本文主要是介绍MySQL Innodb中 可重复读隔离级别是否能完全规避幻读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、MySQL 可重复读隔离级别下的幻读
在 MySQL Innodb引擎可重复读隔离级别下,已经尽可能最大程度的规避幻读的问题了,使得大多数情况下,重复读都是可以得到一致的结果。
针对于读数据,可以大致分为两种模式,快照读(select ... )保证每次数据读取相同,即使其他事务写入或更新了数据。另一种是当前读(select ... for update) 的方式,每次读取最新的数据。不过两种方式解决幻读的策略不同。
-
快照读模式下,通过
MySQL MVCC多版本机制解决,在执行第一个select语句后,会创建一个Read View,后续的查询语句会先查询这个Read View,通过Read View就可以在undo log版本链中找到事务开始的数据,所以整个过程中可以保证查询的数据都是一致的,即使中间被其他事务插入了新数据。 -
当前读模式下,通过
MySQL Innodb中的间隙锁和临键锁解决幻读,当执行select ... for update时,会针对相关的记录或间隙进行加锁,如果有其他事务在修改相关数据,或在间隙中新增数据,都会被阻塞,直到当前事务处理完成后才能继续操作,进而规避了幻读的发生。
不过上面两种方式虽然解决了大多数情况下的幻读问题,但是某些个别情况下还是不可避免会发生幻读。
例如有如下表结构:
CREATE TABLE `user` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '姓名',`age` int DEFAULT NULL COMMENT '年龄',`grade` int DEFAULT NULL COMMENT '等级',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
写入两条测试数据:
INSERT INTO `testdb`.`user` (`id`, `name`, `age`, `grade`) VALUES (1, '张三', 18, 1);
INSERT INTO `testdb`.`user` (`id`, `name`, `age`, `grade`) VALUES (2, '李四', 18, 1);
二、可重复读隔离级别下幻读问题复现
首先在事务1中,查询 user 表下的所有数据:
BEGIN;
select * from `user`;
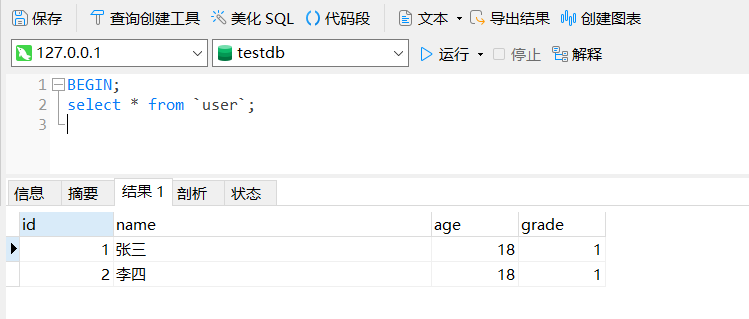
可以正常查到两条测试数据。
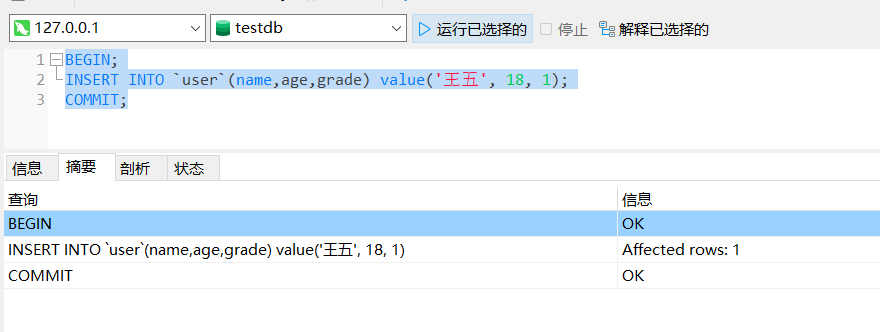
下面在事务2中插入一条新数据:
BEGIN;
INSERT INTO `user`(name,age,grade) value('王五', 18, 1);
COMMIT;
然后回到事务 1 ,当前如果继续执行查询,应该会命中先前查询的Read View:
select * from `user`;
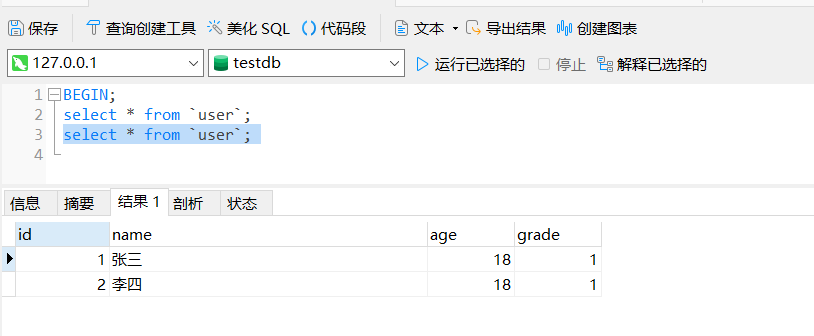
看到确实没有查出事务2新增的数据,但是下面在事务1中做一个更新操作,把所有 age > 15 的用户的 grade 修改成 2 ,然后再次执行上面相同的查询语句:
update `user` set grade = 2 where age > 15;
select * from `user`;
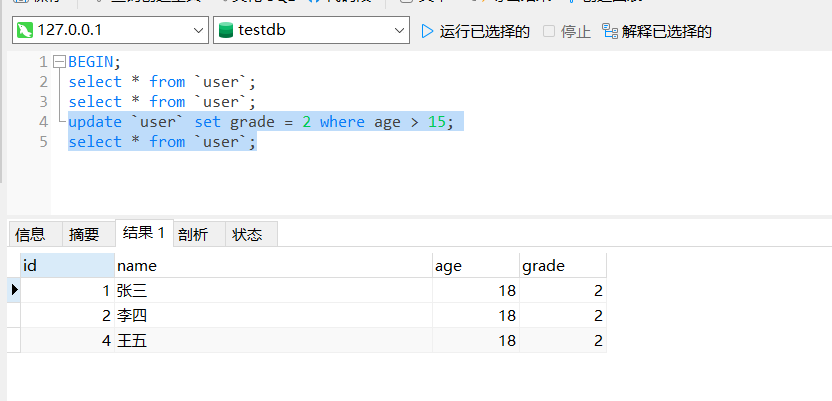
可以看到此时竟然查出了事务2新增的数据,对于事务1来说出现了幻读!
此时发生幻读主要在 update 执行后,首先之前的 select 属于快照读,不会对相关数据加锁,而 update 其实属于当前读,且 update 的范围,已经包含了事务2写入并提交的数据,所以导致后面的查询看到了新插入的数据。
同样的原理,将 update 语句换成 select .... for update 同样也会出现幻读。
三、如何解决幻读
从上面的例子可以看出,可重复读隔离级别并没有彻底解决幻读问题,只是尽可能最大程度的规避幻读的问题。其实有的时候我们可以从上层去协调这种问题,比如在代码层协调执行的过程。如果非要到SQL中解决,可以在最开始的 select 就加上 for update 或者 select ... in share mode,这样相关数据都被锁上了,其他事务的写操作就会被阻塞,缺点是处理的效率就会大大折扣,具体解决方法还是要结合业务决策。
这篇关于MySQL Innodb中 可重复读隔离级别是否能完全规避幻读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







