本文主要是介绍【MIT6.S081】Lab3: page tables(详细解答版),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实验内容网址:https://xv6.dgs.zone/labs/requirements/lab3.html
本实验的代码分支:https://gitee.com/dragonlalala/xv6-labs-2020/tree/pgtbl2/
Print a page table
关键点:递归、三级页表
思路:
![[图片]](https://img-blog.csdnimg.cn/direct/18f5673be3564a64bc8d819d57fc5f3a.png)
用上图来解释三级页表的原理最为清晰明了。satp的作用是存放根页表页在物理内存中的地址。页表以三级的树型结构存储在物理内存中。该树的根是一个4096字节(512*8byte)的页表页,其中包含512个PTE,每个PTE中包含该树下一级页表页的物理地址。这些页中的每一个PTE都包含该树最后一级的512个PTE(也就是说每个PTE占8个字节,正如图3.2最下面所描绘的)。分页硬件使用27位中的前9位在根页表页面中选择PTE,中间9位在树的下一级页表页面中选择PTE,最后9位选择最终的PTE。一级页表通过stap和L2确定二级页表的基地址,二级页表的基地址加上L1确定三级页表的基地址,三级页表的基地址和L0确定物理地址的前44位,与原来offset的12位组成了物理地址。总体上说,这个过程类似3级512叉树。这样做的目的是为了节省内存,在大范围的虚拟地址没有被映射的常见情况下,三级结构可以忽略整个页面目录。
在每一级页表中,后十位是标志位,在一二级页表中,这些标志位中的RWX是不使用的,一二级页表是起到索引功能,所以只使用了V标志位。
步骤&代码:
kernel/vm.c中定义vmprint()函数,题目要求参数为pagetable_t,但在本题中,需要进行递归,并且递归过程中需要知道当前是递归的第几层,所以需要另外定义一个递归函数,_vmprint(pagetable, level);传递页表指针和递归层数。需要注意的是vmprint()函数需要到def.h文件中声明,_vmprint()函数需要在vmprint()函数前进行定义。
void
vmprint(pagetable_t pagetable){// 打印根页表printf("page table %p\n", pagetable);// 重新写个函数是为了传递level级和递归_vmprint(pagetable, 1);
}
- 编写
_vmprint()函数,仿照freewalk函数的遍历方式。通过pte & PTE_V可以判断pte的有效性,在有效的前提下通过(pte & (PTE_R|PTE_W|PTE_X)) == 0)可以判断是哪一级页表,在第三级页表中,第三级页表存放的是物理地址,页表中页表项中W位,R位,X位起码有一位会被设置为1。根据以上思路编写如下代码:
void _vmprint(pagetable_t pagetable, int level){for(int i = 0; i < 512; i++){pte_t pte = pagetable[i];// 检查pte的有效性if(pte & PTE_V ){// this PTE points to a lower-level page table.uint64 child = PTE2PA(pte);// 打印树的深度for(int j = 0; j < level; j++){if(j==0){printf("..");//第一个..前面不打印空格}else{printf(" ..");}}printf("%d: pte %p pa %p\n",i,pte,child);// 第三级页表存放的是物理地址,页表中页表项中W位,R位,X位起码有一位会被设置为1。如果是索引页表则这些值是0if((pte & (PTE_R|PTE_W|PTE_X)) == 0){_vmprint((pagetable_t)child,level+1);// 还没到第三级,继续递归。}}}
}
A kernel page table per process
前置知识:
原本的xv6系统只有一个内核页表。内核页表直接映射(恒等映射)到物理地址,也就是说内核虚拟地址x映射到物理地址仍然是x。每个进程有单独的用户页表,但只包含该进程用户内存的映射,从虚拟地址0开始。内核页表中不含有这些映射,因此用户地址(虚拟地址)在内核中无效,只能通过copyin(),copyoput()等函数将用户地址转化为物理地址再使用。
关于内核栈:
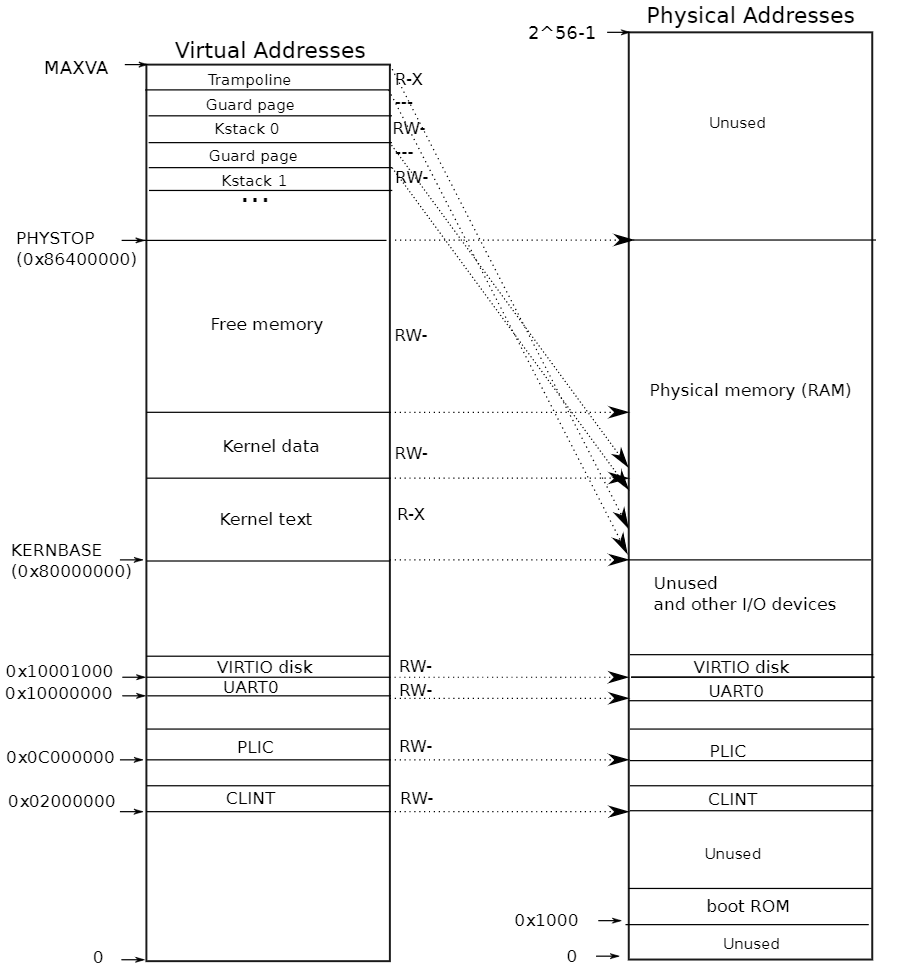
内核栈页面。每个进程都有自己的内核栈,它将映射到偏高一些的地址,这样xv6在它之下就可以留下一个未映射的保护页(guard page)。保护页的PTE是无效的(也就是说PTE_V没有设置),所以如果内核溢出内核栈就会引发一个异常,内核触发panic。如果没有保护页,栈溢出将会覆盖其他内核内存,引发错误操作。恐慌崩溃(panic crash)是更可取的方案。(注:Guard page不会浪费物理内存,它只是占据了虚拟地址空间的一段靠后的地址,但并不映射到物理地址空间。)
如图中的kstack0,1是每个进程的内核栈。/kernel/proc.c文件中的procinit函数中初始化了每个进程的内核栈。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先进程用户空间中的栈,而是一个单独内核空间的栈,这个称作进程内核栈 ,除了系统调用,像进程切换时的上下文也是保存到内核栈中的。
// initialize the proc table at boot time.
void
procinit(void)
{struct proc *p;initlock(&pid_lock, "nextpid");for(p = proc; p < &proc[NPROC]; p++) {initlock(&p->lock, "proc");// Allocate a page for the process's kernel stack.// Map it high in memory, followed by an invalid// guard page.char *pa = kalloc();if(pa == 0)panic("kalloc");uint64 va = KSTACK((int) (p - proc));kvmmap(va, (uint64)pa, PGSIZE, PTE_R | PTE_W);p->kstack = va;}kvminithart();
}
OK,巴拉巴拉了一大堆,具体的解题过程还需要依靠题目的提示,接下来进入正题。
步骤&代码:
- 在
struct proc中为进程的内核页表增加一个字段
struct proc{
...pagetable_t pagetable; // User page table// 新添加pagetable_t kpt; // kernel page table
...
}
- 为一个新进程生成一个内核页表的合理方案是实现一个修改版的
kvminit,这个版本中应当创造一个新的页表而不是修改kernel_pagetable。你将会考虑在allocproc中调用这个函数。
我们仿照kvminit重写一个pagetable_t proc_kpt_init()函数,在kvminit函数中,外设的映射是使用kvmmap函数,该函数里面使用了kernel_pagetable,因此我们还需要重写一个void proc_kvmmmap(pagetable_t kpt, uint64 va, uint64 pa, uint64 sz, int perm)函数,将kpt页表指针作为函数参数进行传递。
// 为进程的内核页表新建一个初始化函数
pagetable_t proc_kpt_init(){pagetable_t kpt = (pagetable_t) kalloc();memset(kpt, 0, PGSIZE);// uart registersproc_kvmmmap(kpt, UART0, UART0, PGSIZE, PTE_R | PTE_W);// virtio mmio disk interfaceproc_kvmmmap(kpt, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);// CLINTproc_kvmmmap(kpt, CLINT, CLINT, 0x10000, PTE_R | PTE_W);// PLICproc_kvmmmap(kpt, PLIC, PLIC, 0x400000, PTE_R | PTE_W);// map kernel text executable and read-only.proc_kvmmmap(kpt, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);// map kernel data and the physical RAM we'll make use of.proc_kvmmmap(kpt, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);// map the trampoline for trap entry/exit to// the highest virtual address in the kernel.proc_kvmmmap(kpt, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);return kpt;
}// kvmmap是为内核页表的虚拟地址与物理地址做映射,这里需要重新添加一个类似的函数
void proc_kvmmmap(pagetable_t kpt, uint64 va, uint64 pa, uint64 sz, int perm){if(mappages(kpt, va, sz, pa, perm) != 0)panic("proc_kvmmap");
}
函数定义完后记得把函数声明添加到defs.h文件中。
在allocproc中调用proc_kpt_init()函数
static struct proc*
allocproc(void)
{
...
...
// An empty user page table.p->pagetable = proc_pagetable(p);if(p->pagetable == 0){freeproc(p);release(&p->lock);return 0;}// ljg add // An empty kernel page table.p->kpt = proc_kpt_init();
...}
- 确保每一个进程的内核页表都关于该进程的内核栈有一个映射。在未修改的XV6中,所有的内核栈都在procinit中设置。你将要把这个功能部分或全部的迁移到
allocproc中
参照/kernel/proc.c文件中的procinit函数中初始化了每个进程的内核栈,并在allocproc函数中的p->kpt = proc_kpt_init();语句后添加
// 申请内核栈,确保每一个进程的内核页表都关于该进程的内核栈有一个映射char *pa = kalloc();if(pa == 0)panic("kalloc");uint64 va = KSTACK((int) (p - proc));proc_kvmmmap(p->kpt, va, (uint64)pa, PGSIZE, PTE_R | PTE_W);p->kstack = va;
- 修改
scheduler()来加载进程的内核页表到核心的satp寄存器(参阅kvminithart来获取启发)。不要忘记在调用完w_satp()后调用sfence_vma(), - 没有进程运行时
scheduler()应当使用kernel_pagetable
参照kvminithart函数,在其附近新添加proc_kvminithart函数,以实现传递页表指针。
void
proc_kvminithart(pagetable_t kpt){w_satp(MAKE_SATP(kpt));sfence_vma();
}
然后在scheduler()函数中,进程切换前调用proc_kvminithart()函数。根据“没有进程运行时scheduler()应当使用kernel_pagetable”要求,在进程切换出去–>回来后调用kvminithart()函数。(不懂为什么要在这个时候?)
void
scheduler(void)
{
...p->state = RUNNING;c->proc = p;// 加载进程的内核页表到核心的satp寄存器proc_kvminithart(p->kpt);swtch(&c->context, &p->context);// ljg add Come back to the global kernel page tablekvminithart();// Process is done running for now.// It should have changed its p->state before coming back.c->proc = 0;...}
- 在
freeproc中释放一个进程的内核页表
参照freewalk函数在vm.c文件中添加free_proc_kpt()函数。
// 释放进程的内核页表
void
free_proc_kpt(pagetable_t pagetable)
{// there are 2^9 = 512 PTEs in a page table.for(int i = 0; i < 512; i++){pte_t pte = pagetable[i];if(pte & PTE_V){// this PTE points to a lower-level page table.uint64 child = PTE2PA(pte);pagetable[i] = 0;if((pte & (PTE_R|PTE_W|PTE_X)) == 0){// 说明不是第三级,进行递归free_proc_kpt((pagetable_t)child);}} }kfree((void*)pagetable);
}
在freeproc()函数中,释放内核栈和内核页表
static void
freeproc(struct proc *p)
{
...if(p->pagetable)proc_freepagetable(p->pagetable, p->sz);p->pagetable = 0;// 释放一个进程的内核栈if(p->kstack){uvmunmap(p->kpt, p->kstack, 1, 1);}p->kstack = 0;// 释放内核页表free_proc_kpt(p->kpt);p->kpt = 0;
...
}
- 在
defs.h文件中添加以上函数的声明
void vmprint(pagetable_t);
pagetable_t proc_kpt_init();
void proc_kvmmmap(pagetable_t, uint64 , uint64 , uint64 , int );
void proc_kvminithart(pagetable_t );
void free_proc_kpt(pagetable_t pagetable);
进行编译,会发现无法启动系统,报"virtio_disk_intr status"的错误。
原因在于 virtio_disk_rw()函数中为buf申请内核地址时使用了kernel_pagetable,因此要在kvmpa函数中
修改一处地方
uint64
kvmpa(uint64 va)
{uint64 off = va % PGSIZE;pte_t *pte;uint64 pa;pte = walk(myproc()->kpt, va, 0);// 新修改if(pte == 0)panic("kvmpa");if((*pte & PTE_V) == 0)panic("kvmpa");pa = PTE2PA(*pte);return pa+off;
}
进行编译,会出现以下错误。
In file included from kernel/vm.c:9:
kernel/proc.h:87:19: error: field ‘lock’ has incomplete type
87 | struct spinlock lock;
| ^~~~
make: *** [: kernel/vm.o] Error 1
在vm.c中包含头文件即可解决。
#include "spinlock.h"
#include "proc.h"
编译成功后运行usertests,运行通过则本题完成
Simplify
关键点:题目含义
思路:
即使是第二遍做这个题目一开始也不知道怎么入手。哈哈哈
题目需要我将用户空间的映射添加到每个进程的内核页表,将进程的页表复制一份到进程的内核页表就好。
Xv6使用从零开始的虚拟地址作为用户地址空间,而内核的内存从更高的地址开始。然而,这个方案将用户进程的最大大小限制为小于内核的最低虚拟地址,为0xC000000,即PLIC寄存器的地址;
步骤&代码:
- 在
vm.c文件中,仿照uvmcopy()函数新建一个复制用户页表映射到每个进程的内核页表映射的函数。uvmcopy()函数是复制父进程的映射到子进程的映射。代码如下:
// 仿照uvmcopy()函数,实现将用户空间的映射添加到每个进程的内核页表
void
u2k_vmcopy(pagetable_t pagetable, pagetable_t kpt, uint64 oldsz, uint64 newsz){pte_t *pte_from;pte_t *pte_to;oldsz = PGROUNDUP(oldsz);for(uint64 i = oldsz; i < newsz; i += PGSIZE){// 对页表pagetable中虚拟地址为i进行检查,检查pte是否存在if((pte_from = walk(pagetable, i, 0)) == 0)panic("u2k_vmcopy: pte should exist");// 对内核页表kpt中虚拟地址为i进行检查,检查pte是否存在,若不存在则申请物理内存并映射。if((pte_to = walk(kpt, i, 1)) == 0){panic("u2k_vmcopy: pte walk fail");}// 在内核模式下,无法访问设置了PTE_U的页面,// 所以接下来要获得pagetable中虚拟地址为i的pte的标志位// uint64 pa = PTE2PA(*pte_from);// uint flags = (PTE_FLAGS(*pte_from)) & (~PTE_U);// *pte_to = PA2PTE(pa) | flags;// 感觉上面三句有点多,改成一句*pte_to = (*pte_from) & (~PTE_U);}
}
- 根据提示在
exec,fork,sbrk函数中添加u2k_vmcopy()函数的调用。
exec()
int
exec(char *path, char **argv)
{
...uvmclear(pagetable, sz-2*PGSIZE);sp = sz;stackbase = sp - PGSIZE;// 添加复制逻辑u2k_vmcopy(pagetable, p->kpt, 0, sz);// Push argument strings, prepare rest of stack in ustack.for(argc = 0; argv[argc]; argc++) {...
}
fork()
int
fork(void)
{
...np->sz = p->sz;// 复制到新进程的内核页表u2k_vmcopy(np->pagetable, np->kpt, 0, np->sz);np->parent = p;
...
}
sbrk() -> sys_sbrk() -> growproc()函数中,在内存增加时,需要判断一下会不会超过PLIC限制,不超过再复制一份映射到内核页表
int
growproc(int n)
{uint sz;struct proc *p = myproc();sz = p->sz;if(n > 0){// 加上PLIC限制if(PGROUNDUP(sz+n) >= PLIC){return -1;}if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {return -1;}// 复制一份到内核页表u2k_vmcopy(p->pagetable, p->kpt, sz - n, sz);} else if(n < 0){sz = uvmdealloc(p->pagetable, sz, sz + n);}p->sz = sz;return 0;}
userinit的内核页表中包含第一个进程的用户页表,在这里也需要复制一份
void
userinit(void)
{
...uvminit(p->pagetable, initcode, sizeof(initcode));p->sz = PGSIZE;// 复制一份到内核页表u2k_vmcopy(p->pagetable, p->kpt, 0, p->sz);// prepare for the very first "return" from kernel to user.
...}
记得在defs.h中添加u2k_vmcopy()函数的声明。完毕!
未解:
上述的这几个函数调用的位置可以思考一下,为什么需要在exec,fork,sbrk函数中调用?
这篇关于【MIT6.S081】Lab3: page tables(详细解答版)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





