本文主要是介绍GlusterFS 分布式文件系统 搭建及使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、GlusterFS
GlusterFS 是一个开源的分布式文件系统,旨在提供高性能、可扩展性和可靠性,适用于现代数据中心和云环境。它以横向扩展的方式设计,可以在多台服务器之间共享文件系统,为应用程序提供统一的文件存储服务。
GlusterFS 的核心理念是将多台普通的服务器组合成一个高性能的分布式存储系统。它采用了分布式哈希表来管理数据存储和访问,通过将文件划分为小块并存储在不同服务器上,实现了数据的分布式存储和负载均衡。这种分布式存储模式不仅提高了存储容量和性能,还提高了系统的可靠性,因为数据的冗余备份可以在服务器故障时保证数据的可用性。
GlusterFS 提供了简单而灵活的管理接口,使得管理员可以轻松地管理存储集群并对其进行扩展。它支持多种存储协议,包括标准的网络文件系统(NFS)、Server Message Block(SMB)和本地 POSIX 文件系统,使得应用程序可以通过不同的协议访问存储集群。
由于其高性能、可扩展性和易用性,GlusterFS 在大规模的数据存储和处理场景中被广泛应用,包括云计算、大数据分析、内容交付网络(CDN)等领域。它是一个强大而灵活的分布式文件系统解决方案,可以帮助用户构建可靠的存储基础设施,满足不断增长的存储需求。
GlusterFS的总体架构如下:
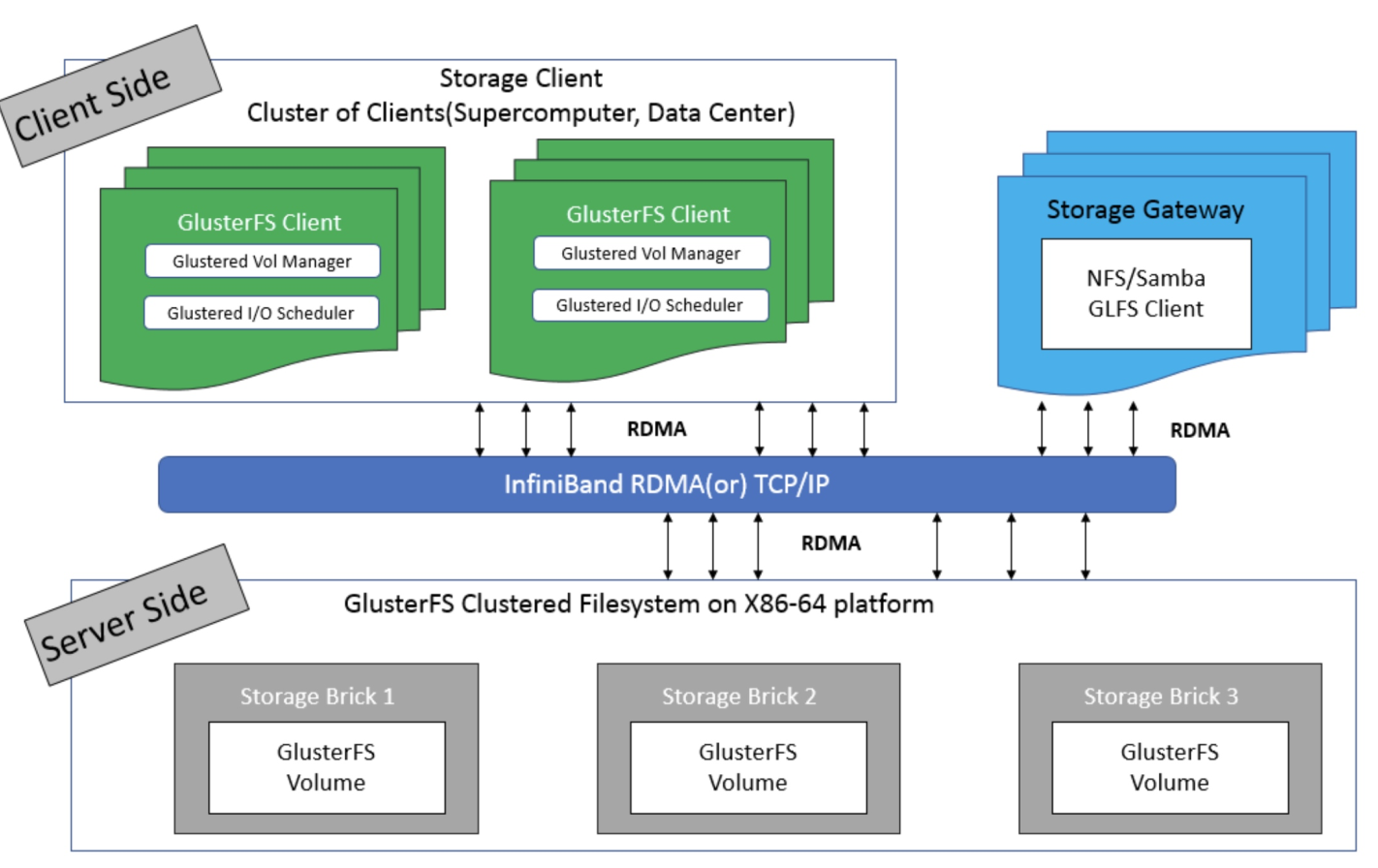
GlusterFS 比较核心的是存储卷,支持 7 种卷类型,即 分布式卷、条带卷、复制卷、分布式条带卷、分布式复制卷、条带复制卷、分布式条带复制卷,每种卷的特点如下:
分布式卷(Distributed Volume):分布式卷根据hash算法将数据均匀地分布在不同服务器上,每个文件被分割成固定大小的块,然后分别存储在不同的服务器上。这种分布式存储方式可以提高存储容量和性能,因为数据可以并行地从多个服务器上读取和写入。适用于需要大容量和高性能存储的场景,如大规模数据存储、内容交付网络(CDN)等。缺点是文件没有冗余副本,一旦某台服务宕机,其中存储的数据无法读取。
复制卷(Replicated Volume):复制卷在多个服务器之间复制数据,以提高数据的可靠性和容错能力。每个文件会被复制到多个服务器上,当某个服务器发生故障时,数据仍然可用。但是需要注意的是,由于数据被复制,这会增加存储开销。适用于对数据可靠性要求较高的场景,如数据备份、关键业务应用等。
条带化卷(Striped Volume):条带化卷将文件分割成固定大小的块,并将这些块分别存储在不同的服务器上。这样可以提高读写性能,因为数据可以并行地从多个服务器上读取和写入。适用于需要高吞吐量和低延迟的场景,如大规模数据处理、科学计算等。
分布式复制卷(Distributed Replicated Volume):分布式复制卷结合了分布式卷和复制卷的特点,既实现了数据的横向扩展和负载均衡,又提高了数据的可靠性和容错能力。每个文件会被分割成固定大小的块,并复制到多个服务器上。适用于需要兼顾数据容量、性能和可靠性的场景,如大规模数据存储和分析、虚拟化环境等。
分布式条带化卷(Distributed Striped Volume):分布式条带化卷结合了分布式卷和条带化卷的特点,既实现了数据的横向扩展和负载均衡,又提高了读写性能。每个文件会被分割成固定大小的块,并分别存储在多个服务器上。适用于需要高性能和横向扩展的场景,如大规模并行计算、大数据处理等。
分布式复制条带化卷(Distributed Replicated Striped Volume):结合了分布式卷、复制卷和条带化卷的特点,既实现了数据的横向扩展、可靠性和读写性能。每个文件会被分割成固定大小的块,并复制到多个服务器上,然后分别存储在不同的服务器上。适用于需要高性能、高可靠性和横向扩展的场景,如大规模数据处理和存储、分布式文件系统等。
分布式条带化复制卷(Distributed Striped Replicated Volume):结合了分布式卷、条带化卷和复制卷的特点,既实现了数据的横向扩展、读写性能和可靠性。每个文件会被分割成固定大小的块,并分别存储在多个服务器上,然后在每个服务器上进行数据复制。适用于需要高性能、高可靠性和横向扩展的场景,如大规模并行计算、分布式存储系统等。
二、GlusterFS 搭建
部署规划:
| ip | 别名 | 用途 |
|---|---|---|
| 11.0.1.129 | node1 | glusterfs-server |
| 11.0.1.130 | node2 | glusterfs-server |
| 11.0.1.131 | node3 | glusterfs-server |
| 11.0.1.132 | client | glusterfs-client |
在四台机器上配置 hosts 增加映射:
vi /etc/hosts
11.0.1.129 node1
11.0.1.130 node2
11.0.1.131 node3

1. glusterfs-server 端部署
在三台服务端机器上安装 glusterfs-server :
yum install centos-release-gluster
yum install -y glusterfs glusterfs-server glusterfs-fuseglusterfs-rdma --skip-broken
启动 glusterFS
systemctl start glusterd.service
设置开机自启:
systemctl enable glusterd.service
查看启动状态:
systemctl status glusterd.service
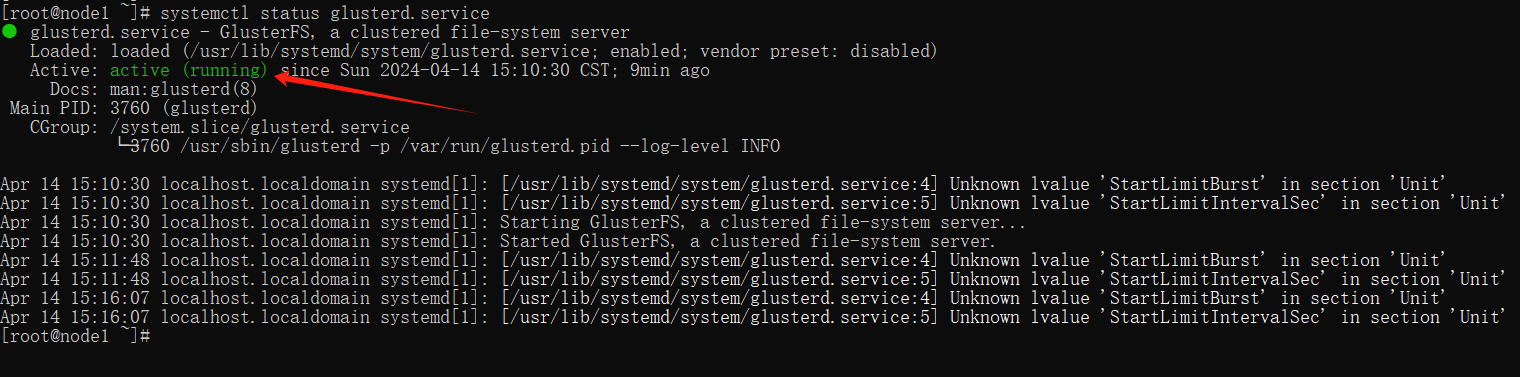
状态为 running 为正常。
可以在任意一台中,将另两个节点加入集群,下面示例在 node1 节点上操作:
gluster peer probe node2
gluster peer probe node3
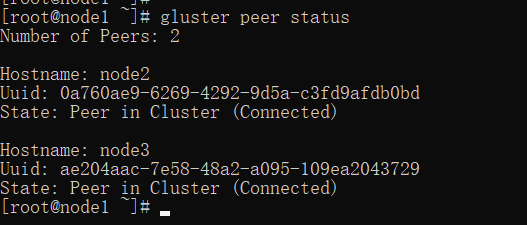
然后可以在任意一台中查看集群状态:
gluster peer status
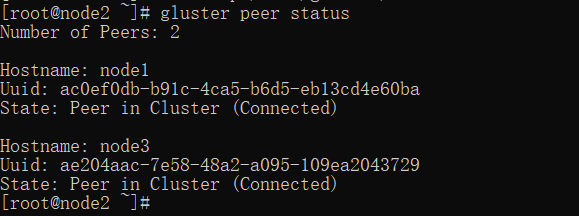
如果在node2查看就是 node1 和 node3 的信息:
查看 volume 状态:
gluster volume info
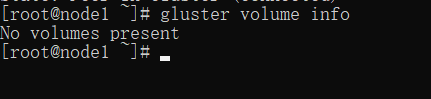
由于此时没有创建任何 volume ,所以查看为空。
创建分布式卷
在三台机器上分别创建文件存储目录:
mkdir -p /data/gluster/distributed
在其中一个节点下创建分布式卷。
gluster 默认情况下就是分布式卷,所以可以直接创建:
gluster volume create distributedVolume node1:/data/gluster/distributed node2:/data/gluster/distributed node3:/data/gluster/distributed force
其中:
distributedVolume是卷的名称。node1:/data/gluster、node2:/data/gluster 和 node3:/data/gluster分别指定了每个节点上存储卷数据的路径。force: 强制创建卷,即使存在相同名称的卷也会被覆盖。

启动该存储卷:
gluster volume start distributedVolume

查看 volume 状态:
gluster volume info
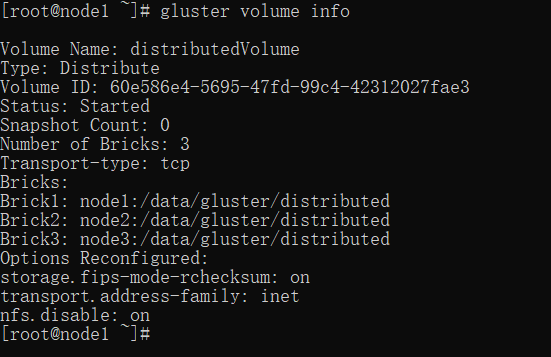
创建复制卷
在三台机器上分别创建文件存储目录:
mkdir -p /data/gluster/replicated
创建复制卷,副本数为 3 ,也就是会在每个节点上存一份:
gluster volume create replicatedVolume replica 3 node1:/data/gluster/replicated node2:/data/gluster/replicated node3:/data/gluster/replicated force
其中:
replicatedVolume是卷的名称。replica 3:指定副本的数量。node1:/data/gluster1、node2:/data/gluster1 和 node3:/data/gluster1分别指定了每个节点上存储卷数据的路径。force: 强制创建卷,即使存在相同名称的卷也会被覆盖。

启动该存储卷:
gluster volume start replicatedVolume

查看 volume 状态:
gluster volume info
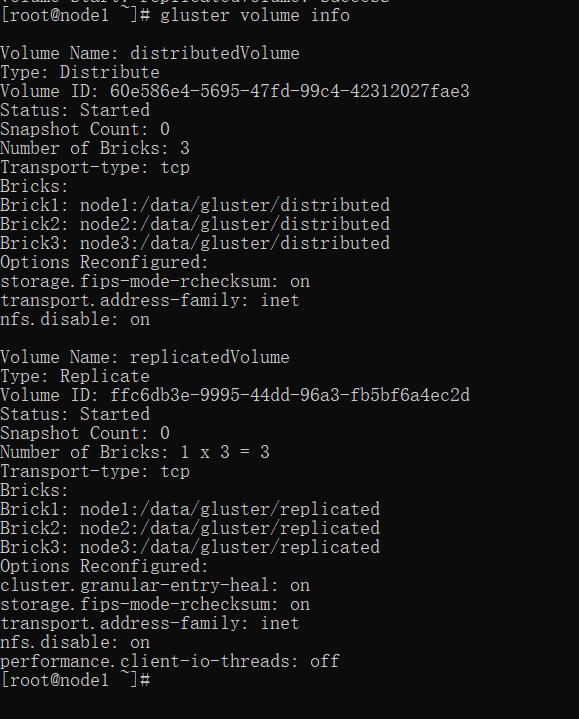
2. glusterfs-client 端部署
安装依赖:
yum install -y glusterfs glusterfs-fuse
创建挂载目录:
mkdir -p /gluster/distributed
mkdir -p /gluster/replicated
分布式卷挂载:
mount -t glusterfs node1:/distributedVolume /gluster/distributed

复制卷挂载:
mount -t glusterfs node1:/replicatedVolume /gluster/replicated

查看磁盘情况:
df -h
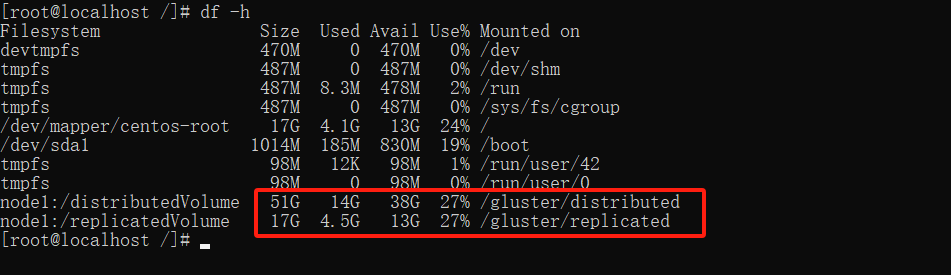
可以看到两个磁盘情况,由于我测试环境,给的磁盘较小,不过可以可出分布式卷式复制券的三倍大小。
三、文件测试
使用客户端机器上在分布式卷目录下创建文件:
cat > /gluster/distributed/test.txt << EOF
00011111222
EOF
分别查看 node1、node2、node3 的分布式卷下的情况:



可以看出文件 hash 存储到了 node2 节点上。
使用客户端机器上在复制卷目录下创建文件:
cat > /gluster/replicated/test.txt << EOF
00011111222
EOF
分别查看 node1、node2、node3 的分布式卷下的情况:



可以看出文件复制券会根据 replica 的大小,在相关的节点上都存储一份。
四、其它类型卷的使用及操作命令
分布式复制卷,机器数最少需要replica 的整数倍,如果指定 replica 2,则最少也需要 4 台机器:
gluster volume create volumeName replica 2 transport tcp node1:/data node2:/data node3:/data node4:/data
条带卷,将文件切割成数据块,分别存储到 stripe x 个节点中。
gluster volume create volumeName stripe 2 transport tcp node1:/data node2:/data
分布式条带卷,机器数最少需要stripe 的整数倍,如果指定 stripe 2 ,则最少需要 4 台机器:
gluster volume create volumeName stripe 2 transport tcp node1:/data node2:/data node3:/data node4:/data
条带复制卷,机器数最少需要stripe+ replica台 ,指定 stripe 2 ,replica 2,则需要 4 台机器:
gluster volume create volumeName stripe 2 replica 2 transport tcp node1:/data node2:/data node3:/data node4:/data
分布式条带复制卷,机器数需要是stripe+ replica 的整数倍,如果指定 stripe 2 ,replica 2,的话,就最少需要 8 台机器:
gluster volume create volumeName stripe 2 replica 2 transport tcp node1:/data node2:/data node3:/data node4:/data node5:/data node6:/data node7:/data node8:/data
查看所有卷:
gluster volume list
停止某个卷:
gluster volume stop volumeName
删除某个卷:
gluster volume delete volumeName
需要同时删除该卷下的 .glusterfs/ .trashcan/ 目录。
移除某个主机节点:
gluster peer detach node3
设置某个卷的 ip 访问限制:
gluster volume set volumeName auth.allow 10.6.0.*,10.7.0.*
为某个已经存在的卷添加节点,如果是复制卷或者条带卷,每次添加的 Brick 数必须是 replica 或者 stripe 的整数倍:
gluster volume add-brick volumeName node4:/data
为某个已经存在的卷移除节点,注意移除后剩余的机器需要能保证大于等于最小机器数:
gluster volume remove-brick volumeName node4:/data
五、参数调优
5.1 定磁盘使用配额
开启配额:
gluster volume quota volumeName enable
限制最大使用 100G:
gluster volume quota volumeName limit-usage / 100GB
5.2 开启异步操作
gluster volume set volumeName performance.flush-behind on
5.3 调整 io 线程的数量
gluster volume set volumeName performance.io-thread-count 32
5.4 使用缓存
# 设置缓存大小
gluster volume set models performance.cache-size 4GB
# 开启回写,先写到缓存,再刷到磁盘
gluster volume set models performance.write-behind on
这篇关于GlusterFS 分布式文件系统 搭建及使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





