本文主要是介绍diffusion初探——使用hugging face镜像网站所遇到的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
序言
近期hugging face官网无法直接从国内访问(可用梯子解决),故无法像之前方法在服务器上直接访问,本文采取的方法是:使用国内替换原hugging face网站,https://hf-mirror.com/。
但这样势必会带来一些问题,这里将使用DreamBooth生成“土豆先生”作为示例,逐一描述本人遇到的问题:(本人刚接触diffusion,不喜勿喷)
问题
1.登录问题
from huggingface_hub import notebook_login
notebook_login()
以往运行上述代码,便可弹出一个窗口,输入token即可登录,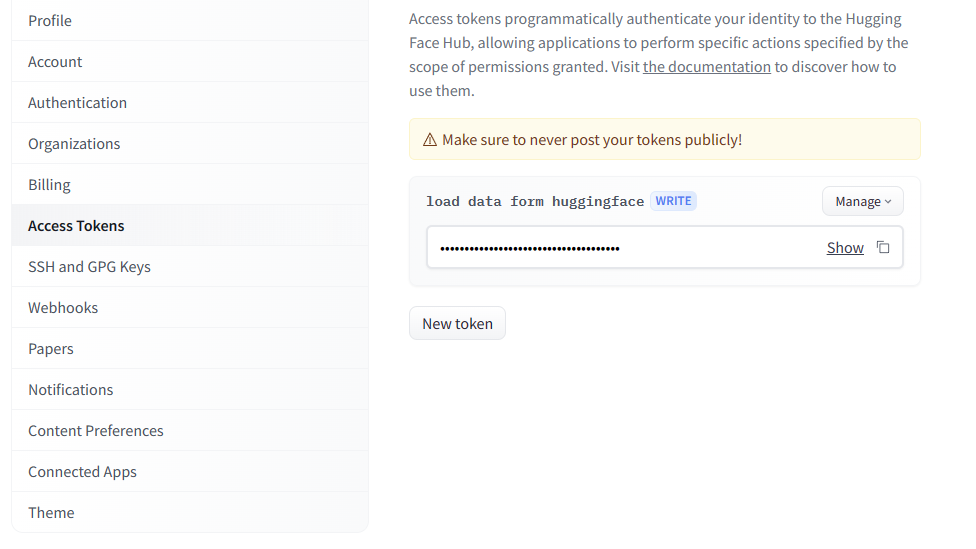
而现在报错:
查找原因发现是
“Ipywidgets (Vbox) not showing up on Jupyter notebook”
但并非Ipywidgets,笔者尝试了重新安装Ipywidgets和安装有关插件,但并没有效果,最后想到是网络原因,更改镜像源:
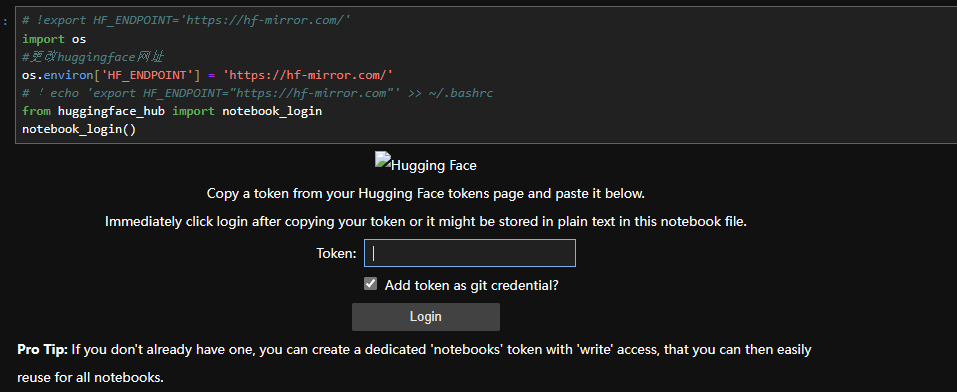
import os
#更改huggingface网址
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com/'
# 每次使用均要重新设置,不如写入.bashrc,则无需反复写入(linux代码如下:)
!echo 'export HF_ENDPOINT="https://hf-mirror.com"' >> ~/.bashrc
2.预训练参数载入问题
在使用DiffusionPipeline.from_pretrained时,发现无法找到对应的url,即:url为https://hf-mirror.com//api/models/sd-dreambooth-library/mr-potato-head,但实际是https://hf-mirror.com/sd-dreambooth-library/mr-potato-head,多了“/api/models/”,尝试通过继承的方式解决,未果!
有知道解决的小伙伴在评论区留言,感谢!
from diffusers import DiffusionPipeline
model_id = "sd-dreambooth-library/mr-potato-head"
pipe = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to(device
)

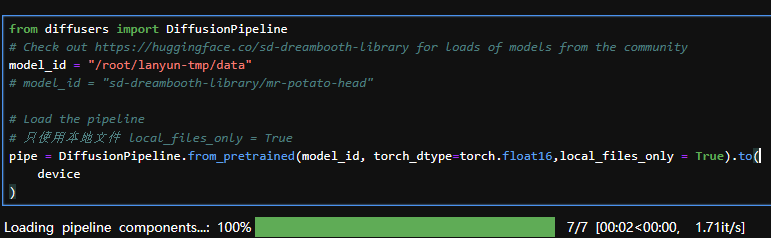
遂采用离线下载的方式进行实现:(注意只使用本地文件 local_files_only = True)
from diffusers import DiffusionPipeline
# Check out https://huggingface.co/sd-dreambooth-library for loads of models from the community
model_id = "/root/lanyun-tmp/data"
# model_id = "sd-dreambooth-library/mr-potato-head"# Load the pipeline
# 只使用本地文件 local_files_only = True
pipe = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16,local_files_only = True).to(device
)
3.离线下载问题
主要推荐 使用huggingface-cli下载数据,–resume-download是模型名字,–local-dir是本地地址。
!huggingface-cli download --resume-download sd-dreambooth-library/mr-potato-head --local-dir /root/lanyun-tmp/data
使用huggingface-cli下载数据
huggingface-cli 隶属于 huggingface_hub
库,不仅可以下载模型、数据,还可以可以登录huggingface、上传模型、数据等。huggingface-cli
属于官方工具,其长期支持肯定是最好的。优先推荐!
–local-dir-use-symlinks False
参数可选,因为huggingface的工具链默认会使用符号链接来存储下载的文件,导致–local-dir指定的目录中都是一些“链接文件”,真实模型则存储在~/.cache/huggingface下,如果不喜欢这个可以用
–local-dir-use-symlinks False取消这个逻辑。
参考链接:https://zhuanlan.zhihu.com/p/663712983
但笔者在–local-dir-use-symlinks
False时,发现其只会存储在~/.cache/huggingface下,且不完整,故取消了。
使用git lfs下载
方法简单但网络连接不好:
sudo apt-get install git-lfs
git clone https://hf-mirror.com/johnowhitaker/ddpm-butterflies-32px
推荐先GIT_LFS_SKIP_SMUDGE=1 git clone(跳过下载 LFS 文件)
其次再对大文件用第三方、成熟的多线程下载工具,Linux 和 Mac OS 推荐hfd脚本+aria2c,Windows 推荐
IDM。用第三方工具的好处是,下载上百GB的模型、数据集,你可以放个一晚上,第二天就下载好了,而不是第二天早晨发现下载了10%断了还得继续。
笔者下载七十多MB的.bin文件还给我断了,只下小的还行,特别是只有几个LFS文件时,简单好用!
代码:
# !export HF_ENDPOINT='https://hf-mirror.com/'
import os
#更改huggingface网址
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com/'
# !echo 'export HF_ENDPOINT="https://hf-mirror.com"' >> ~/.bashrc
from huggingface_hub import notebook_login
notebook_login()%pip install -U diffusers datasets transformers accelerate ftfy pyarrow==9.0.0 matplotlibimport numpy as np
import torch
import torch.nn.functional as F
from matplotlib import pyplot as plt
from PIL import Image
# Mac users may need device = 'mps' (untested)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#数据下载
!huggingface-cli download --resume-download sd-dreambooth-library/mr-potato-head --local-dir /root/lanyun-tmp/data # 观察采样步骤数量和结果关系
prompt = "an abstract oil painting of sks mr potato head by picasso"
# prompt = "an beautiful lady walk in the street on a sunny day"
#num_inference_steps 采样步骤数量,guidance_scale 输出与提示的匹配程度
num_list_length = np.arange(30,130,10)
images = []
for i in num_list_length:image = pipe(prompt, num_inference_steps=i, guidance_scale=0.7).images[0]images.append(image)#可视化
# make_grid(images)
import matplotlib.pyplot as plt
# 创建一个新的 matplotlib 图片和子图,设置每个子图的大小为10x10
fig, axs = plt.subplots(1, len(images), figsize=(10*len(images), 10))
# 遍历每个图片和对应的子图
for img, ax, size in zip(images, axs, num_list_length):# 显示图片ax.imshow(img)# 移除坐标轴ax.axis('off')# 在图片下方添加标题ax.set_title(str(size),fontsize=20)
# 显示所有的子图
plt.show()
# 保存图片到文件
fig.savefig('采样步骤数量和结果关系.png')

这篇关于diffusion初探——使用hugging face镜像网站所遇到的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






