本文主要是介绍Boruta 和 SHAP :不同特征选择技术之间的比较以及如何选择,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:DeepHub IMBA本文约1800字,建议阅读5分钟 在这篇文章中,我们演示了正确执行特征选择的实用程序。
当我们执行一项监督任务时,我们面临的问题是在我们的机器学习管道中加入适当的特征选择。只需在网上搜索,我们就可以访问讨论特征选择过程的各种来源和内容。
总而言之,有不同的方法来进行特征选择。文献中最著名的是基于过滤器和基于包装器的技术。在基于过滤器的过程中,无监督算法或统计数据用于查询最重要的预测变量。在基于包装器的方法中,监督学习算法被迭代拟合以排除不太重要的特征。
通常,基于包装器的方法是最有效的,因为它们可以提取特征之间的相关性和依赖性。另一方面,它们更容易过拟合。为了避免这种问题并充分利用基于包装器的技术,我们需要做的就是采用一些简单而强大的技巧。我们可以通过一点数据理解和一个特殊的技巧来实现更好的特征选择。别担心,我们使用的不是黑暗魔法,而是SHAP(SHApley Additive exPlanations)的力量。
为了在特征选择过程中更好地利用 SHAP 的功能,我们发布了 shap-hypetune:一个用于同时调整超参数和特征选择的 Python 包。它允许在为梯度提升模型定制的单个管道中组合特征选择和参数调整。它支持网格搜索或随机搜索,并提供基于包装的特征选择算法,如递归特征消除 (RFE) 或 Boruta。进一步添加包括使用 SHAP 重要性进行特征选择,而不是经典的基于原生树的特征重要性。
在这篇文章中,我们演示了正确执行特征选择的实用程序。如果我们高估了梯度提升的解释能力,或者只是我们没有一般的数据理解,这表明并不像预期的那么简单。我们的范围是检测各种特征选择技术的表现如何以及为什么使用 SHAP 会有所帮助。
什么是Boruta?
每个人都知道(或很容易理解)RFE 递归特征消除是如何工作的。考虑到较小的特征集,它递归地拟合监督算法。其中排除的特征是根据某些权重的大小(例如,线性模型的系数或基于树的模型的特征重要性)被认为不太重要的特征。
Boruta 与 RFE 一样,是一种基于包装器的特征选择技术。可能很少有人听过它的名字,但是它同样强大。Boruta 背后的想法非常简单。给定一个表格数据集,我们在数据的扩展版本上迭代地拟合监督算法(通常是基于树的模型)。在每次迭代中,扩展版本由原始数据与水平连接的混洗列的副本组成。我们只维护在每次迭代中的特征:
比最好的随机排序特征具有更高的重要性;
比随机因素(使用二项式分布)好于预期。
RFE 和 Boruta 都使用提供特征重要性排名的监督学习算法。这个模型是这两种技术的核心,因为它判断每个特征的好坏。这里可能会出现问题。决策树的标准特征重要性方法倾向于高估高频或高基数变量的重要性。对于 Boruta 和 RFE,这可能会导致错误的特征选择。
本次实验
我们从 Kaggle 收集了一个数据集。我们选择了一个银行客户数据集,我们尝试预测客户是否很快就会流失。在开始之前,我们将一些由简单噪声构成的随机列添加到数据集中。我们这样做是为了了解我们的模型如何计算特征重要性。我们开始拟合和调整我们的梯度提升(LGBM)。我们用不同的分裂种子重复这个过程不同的时间来覆盖数据选择的随机性。下面提供了平均特征重要性。
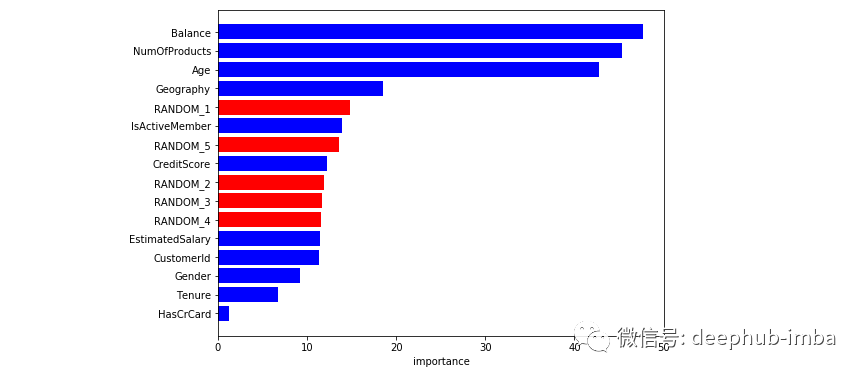
令人惊讶的是,随机特征对我们的模型非常重要。另一个错误的假设是将 CustomerId 视为有用的预测器。这是客户的唯一标识符,梯度提升错误地认为它很重要。
鉴于这些前提,让我们在我们的数据上尝试一些特征选择技术。我们从RFE开始。我们将参数的调整与特征选择过程相结合。和以前一样,我们对不同的分裂种子重复整个过程,以减轻数据选择的随机性。对于每个试验,我们考虑标准的基于树的特征重要性和 SHAP 重要性来存储选定的特征。通过这种方式,我们可以绘制在试验结束时选择某个特征的次数。
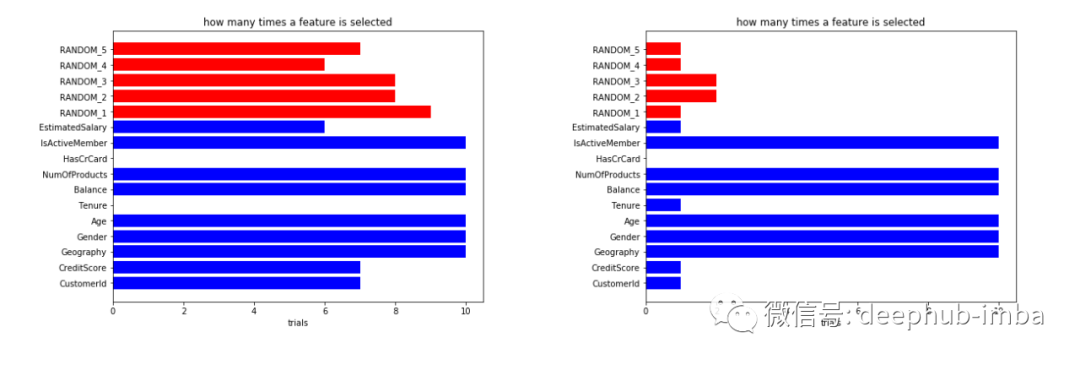
使用 RFE 选择某个特征的次数(左);使用 RFE + SHAP 选择某个特征的次数(右)
在我们的案例中,具有标准重要性的 RFE 显示是不准确的。它通常选择与 CustomerId 相关的随机预测变量。SHAP + RFE 最好不要选择无用的特征,但同时承认一些错误的选择。
作为最后一步,我们重复相同的过程,但使用 Boruta。
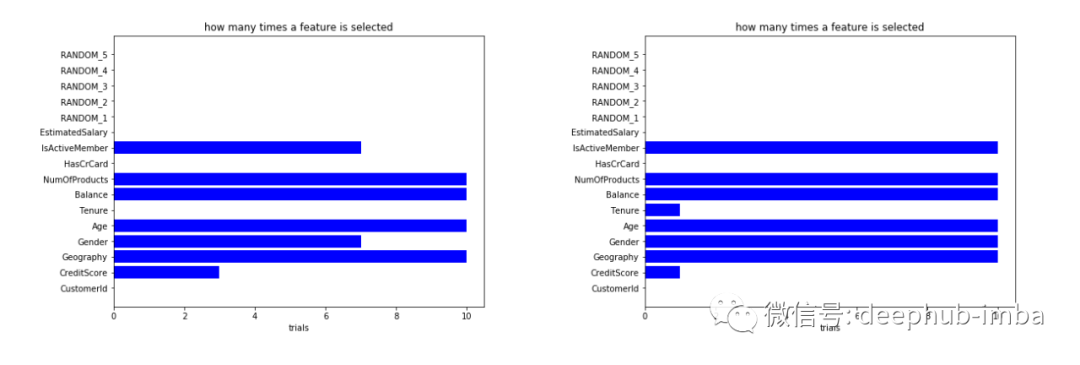
Boruta(左)选择一个特征的次数;使用 Boruta + SHAP 选择某个特征的次数(右)
单独的标准 Boruta 在不考虑随机变量和 CustomerId 方面做得很好。SHAP + BORUTA 似乎也能更好地减少选择过程中的差异。
总结
在这篇文章中,我们介绍了 RFE 和 Boruta(来自 shap-hypetune)作为两种有价值的特征选择包装方法。此外,我们使用 SHAP 替换了特征重要性计算。SHAP 有助于减轻选择高频或高基数变量的影响。综上所述,当我们对数据有完整的理解时,可以单独使用RFE。Boruta 和 SHAP 可以消除对正确验证的选择过程的任何疑虑。
最后源代码在这里:
https://github.com/cerlymarco/MEDIUM_NoteBook/tree/master/ShapBoruta_FeatureSelection
本文作者:Marco Cerliani
编辑:文婧

这篇关于Boruta 和 SHAP :不同特征选择技术之间的比较以及如何选择的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




