本文主要是介绍数据结构进阶之堆,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天我们学习的是数据结构里面的堆,大家先看看我们今天要学习的内容
一、堆概念及认识
在学习堆之前我们得先明白完全二叉树是什么样子,因为堆是依据完全二叉树的结构来实现的,所以在这里我先告诉大家完全二叉树的是什么,如下图: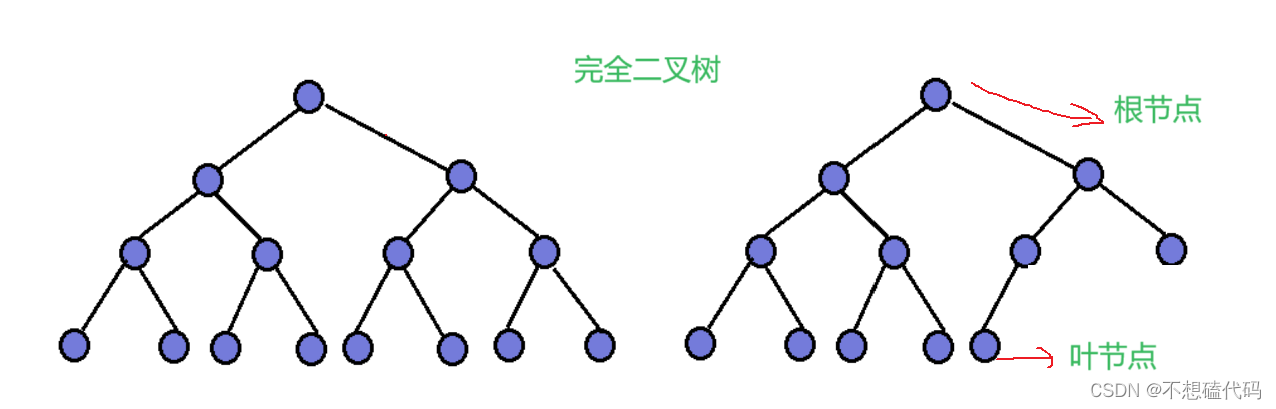
完全二叉树就是从根节点开始依次往下延伸展开,其他层都是满节点,只有最后一层不同,最后一层可满可不满,但是最后一层必须是从左往右,这就是完全二叉树,也就是堆的逻辑结构。
堆的概念及认识:堆是一种数据结构,分为大堆和小堆,数据从上开始往下排序,上一层的数据如果大于下一层的每个数据,那么它就是大堆,反之就是小堆。
二、堆的结构及操作原理
堆的逻辑结构就是完全二叉树的结构,但是我们要实现自己的堆就需要了解堆的物理结构,它是如何实现对数据的储存的,在这里实现堆我们用数组来实现堆,大家可能会一脸懵,所以接下来我向大家解释为什么用数组来实现。
先看下图来理解:
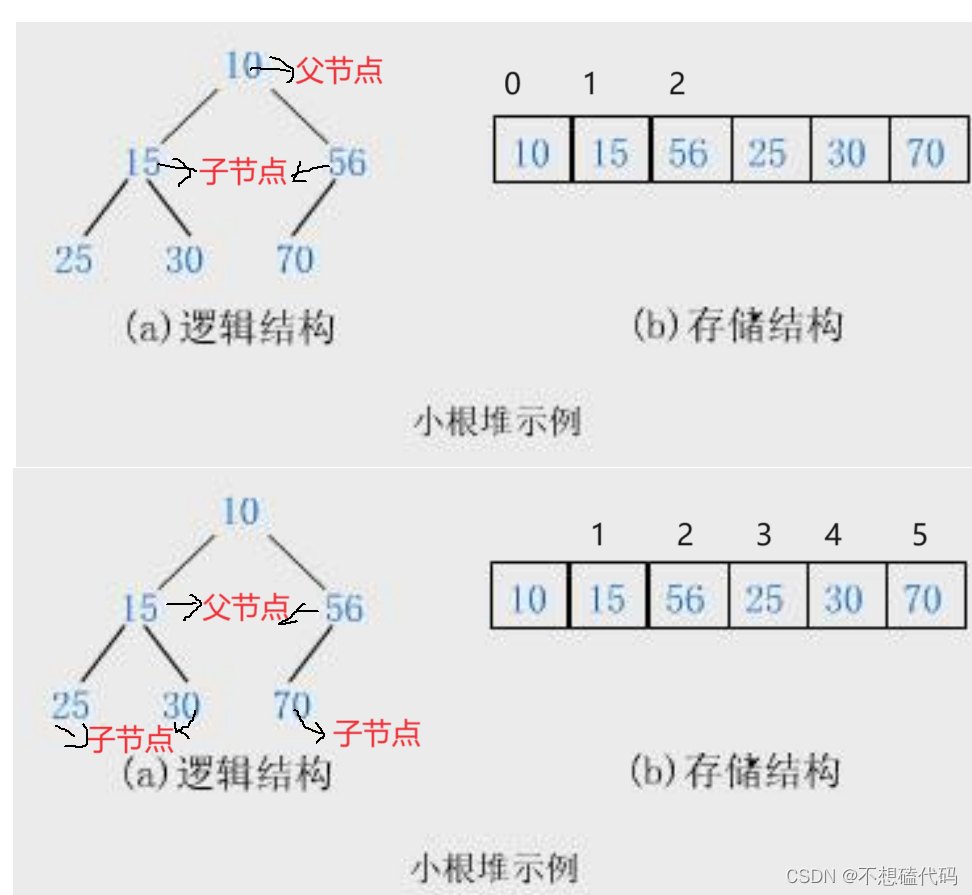
如果把上层看作父节点,下层看作子节点,再看看它们的的数组下标大家会不会发现父子节点之间存在某种关系,这也是其他大佬发现的规律,在这里我直接告诉大家,用 parent 作为父节点的下标,child 作为子节点的下标,就会有下面的下标规律:
child = 2 * parent + 1 ,parent = (child - 1)/ 2 。
因为有上面的规律,所以我们实现自己的堆才选择用数组来储存,上面的规律也是堆实现的底层逻辑。
三、堆的实现
在这里我们以实现小堆为例,首先我得先告诉大家小堆的储存结构,大家先看下图: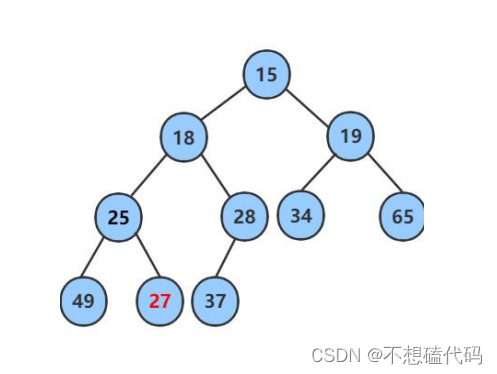
如果是小堆,那么上一层的数据必须小于下一层的数据,并且最高层的数据是最小的,这就是小堆。那么接下来我们就来实现一个自己的堆。
首先需要创建一个结构体用来储存堆的数组和堆的大小和堆的数据个数,如下:
typedef int HPDataType;
typedef struct Heap
{HPDataType* a;// 堆的物理结构时数组,逻辑结构是满二叉树或完全二叉树int size;int capacity;
}HP;接下来我们先写出最简单的堆的初始化和销毁和一个交换函数,如下:
//堆的初始化
void HPInit(HP* hp)
{assert(hp);hp->a = NULL;hp->capacity = hp->size = 0;
}//堆的销毁
void HPDestroy(HP* hp)
{assert(hp);free(hp->a);hp->capacity = hp->size = 0;
}//实现交换数据
void Swap(HPDataType* hp1, HPDataType* hp2)
{HPDataType tem = *hp1;*hp1 = *hp2;*hp2 = tem;
}最难的部分就是堆数据放入时的向上调整,因为是小堆,所以上一层的数据必须小于下一层的每个数据,所以每次放进一个数据就要向上进行调整,用来保证小堆的结构,那如何来实现数据的想上调整呢,请看下面:
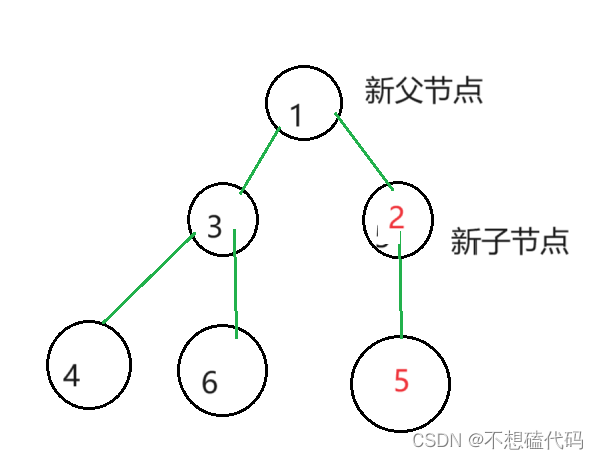
根据上面的讲解我们开始实现向上调整,请结合代码中的注释加以理解:
//堆数据的向上调整 时间复杂度:O(logN)
void AdjustUp(HP* hp, int child)
{assert(hp);assert(hp->size > 0);// 截至条件是 当最后一次的子节点小于或者等于0的时候 说明上层没有数据 也就不用再向上调整了while (child > 0){// 实现数据的交换// 根据父子的关系规律来找到父节点int parent = (child - 1) / 2;if (hp->a[parent] > hp->a[child]){//交换Swap(&(hp->a[parent]), &(hp->a[child]));child = parent;}else{// 如果已经符合小堆 就直接退出break;}}
}有了上面的向上调整,我们就可以开始实现数据的入队列了,操作如下:
//堆的放入数据
void HPPush(HP* hp, HPDataType x)
{assert(hp);if (hp->capacity == hp->size){// 堆内存的开辟int newcapacity = hp->capacity == 0 ? 4 : 2 * hp->capacity;HPDataType* tem = (HPDataType*)realloc(hp->a, sizeof(HPDataType) * newcapacity);if (tem == NULL){perror("realloc");exit(1);}hp->a = tem;hp->capacity = newcapacity;}// 堆数据的放入hp->a[hp->size] = x;hp->size++;// 每次放入一个数据都需要进行向上调整来保证小堆的完整性AdjustUp(hp, hp->size - 1);
}接下来我们继续实现堆的其他简单操作,如下:
//获取堆顶数据
HPDataType HPTop(HP* hp)
{assert(hp);return hp->a[0];
}//堆中的数据个数
int HPSize(HP* hp)
{assert(hp);return hp->size - 1;
}//堆的判空
bool HPEmpty(HP* hp)
{assert(hp);return hp->size == 0;
} 接下来还有一个难点就是堆顶数据的删除,首先我们得了解一下堆顶数据是如何进行删除的,我来告诉大家,堆顶数据的删除不是真的删除,而是把堆顶的数据和堆的最后一位数据进行交换,并且对堆顶的数据再进行向下调整,来保证小堆的结构。上面我有提到了向下调整,这其实和向上调整一样,请大家看原理图:
那为什么要和两个子节点中较小的进行比较呢,因为要符合小堆,必须最高层数据是最小值,所以要和两个子节点中较小的进行比较,实现如下请结合注释一起理解:
//堆数据的向下调整 时间复杂度:logN
void AdjustDown(HP* hp, int parent)
{assert(hp);// 用父子节点之间的规律来找到子节点int child = 2 * parent + 1;// 退出条件为 最后一次的子节点超出堆的大小就不用在进行向下调整 直接退出循环while (child < hp->size){// 要判断两个子节点中的最小值 首先这个父节点下面要有两个子节点才可以 如果没有就直接和子节点比较饥渴if (child + 1 < hp->size){if (hp->a[child] > hp->a[child + 1]){// 假设法选出两个儿子中的最小值child = child + 1;}}if (hp->a[parent] > hp->a[child]){// 交换两个值Swap(&(hp->a[child]), &(hp->a[parent]));parent = child;child = 2 * parent + 1;}else{// 如果没有交换 说明满足小堆的结构 直接退出即可break;}}}接下来堆顶数据的删除就可以结合堆顶数据的删除原则(如堆顶数据删除的原理图)就可以写出来了,如下:
//堆顶数据的删除
void HPPop(HP* hp)
{assert(hp);Swap(&(hp->a[0]), &(hp->a[hp->size - 1]));hp->size--;AdjustDown(hp, 0);
}这就是堆的实现,大家还有什么不会的或者没理解的,可以评论区留言或者私信我,我来帮大家解答。
好了,今天的内容就到这,下期再见!!!
这篇关于数据结构进阶之堆的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






