本文主要是介绍【Linux杂货铺】文件系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
🌈前言🌈
📁 硬盘
📂 物理结构
📂 存储结构
📂 CHS定址法
📂 操作系统对硬盘的管理和抽象
📁 文件系统
📂 分区
📂 分组
📂 inode号
分配
📂 逆向路径解析
分区挂载
目录作用
📁 总结
🌈前言🌈
欢迎收看本期【Linux杂货铺】内容,本期主要讲解文件系统的概念,其中我们会先讲解什么是硬盘,硬盘的物理和逻辑结构分别是什么样子,最后会讲解操作系统是如何通过文件系统管理硬盘的。

📁 硬盘
📂 物理结构

硬盘也叫做磁盘,中间有一个盘面,盘面是可读可写可擦除的一个设备,每一个盘面都有一个磁头。盘面会进行高速旋转,磁头在马达和永磁铁的作用下,会左右摆动,通过电磁感应等方式,将0,1这样的数据存储在硬盘上。
所以硬盘本质上是一个机械设备。
📂 存储结构
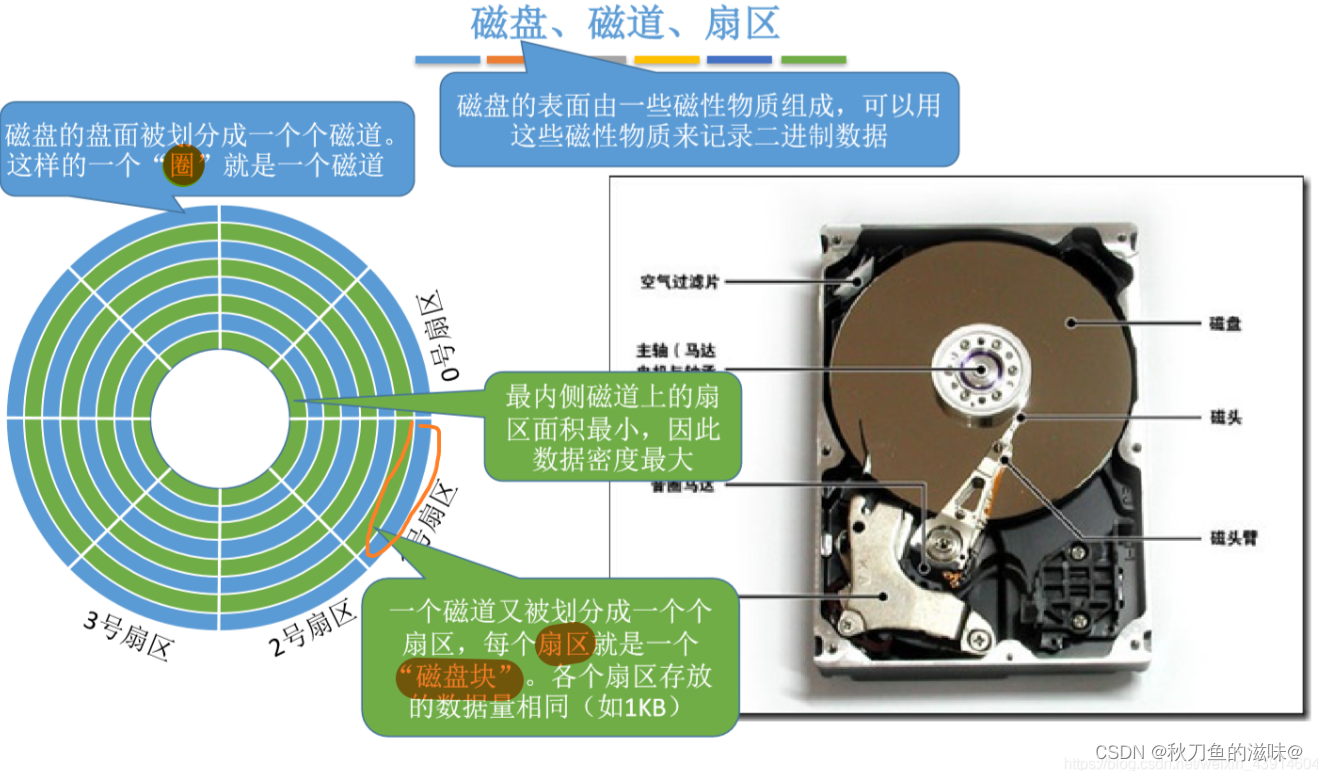
硬盘读写的基本单位就是:扇区(512 B 或者 4 KB)。
通过上图得出结论: 1片 = n个磁道(柱面) ; n个磁道(柱面)= m个扇区
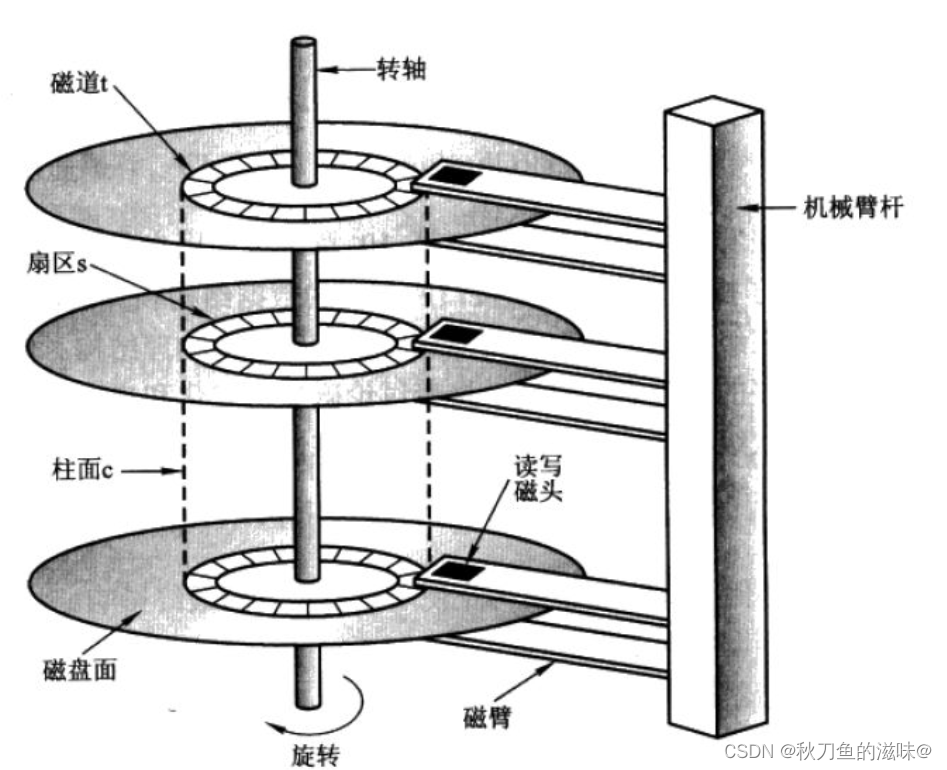
📂 CHS定址法
了解了磁盘上有盘片,柱面和扇区后,扇区就是磁盘读写的基本单位,想要找到数据,就要找到指定盘片上指定柱面上的指定扇区,这就是CHS定址法。
1. 找到指定的磁头(Header)
2. 找到指定的磁道/柱面(Cylinder)
3. 找到指定的扇区(Sector)
所以得出结论,盘片为什么要告诉旋转?定位指定扇区。磁头为什么要左右摆动?定位指定的磁道
📂 操作系统对硬盘的管理和抽象
如果OS直接使用CHS,耦合度太高(硬件改变,影响软件,软件也要改变),同时也为了方便实现内核进行磁盘管理,所以需要进行逻辑抽象。OS和磁盘进行交互的时候,基本单位是4KB(8个连续的Sector)。

我们将一个个圆的磁盘抽象成一个巨大的数组,每一个元素就是一个sector,我们就会有一个扇区数组 sector disk_array[N]。
有了数组,天然的就会有下标index,我们就可以使用下标,通过某种算法,转换为CHS地址,这样就进行了解耦。
举个例子,我们有个硬盘,每个面有1000个扇区,10个磁道,即每1个磁道有100个扇区。
index / 1000 = H
index % 1000 = temp [0 , 999]
temp / 100 = C
temp % 100 = S
我们先确定在哪个盘面,在确定在哪个柱面,最终定位到在哪个扇区。

OS每次操作只能是512B的话,效率太低。所以一般而言,磁盘访问的基本单位是512B,OS与磁盘交互的基本单位是4KB(8 * sector)。一次I/O读取更多数据,提高了效率。
8个连续的扇区,就称作数据块。每一个块都有一个块号,我们通过 块号 * 8 = index ,就能将块号转为sector数组下标,得到扇区的下标就能转为CHS地址。
所以对OS而言,读取数据,就以块为单位。
所以我们只要知道了硬盘大小,就能知道有多少个块,每个块的块号也就有了,知道了起始块的块号,连续的读8个sector下标,就能转换为对应的多个CHS地址。
这就是LBA(逻辑区块地址)。LBA可以意指某个数据区块的地址或是某个地址所指向的数据区块。
这样就得到了LBA数组,LBA block[N],通过对数组的管理,达到对硬盘的管理,就是先描述,再组织。
📁 文件系统
接下来,我们使用的是Linux中的ext2文件系统进行讲解。
📂 分区
概念:分区是将硬盘空间划分成独立的区域,每个区域可以被单独管理和使用。

📂 分组
我们只要管理好一个分区,就能使用相同标准管理好所有分区,进而管理好整个硬盘。
分完区后,还是太大,所以进行分组,管理好一个组,就能管理好每个组,进而管理好一个分区。这就是分支思想。

上图是磁盘文件系统。磁盘是典型的块设备,磁盘分区被划分为一个个block,一个block的大小是有格式化确定的,并不可以修改。
这就引入了文件系统的概念,通过文件系统管理好分组,进而管理好分区,从而管理好硬盘,每个分区有自己的文件系统,每个分区的文件系统可以不同。
此外,我们还需要知道,Linux中,文件的内容和属性分开存储。
Data blocks (数据区):存放文件内容。也是占据区域最大的。
Block Bitmap(块位图):记录者Data Block 中哪个数据块已经被占用,哪个数据块没有被占用。比特位的位置,表示块号,比特位的内容,表示该块是否被占用。
inode table (inode节点表):Linux中文件属性是一个大小固定的集合体,大小是128字节,inode内部不包含文件名,并且1个文件对应1个inode。所以在内核里,不看文件名,只看inode号。
Linux中,文件属性是一个大小固定的集合体(128 B)。其中最重要的字段是inode_num,即inode号,此外data[N]数组里面元素存储着存放内容的块的块号(N一般是15),分为一级,二级,三级等直接和间接映射。
ls -li //查看文件的,并且能查看到inode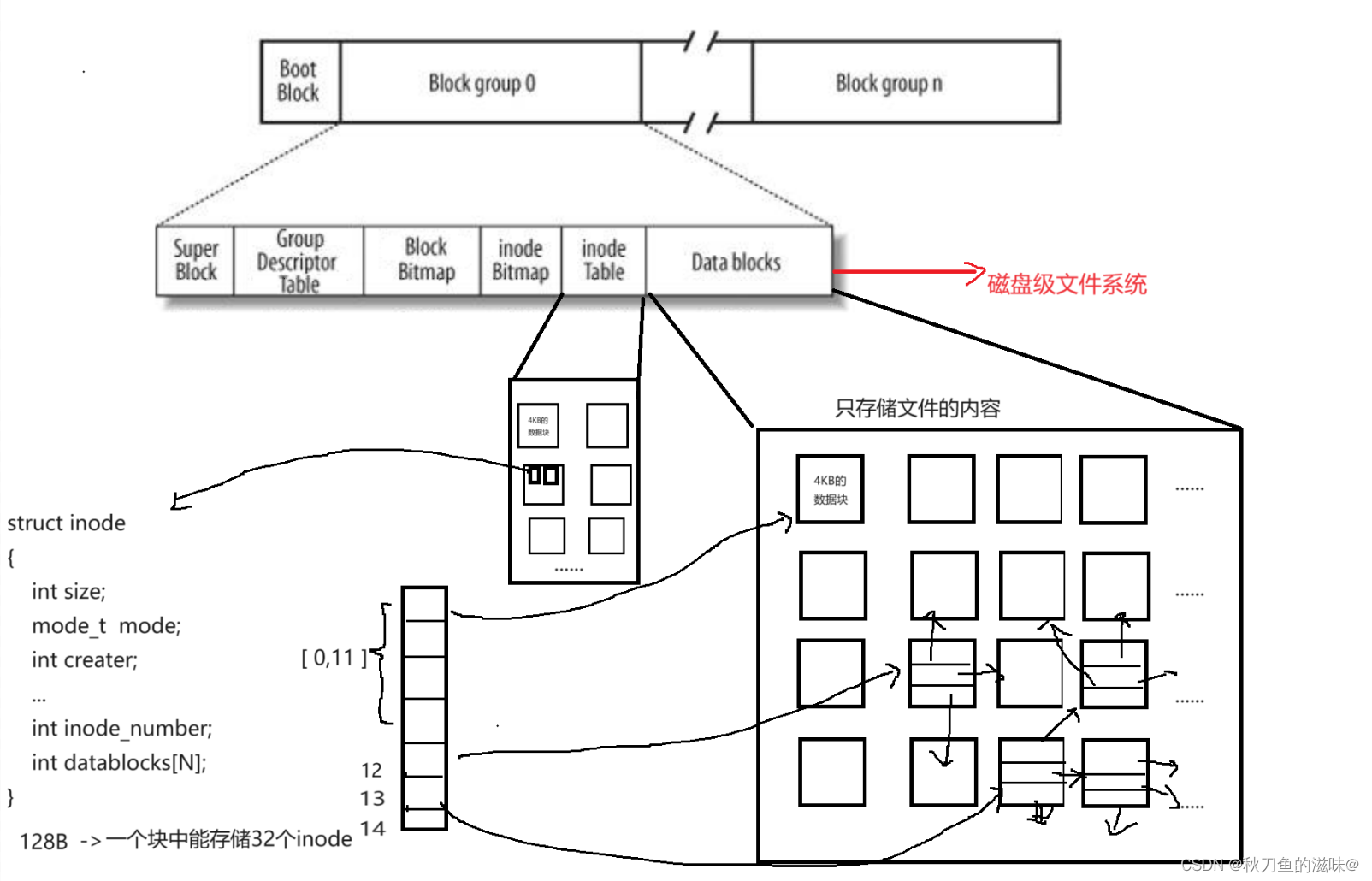
inode bitmap:比特位的位置表示第几个inode,内容表示该inode是否空闲可用。
GDT(块组描述符):块描述符,描述块组的信息。
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量, 未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的 时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个 文件系统结构就被破坏了。super block 存放在多个block中(2~3个),但不是每个block中都有。
以上我们就对文件系统有了基本的概念,所以我么将硬盘分区后,分组并且写入文件系统,这就是格式化。所以格式化的本质,就是在硬盘中写入文件系统。
📂 inode号
分配
inode编号的分配是以分区为单位进行分配。所以超级块 和 GDT 记录着每个分组的其实inode,结束inode,以此将inode分配个不同区域(分组)。inode bitmap 和 inode table是从0开始的,所以知道inode ,在 - 起始inode,就能对应到inode bitmap和i节点表中对应的下标,找到对应的文件属性,进而找到文件内容。
所以不同分区可能有相同的inode,但1个分区内不能有相同的inode。
Dateblock也是同样的原理,数据块也是整体分配,也有statr块号,end块号,有对应的块号也能映射到对应组的块号里面。
inode映射到对应的组后,优先使用当前组的数据块,除非文件非常大,否则不建议跨组访问。但 inode 和 数据块 是可以跨组访问的。
总结,在分区内知道了inode,就能确定在哪个分组,在组内减起始inode,就能找到inode bitmap,检测是否被用,再在i节点表中找到或存储inode属性,进而在数据块中找到对应的文件内容。
📂 逆向路径解析
前文中,我们讲解在内核中,操作一个文件,使用的是文件的inode,但用户使用的是文件名,所以文件名一定和inode存在映射关系。映射关系存储在哪呢?
目录,也是一个文件,文件内容就是 文件名 和 inode的映射关系。所以有了目录,就有了文件名和inode的映射关系。
但目录也是一个文件呀,所以目录也会查找自己的目录,找到自己的inode号,一直找到根目录为止,这就是所谓的逆向路径解析。
目录的r权限:是否允许度目录内容,即文件名:inode的映射关系,拿不到inode,就读不了。
目录的w权限:先当前目录写文件名:inode的映射关系
逆向路径解析是OS自己做的,根据文件路径,找到文件inode,这也就是为什么要有路径的原因了,也是为什么一个目录下不能建立同名文件。
但是逆向路径解析不是每一次都进行的,Linux会缓存常用的路径结构。
分区挂载
之前,我们都是在一个分区内知道了inode,但是我们如何知道我们在哪个分区呢?在Linux中,分区需要挂载到指定目录,即将分区和目录进行关联,进入分区就是进入目录。
目录作用
1. 确定在哪个分区 ;
2. 文件名:inode的映射关系,找到指定文件的inode
那么目录/路径谁提供的呢?我 或者 进程已经提供了。即内核文件系统提前写入并组织好,然后我们提供的。
例如,打开一个文件open(),第一个参数需要你提供文件名,open早就提供了cwd(当前路径),拼接上你的文件名,就能得到一个路径,然后找到inode,进而创建或读写文件内容。
总结一下:文件的创建,会在目录下创建,而路径是由内核文件系统提起写入并组织好,我们提供文件名拼接形成。如进程的cwd(存储当前路径) + 文件名 ,从而在指定目录下创建文件。再根据路径的前缀确定在哪个分区,在指定分区下申请位图,块,属性等资源,进行文件操作。
📁 总结
以上,我们就对Linux中的文件系统做了详解,开始,我们介绍了硬盘这一物理设备,介绍了它的物理结构,存储结构以及OS如何管理硬盘,之后,我们讲解什么OS如何通过文件系统管理好分组,进而管理好分区,从而管理好整个硬盘。最后,讲解了inode是如何来的,目录和分区的关系,总结了如何创建,读写文件的。
以上,就是本期【Linux杂货铺】的主要内容了,如果感觉本期内容对你有帮助,欢迎点赞,收藏,关注 Thanks♪(・ω・)ノ

这篇关于【Linux杂货铺】文件系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



