, name) VALUES (4, 4, 'Spike');ERROR: Foreign key constraint violated because the id column value and idname column value does not exist in the parent table and parent1 table . 5.update子表,不成功
update child set parent_id=22 where id=1;update child set name='xiaowang' where parent_id=2;ERROR: Foreign key constraint violated because the id column value and idname column value does not exist in the parent table and parent1 table .7.6 索引改造
问题描述1:目标库采用GaussDB分布式数据库时,在使用UGO工具迁移索引过程中,提示Cannot create index whose evaluation cannot be enforced to remote nodes.
问题描述2:在使用UGO工具迁移索引过程中,分区表索引无法迁移,需要手动获取源端索引定义手动创建。
处理方法1:到数据库中查找表对象的分布键,添加分布列id到索引个。
示例:power_ocp.config_info_bak对象,可以在数据库中使用
\d+ power_ocp.config_info_bak来查找该对象的分布键,即下图红线中显示的Distribute By后的关键字
处理方法2:手动获取源端分区表索引定义
Select * from pg_indexes where tablename in (‘’,’’); 手动执行索引定义
PG数据库迁移至GaussDB测试分享到此结束,欢迎大家一起交流学习~
这篇关于【项目实战】记录一次PG数据库迁移至GaussDB测试(下)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





