本文主要是介绍深度学习 Lecture 7 迁移学习、精确率、召回率和F1评分,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、迁移学习(Transfer learning)
用来自不同任务的数据来帮助我解决当前任务。
场景:比如现在我想要识别从0到9度手写数字,但是我没有那么多手写数字的带标签数据。我可以找到一个很大的数据集,比如有一百万张图片的猫、狗、汽车和人等1000个类,那我就可以在这个大型数据集上用这一百万张图片作为输入,训练一个模型来学会识别这1000个不同的类别。
比如我训练出来后,长这样:
这里有w,b参数
那接下来,我就可以把前面的输入层和隐藏层全部照原来的不动,把输出层更改为10个神经元,即:
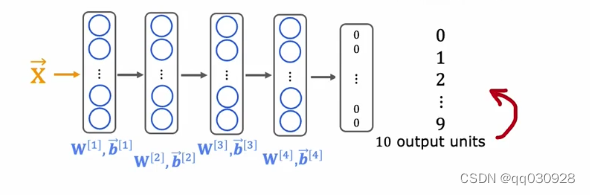
10个神经元分别对应0-9的10个数字。
但注意这里的w5和b5需要改变,因为神经元改变了,所以要用前四层的参数进行训练,得出新的w5和b5。
也就是说,迁移学习后,有两种选择:

选项1适合数据集较小的情况。
选项卡2适合数据集较大的情况。
这种算法就叫迁移学习,就是把通过另一个训练好的训练模型参数迁移到现有的模型中来,这样对新神经网络的参数很有帮助,因为只需要再让算法学习一下,就能达到很好的效果了。
在大型数据集上训练,然后在较小的数据集上进一步调参(也叫微调(fine tuning),这两个步骤叫监督预训练(supervised pretraining)
而迁移学习的一个好处是,我可能不需要进行监督预训练。
对应很多神经网络来说,已经有研究人员在大数据集上训练了一个效果很好的神经网络并发在了网上,那比起从头开始,我们可以下载别人训练好的神经网络,把自己的输出层替换原有的输出层,并用自己的数据集做一点微调即可得到一个表现良好的神经网络。
但是要注意!对应预训练和调参这两步,使用的图像必须是同个输入尺寸的,并且选择的别人的模型也要是图像识别的。也就是说,如果你要做音频识别,那你要找的神经网络也是在音频数据上预训练过的神经网络。
二、机器学习项目的整个周期
第一步:确定项目的范围:
确定这项目是什么,什么是你想做的
第二步:收集数据
确定需要哪些数据来训练你的机器学习系统,然后去收集
第三步:训练模型
进行误差分析,进行迭代发展,看训练效果是否不好, 不好的话找原因,比如回去收集更多的数据这样。
第四步:部署系统
应用到现实中,并且要跟进模型的性能,如果模型性能出现问题,要及时维护。
PS: 注意,误差最小的模型不一定代表模型准确率最高。
原因:比如当你的模型在预测一个人是否有罕见病的时候(罕见病发病率0.5%),而你的蠢模型只会一直在输出该人无罕见病,那模型准确率就是99.5%;但是如果你自己训练的模型准确率是99.2%,但是它不会像傻子一样一直在输出该人无罕见病,可能更有用这个时候你怎么判断哪个模型更好呢?(这种情况叫数据集倾斜问题)
解决方式是使用精确率(Precison)和召回率(Recall)作为错误的度量。
三、精确率和召唤率
要理解这两个概念,首先要知道什么是true positive, false positive, false negative和true negative。
举个例子:
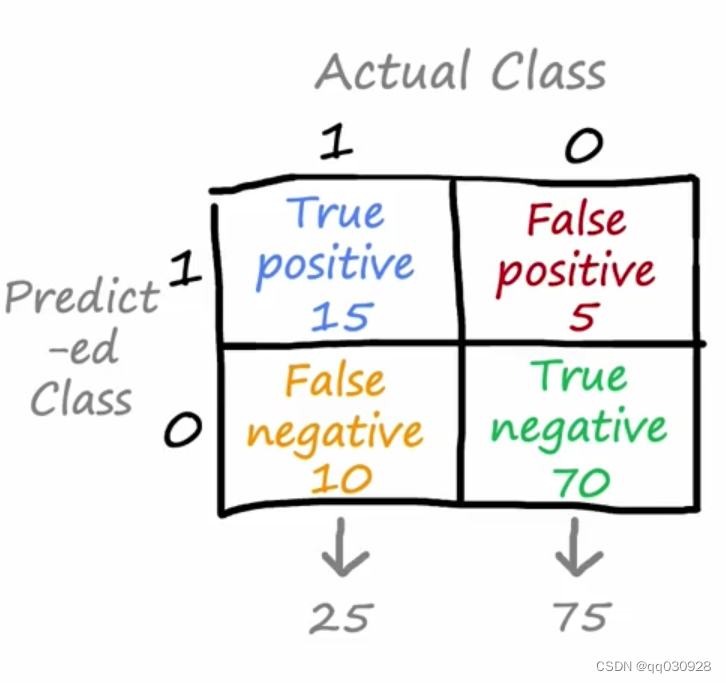
这是个混淆矩阵,现在我们在预测一个罕见病,横轴代表实际的类,竖轴代表预测出来的类。
如果预测的结果和实际结果一样,这个就叫true;不一样就叫false;
那positive和negative就是1和0的区别,表示是否有疾病。
所以,精确率:
true positive的值除以被归为positive的样本的值(也就是在所有你预测的阳性样本中,真正是真样本的比率)
召回率:
true positive的值除actual positived的值(也就是true positive的值加上false negative的值)
这两个值能够帮我们判断是不是模型一直在输出0(也就是我们上面提及的情况)
因为如果一直都在输出0,那精确率和召回率就都是0.
所以如果训练的模型是罕见病的时候,一定需要注意这两个数字够不够高,如果都比较高,就能说明我们的学习算法是有效的。
总结:
高精度:已知算法诊断来访者有这种疾病,后面发现大多数来访者确实都有这种疾病,那就说是高精度。(预测为正的样本中有多少是真的预测正确了(找得对))
高召回:已知来访者有这种疾病,后面发现算法能在很大程度上诊断出他们患有这种疾病,这就是找的全。
那如何权衡精度和召回率呢?
四、精度和召回率的权衡
通常我们会将逻辑回归的输出阈值设置为0.5,但假如我们只有在觉得非常确信的情况下才预测y = 1的话,我们可以选择把阈值设置更高,比如0.7,也就是说,此时要预测y = 1至少要有70%的把握了,这样就能提高预测的精度了。注意,阈值的设置要同步,也就是说,此时预测y=1和y=0的阈值都是0.7。
但是这样的话,精度提高了,就会导致更低的召回率,因为预测的次数变少了。所以在所有的患者中,我们能正确诊断出患病的人会更少。
同理,那降低阈值就是提高预测的召回率,也就是说,允许找出更多的病例。
那权衡这两个值的话,就要把不同阈值对于的精确率和召回率的图画出来:
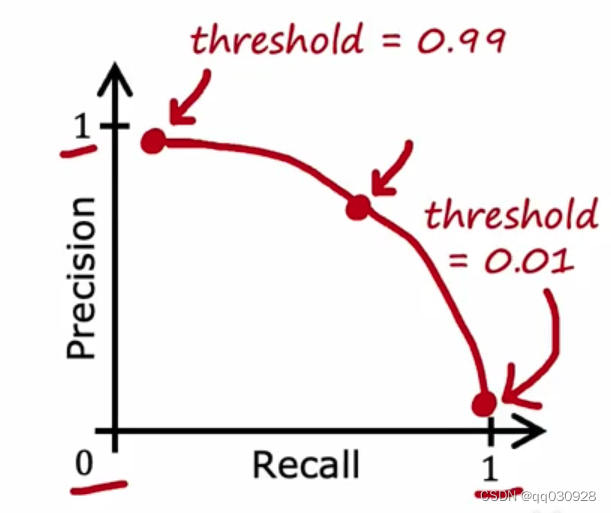
而且注意,不能用交叉验证法选出阈值,因为是由你来选择最佳的点。
所以对于大多数算法程序而言,最终要做的是手动选择一个阈值来权衡精度和召回率。
但是如果你想要自动权衡精度和召回率,而不是自己来手动选择阈值的话,还可以使用
F1评分(F1 Score):它可以自动结合精度和召回率,帮你选择最佳权衡值。
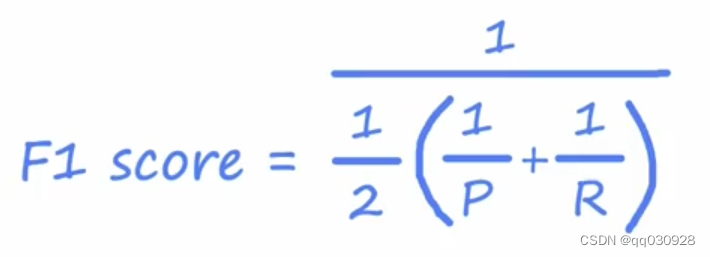
这个计算结果也叫调和平均数(harmonious means)
也就是说,可以通过这个公式,来对召回率和精度进行计算,得出F1评分,选出最佳的权衡组合。得分越高,哪种算法就越好。
这篇关于深度学习 Lecture 7 迁移学习、精确率、召回率和F1评分的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





