本文主要是介绍<计算机网络自顶向下> P2P应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
纯P2P架构
- 没有或者极少一直运行的Server,Peer节点间歇上网,每次IP地址都可能变化
- 任意端系统都可以直接通信
- 利用peer的服务能力,可扩展性好
- 例子:文件分发; 流媒体; VoIP
- 类别:两个节点相互上载下载文件,互通有无,构成覆盖网overlay(这种网络是逻辑的网络因为是在应用层的网络)
- 非结构化P2P: 随机连接(集中化目录)
- DHT(结构化)P2P: 形成特定的结构比如环或者树
- 缺点:难以管理,服务器动态,上载能力动态
- 问题:解决方法有集中,分散,半分散
- 如何定位所需资源
- 如何处理对等方的加入与离开
C/S VS P2P
从一台服务器分发文件(大小F)到N个peer需要多少时间:
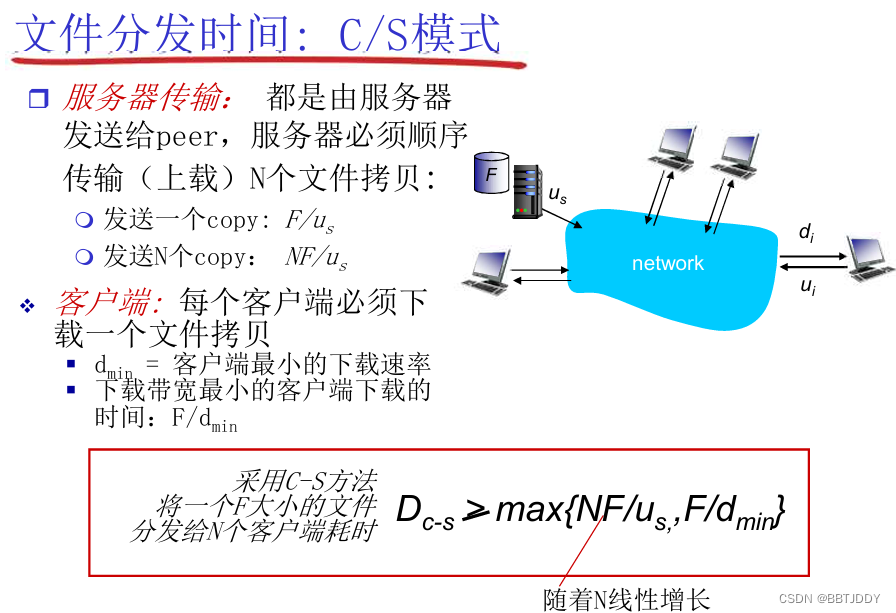 |  |

非结构化P2P
- P2P文件分发:bitTorrent
- 文件被分为一个个块(chunk),一个256KB
- 每个peer维护一个bitmap,每个比特代表是否拥有某个块
- 定期peers交换bitmap知道对方用有啥块
- 网络中peers发送接收文件块,相互服务。请求稀缺块优先,防止那些拥有的peers全部下线(扰动churn);提供服务的时候优先想那些给自己提供好的服务(比如带宽大)的节点服务
- 有限的疏通:一次服务有限的节点,疏通它们,然后其他节点排队(不是FCFS,前三分之二个选择周期选择给自己提供好的服务的节点,后面三分之一个周期是随机选择),防止性能差
perrs都 tit-for-tat(以牙还牙)
- 节点加入洪流工作过程:带外解决(out of bound)
有文件分发检索的网站,输入关键字,匹配文件(这里匹配的是文件哈希值,文件尚在下载是包括文件本身、唯一的哈希值和文件的描述)这些检索的网站上有一个torrent文件,这个文件包含跟踪文件的checking server(维护的是哪些节点在上载下载该文件)根据某些测略给发送请求的节点一个torrent文件里面的一些目标节点列表,然后发出请求的节点与列表中的节点互通有无形成洪流
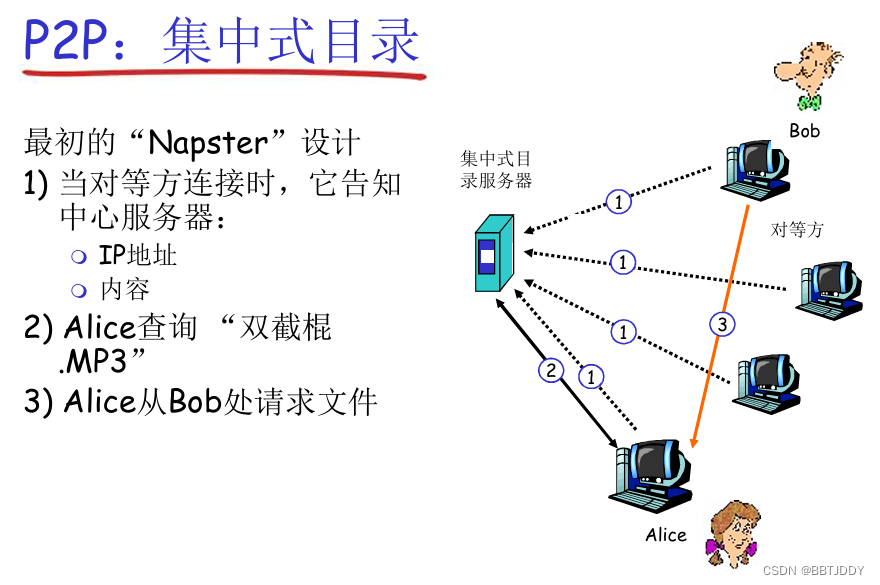
集中式目录(集中)
- 维护一个目录知道每个节点已有的资源:文件传输是分散,定位内容高度集中
- 问题:
- 单点故障
- 性能瓶颈:peer上线下线都要上报,会有性能问题
- 侵犯版权:很难处理侵权行为,一般一侵权就很多人
- 例子:Napster
- 问题:
完全分布式目录 (分散)
- 没有中心服务器
- 每个节点都构成overlay
- 例子:Gnutella(泛洪现象flooding)
- 问题
- 没完没了的转发查询(但是可以通过设置TTL等解决这个问题,使得泛洪有限)

加入节点的过程 退出节点的过程:分别告诉邻居自己要退出了。邻居知道他要离开了以后找一个新的节点以维持平衡。
退出节点的过程:分别告诉邻居自己要退出了。邻居知道他要离开了以后找一个新的节点以维持平衡。
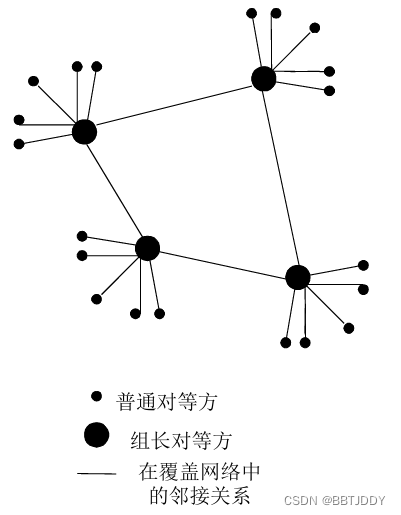
混合体 (半分散)
- 每个对等方要么是一个组长,要么隶属于一个组长
- 组长和组员的关系相当于Napster
- 组长和组长的关系相当于Gnutella
- 例子:KaZaA
DHT(结构化)P2P
- 按照id(哈希)大小形成固定结构,分发的每一个文件也通过哈希标识
这篇关于<计算机网络自顶向下> P2P应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




