本文主要是介绍【JAVA基础篇教学】第十篇:Java中Map详解说明,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

博主打算从0-1讲解下java基础教学,今天教学第十篇:Java中Map详解说明。
在 Java 编程中,Map 接口代表了一种键值对的集合,每个键对应一个值。Map 接口提供了一系列操作方法,可以方便地对键值对进行增删改查等操作。本文将介绍 Map 接口的基本概念以及如何在 Java 中使用 Map 接口。
一、Map 接口概述
Map 接口是 Java Collections Framework 中的一部分,位于 java.util 包中。它是一个接口,代表了一种键值对的集合,每个键对应一个值。Map 接口允许键值对具有唯一性,即同一个键只能对应一个值。
Map 接口的主要特点包括:
- 键的唯一性:Map 中的键是唯一的,不能包含重复的键。
- 允许空键和空值:Map 中可以包含空键和空值。
- 可以通过键来查找值:可以通过键来查找对应的值,并且可以根据需要修改、删除或者添加键值对。
二、Map 接口的常见实现类
Java 中常见的 Map 接口的实现类包括:
- HashMap:基于哈希表实现的键值对集合,无序且不保证键值对的顺序。
- TreeMap:基于红黑树实现的键值对集合,按键的自然顺序或者自定义顺序进行排序。
- LinkedHashMap:继承自 HashMap,内部使用双向链表维护键值对的顺序,可以保持键值对的插入顺序或者访问顺序。
在本文中,我们将主要介绍 HashMap 的使用。
三、使用示例
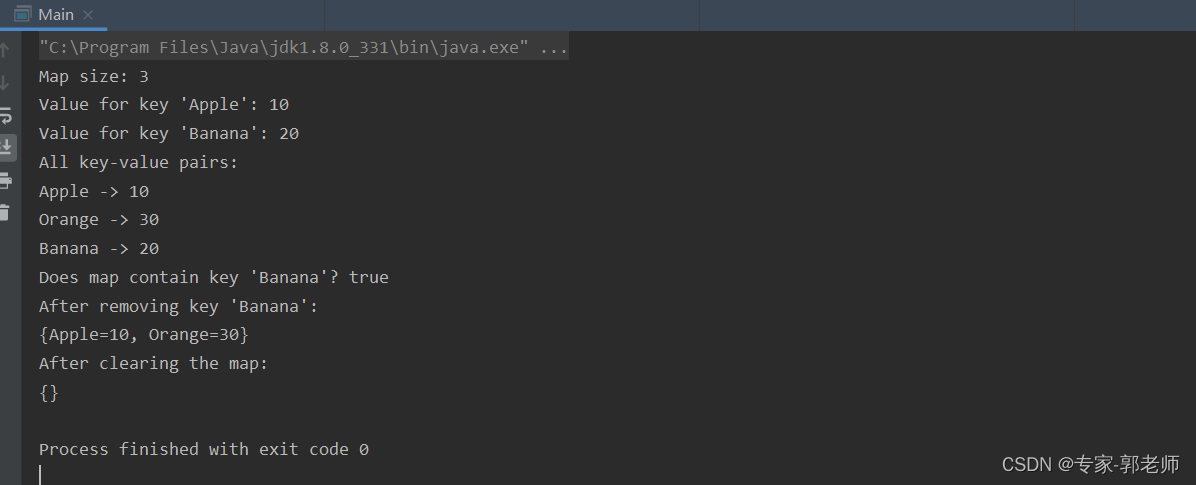
下面是一个使用 Map 接口的 HashMap 实现的示例代码:
import java.util.HashMap;
import java.util.Map;public class Main {public static void main(String[] args) {// 创建一个 HashMap 对象Map<String, Integer> myMap = new HashMap<>();// 添加键值对到集合myMap.put("Apple", 10);myMap.put("Banana", 20);myMap.put("Orange", 30);// 获取集合大小int size = myMap.size();System.out.println("Map size: " + size);// 访问集合中的值System.out.println("Value for key 'Apple': " + myMap.get("Apple"));System.out.println("Value for key 'Banana': " + myMap.get("Banana"));// 遍历集合并打印每个键值对System.out.println("All key-value pairs:");for (Map.Entry<String, Integer> entry : myMap.entrySet()) {System.out.println(entry.getKey() + " -> " + entry.getValue());}// 检查集合中是否包含某个键boolean containsKey = myMap.containsKey("Banana");System.out.println("Does map contain key 'Banana'? " + containsKey);// 删除集合中的某个键值对myMap.remove("Banana");System.out.println("After removing key 'Banana':");System.out.println(myMap);// 清空集合myMap.clear();System.out.println("After clearing the map:");System.out.println(myMap);}
}
四、 HashMap,TreeMap,LinkedHashMap区别
1、HashMap
- 数据结构:HashMap 基于哈希表实现,内部使用数组和链表/红黑树(JDK8+)来存储键值对。
- 无序性:HashMap 不保证键值对的顺序,即遍历时输出的顺序可能是随机的。
- 性能:HashMap 的插入、删除和查找操作的平均时间复杂度为 O(1),具有很好的性能。
- 允许空键和空值:HashMap 允许键和值都为 null。
2、TreeMap
- 数据结构:TreeMap 基于红黑树实现,内部使用红黑树来存储键值对,并且保持键的有序性。
- 有序性:TreeMap 会按键的自然顺序或者自定义顺序进行排序,因此遍历时输出的键值对是有序的。
- 性能:TreeMap 的插入、删除和查找操作的时间复杂度为 O(log n),比 HashMap 略慢。
- 不允许空键:TreeMap 不允许键为 null,但允许值为 null。
3、LinkedHashMap
- 数据结构:LinkedHashMap 继承自 HashMap,内部使用双向链表来维护键值对的顺序,可以保持插入顺序或者访问顺序。
- 有序性:LinkedHashMap 可以按照插入顺序或者访问顺序来遍历输出键值对。
- 性能:LinkedHashMap 的性能与 HashMap 类似,但由于额外维护了链表,可能会稍微慢一些。
- 允许空键和空值:LinkedHashMap 允许键和值都为 null。
4、输出排序情况示例
下面是一个示例,展示了对 HashMap、TreeMap 和 LinkedHashMap 进行添加元素后的输出排序情况:
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.TreeMap;public class Main {public static void main(String[] args) {// HashMap 示例Map<String, Integer> hashMap = new HashMap<>();hashMap.put("Banana", 2);hashMap.put("Apple", 1);hashMap.put("Orange", 3);hashMap.put("Cool", 5);hashMap.put("Door", 4);System.out.println("HashMap:");System.out.println(hashMap);// TreeMap 示例Map<String, Integer> treeMap = new TreeMap<>();treeMap.put("Banana", 2);treeMap.put("Apple", 1);treeMap.put("Orange", 3);treeMap.put("Cool", 5);treeMap.put("Door", 4);System.out.println("TreeMap:");System.out.println(treeMap);// LinkedHashMap 示例Map<String, Integer> linkedHashMap = new LinkedHashMap<>();linkedHashMap.put("Banana", 2);linkedHashMap.put("Apple", 1);linkedHashMap.put("Orange", 3);linkedHashMap.put("Cool", 5);linkedHashMap.put("Door", 4);System.out.println("LinkedHashMap:");System.out.println(linkedHashMap);}
}
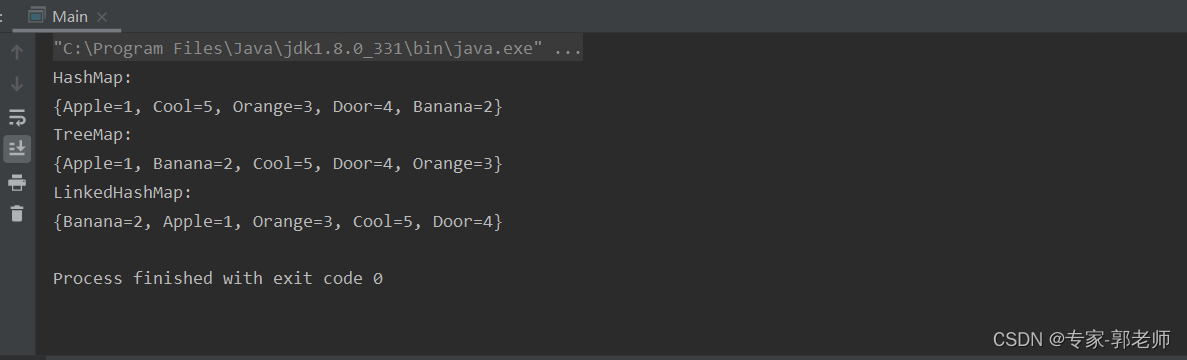
很明显:
- hashMap的输出,顺序是随机的。
- treeMap的输出,是根据字母自然排序的。是根据键的自然顺序或者通过传入的比较器(Comparator)进行排序的。
- linkedHashMap的输出,是按照你插入的顺序。
这里要注意一下,当你多次运行程序时,你会发现hashmap的输出趋向于有序?
这里解答下:
虽然 HashMap 不保证元素的顺序,但是在实际使用中,对于相同的哈希表大小和相同的哈希函数,相同的元素插入顺序往往会导致相同的哈希码分布,从而使得元素在哈希表中的位置趋于相同,进而使得元素的遍历顺序看起来是有序的。这种现象称为“桶中的元素顺序”。
但是,这种“有序性”仅仅是一种“看起来”的现象,实际上 HashMap 并不保证元素的顺序,因此不应该依赖于遍历结果的顺序。如果需要有序的遍历,应该使用 TreeMap 或者 LinkedHashMap,它们会根据键的自然顺序或者插入顺序进行有序遍历。
这篇关于【JAVA基础篇教学】第十篇:Java中Map详解说明的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





