本文主要是介绍[机器学习与深度学习] - No.2 遗传算法原理及简单实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
遗传算法(Genetic Algorithm),顾名思义,就是模拟物种进化的过程,遵循“物竞天择,适者生存”的原则,随机化搜索的算法。遗传算法模拟种群演化过程,经历“选择”,“基因交叉”,“变异”等过程。遗传算法不保证一定能得到解,如果有解也不保证找到的是最优解,但若干代以后,理想状态下,染色体的适应度可能达到近似最优的状态。
遗传算法的最大优点就是,我们不需要知道怎么去解决一个问题,获得最优解。你需要知道的仅仅是,怎么将解空间中的值进行编码,使得它能能被遗传算法机制所利用,遗传算法会为我们挑选出可能最优的解。
遗传算法组成如下:
- 将染色体编码
- 计算种群的适应度函数值
- 进行选择,交叉,变异,获取新一代的染色体
- 重复步骤2,直到迭代数或者适应度函数值收敛
1. 编码:
使用遗传算法首先就是要对问题的解,编码成一定形式,才能使用遗传算法。常用的二进制编码方式是二进制编码。例如:我们需要求解以下函数的在[0,9]上的极大值
假设我们要求精度为0.0001,即小数点后四位,那么我们将[0,9]区间分为 (9 - 0 ) /0.0001 = 90000等分
我们使用二进制编码。我们知道3位二进制编码可以表示 23−1 2 3 − 1 个数字。由于 216<90000<217 2 16 < 90000 < 2 17 ,所以我们至少需要17位二进制编码来表示我们的解。每个解均被表示成17位的二进制数。
任意一个17位二进制数,可用如下公式解码到[0,9]
x = 0 + decimal(chromosome)×(9-0)/(2^17-1)一般化的解码公式:
x = lower_bound + decimal(chromosome)×(upper_bound-lower_bound)/(2^chromosome_size-1)2. 适应度函数
用于评价某个染色体的适应度,用 f(x) f ( x ) 表示。有时需要区分染色体的适应度函数与问题的目标函数。适应度函数与目标函数是正相关的,可对目标函数作一些变形来得到适应度函数。但是,对于我们这种,求函数极大值的问题,可以将目标函数作为适应度函数。如果一个染色体,目标函数值大,那么它对应的适应度函数值也应该大。
3. 选择
按照一定的策略,选择一些染色体来产生下一代。轮盘法是一种 “比例选择”,也就是个体被选中的概率与其适应度函数值成正比。适应性分数最高的成员不一定能选入下一代,但是它有最大的概率被选中。
我们设 {p(i)|i=1..n} { p ( i ) | i = 1.. n } 为个体 i i 被选中的概率,那么显然 。我们使用 S() S ( ) 集合来保存第n次选择的结果,轮盘赌算法的(伪代码)实现如下:
for i = 1:nr = rand() %产生一个 [0 - 1] 之间的随机数ps = 0 %轮盘初始转动的位置,从0变化到1j = 1while ps < r %终止条件为轮盘转动的位置超过色子位置ps = ps + p(j) %轮盘转动j = j + 1ends(i) = j - 1 %轮盘停止时色子停留位置所指示的个体举个例子:
| 染色体 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 种群适应度 | 5 | 7 | 9 | 12 | 15 | 30 |
| 种群累计适应度 | 5 | 12 | 21 | 33 | 48 | 78 |
| 选中随机数区间 | [0 - 0.06] | [0.06 - 0.15] | [0.15-0.27] | [0.27 - 0.42] | [0.42 - 0.62 ] | [0.62 - 1] |
| 被选中概率 | 0.06 | 0.09 | 0.12 | 0.15 | 0.20 | 0.38 |
可以看出,种群适应度越高的染色体越容易被留下产生下一代
精英(Elitist Strategy)选择:为了防止进化过程中产生的最优解被交叉和变异所破坏,可以将每一代中的最优解原封不动的复制到下一代中。
4. 交叉
我们从刚刚选择的种群中选出 2个染色体,同时生成其值在0到1之间一个随机数,然后根据此数据的值来确定两个染色体是否要进行杂交。一般设置杂交率为0.6,如果该随机数小与0.6,我们就对两个染色体进行杂交。交叉算子分为单点交叉、两点交叉等。在程序中我选择的是两点交叉,随机生成两个在[0,chromosome_length] 之间的随机数,作为基因杂交的位置,将该位置的两个基因进行交换,产生两个子染色体
杂交位置为(3,5)
杂交前:
111222333
aaabbbccc
杂交后:
111bbb333
aaa222ccc
5. 变异
遗传算法中的变异运算,是指将个体染色体编码串中的某些位置上的基因值用该位置上其它等位基因来替换,从而形成以给新的个体。在我们程序的视线中,基因变异即将该位置的基因由0变为1,或由1变为0
我们选出任意一个染色体,同时生成其值在0到1之间一个随机数,然后根据此数据的值来确定该染色体是否要进行变异。变异率一般设为0.02
我们以上面提到的函数为例,编写程序,计算极大值:
函数图像:
程序运行截图:
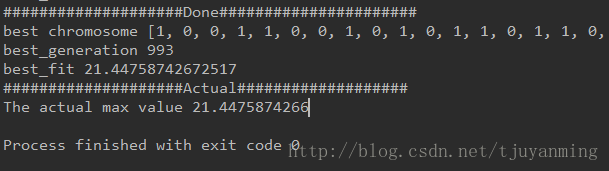
可以看到,使用scipy计算得到的值为21.4475874266,遗传算法得到的值为21.4475874267,可以看作为近似最优
完整程序:
# -*- coding: utf-8 -*-
# @Author :yenming
# @Time :2018/4/10 16:10import numpy as np
import math
from scipy.optimize import fmin,fminbounddef obj_function(x):return x + 10 * math.sin(5*x) -7 * math.cos(4*x)#二进制转十进制
def bin2dec(bin):res = 0max_index = len(bin) - 1for i in range(len(bin)):if bin[i] == 1:res = res + 2**(max_index-i)return res#获取特定精度下,染色体长度
def get_encode_length(low_bound,up_bound,precision): # e.g 0,9,0.01divide = (up_bound - low_bound)/precisionfor i in range(10000):if 2**i < divide < 2**(i + 1):return i+1return -1#将二进制的染色体解码成[low,up]空间内的数
def decode_chromosome(low_bound,up_bound, length, chromosome):return low_bound + bin2dec(chromosome)*(up_bound - low_bound)/(2**length -1)#定义初始染色体
def intial_population(length,population_size):chromosomes = np.zeros((population_size,length),dtype=np.int8)for i in range(population_size):chromosomes[i] = np.random.randint(0,2,length) #随机数[0,2)之间的整数return chromosomes##########hyperparameter##############
# f(x) = x + 10*sin(5x) -7*cos(4x)
population_size = 500 #种群大小
iselitist = True #是否精英选择
generations = 1000 #演化多少代
low_bound = 0 #区间下界
up_bound = 9 #区间上界
precision = 0.0000001 #精度
chromosome_length = get_encode_length(low_bound,up_bound,precision) #染色体长度
populations = intial_population(chromosome_length,population_size) #初始种群
best_fit = 0 #获取到的最大的值
best_generation = 0 #获取到最大值的代数
best_chromosome = [0 for x in range(population_size)] #获取到最大值的染色体
fitness_average = [0 for x in range(generations)] #种群平均适应度
cross_rate = 0.6 #基因交叉率
mutate_rate = 0.01 #基因变异率
#######################################计算种群中每个染色体的适应度函数值(在这个问题中,适应度函数就是目标函数)
def fitness(populations):fitness_val = [0 for x in range(population_size)]for i in range(population_size):fitness_val[i] = obj_function(decode_chromosome(low_bound,up_bound,chromosome_length,populations[i]))return fitness_val#对种群染色体根据适应度函数进行排序,适应度函数值高的在最后
def rank(fitness_val,populations,cur_generation):global best_fit,best_generation,best_chromosomeglobal fitness_averagefitness_sum = [0 for x in range(len(populations))] #初始化种群累计适应度#population_size,length = populations.shapefor i in range(len(populations)): #冒泡排序按照种群适应度从小到大min_index = ifor j in range(i+1,population_size):if fitness_val[j] < fitness_val[min_index]:min_index = jif min_index!=i:tmp = fitness_val[i]fitness_val[i] = fitness_val[min_index]fitness_val[min_index] = tmptmp_list = np.zeros(chromosome_length)for k in range(chromosome_length):tmp_list[k] = populations[i][k]populations[i][k] = populations[min_index][k]populations[min_index][k] = tmp_list[k]#########种群适应度从小到大排序完毕#########for l in range(len(populations)): #获取种群累计适应度if l == 1:fitness_sum[l] = fitness_val[l]else:fitness_sum[l] = fitness_val[l] + fitness_val[l-1]fitness_average[cur_generation] = fitness_sum[-1]/population_size #每一代的平均适应度,在这个算法程序中没有使用到,仅作记录if fitness_val[-1] > best_fit: #更新最佳适应度及其对应的染色体best_fit = fitness_val[-1]best_generation = cur_generationfor m in range(chromosome_length):best_chromosome[m] = populations[-1][m]return fitness_sum#根据当前种群,按照轮盘法选择新一代染色体
def select(populations,fitness_sum,iselitist): #轮盘选择法,实现过程可看为二分查找population_new = np.zeros((population_size, chromosome_length), dtype=np.int8)for i in range(population_size):rnd = np.random.rand()*fitness_sum[-1]first = 0last = population_size-1mid = (first+last)//2idx = -1while first <= last:if rnd >fitness_sum[mid]:first = midelif rnd < fitness_sum[mid]:last = midelse:idx = midbreakif last - first == 1:idx = lastbreakmid = (first + last) // 2for j in range(chromosome_length):population_new[i][j] = populations[idx][j]if iselitist == True: #是否精英选择,精英选择强制保留最后一个染色体(适应度函数值最高)p = population_size - 1else:p = population_sizefor k in range(p):for l in range(chromosome_length):populations[k][l] = populations[k][l]#基因交叉
def crossover(populations):for i in range(0,population_size,2):rnd = np.random.rand()if rnd < cross_rate:rnd1 = int(math.floor(np.random.rand()*chromosome_length))rnd2 = int(math.floor(np.random.rand()*chromosome_length))else:continueif rnd1 <= rnd2:cross_position1 = rnd1 #这里我选择了一个基因片段,进行两点的交叉cross_position2 = rnd2else:cross_position1 = rnd2cross_position2 = rnd1for j in range(cross_position1,cross_position2):tmp = populations[i][j]populations[i][j] = populations[i+1][j]populations[i+1][j] = tmp
#基因变异
def mutation(populations):for i in range(population_size):rnd = np.random.rand()if rnd < mutate_rate:mutate_position = int(math.floor(np.random.rand()*chromosome_length))else:continuepopulations[i][mutate_position] = 1 - populations[i][mutate_position]#演化generations代
for g in range(generations):print("generation {} ".format(g))fitness_val = fitness(populations)fitness_sum = rank(fitness_val,populations,g)select(populations,fitness_sum,iselitist)crossover(populations)mutation(populations)print("best chromosome", best_chromosome)print("best_generation", best_generation)print("best_fit", best_fit)print("####################Done######################")
print("best chromosome",best_chromosome)
print("best_generation",best_generation)
print("best_fit",best_fit)print("####################Actual###################")def func(x):#使用fmincound 将函数取负,求最小值return -obj_function(x)min_global=fminbound(func,0,9)#这个区域的最小值
print("The actual max value",-func(min_global))
x = [0,1,2,3,4,5,6,7,8,9]
y = [i + 10 * np.sin(i*5) -7 * np.cos(i*4) for i in x]
import matplotlib.pyplot as plt
plt.plot(x,y)
plt.show()参考文章:
https://www.zhihu.com/question/23293449
http://blog.jobbole.com/110913/
https://blog.csdn.net/zzwu/article/details/561620
这篇关于[机器学习与深度学习] - No.2 遗传算法原理及简单实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



