本文主要是介绍创新实训2024.04.11日志:self-instruct生成指令,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 参考文献
- 代码:https://github.com/yizhongw/self-instruct
- 论文:https://arxiv.org/abs/2212.10560
2. 前沿论文阅读
2.1. self-instruct技术的优势
作者在文章中提到:
The recent NLP literature has witnessed a tremendous amount of activity in building models that can follow natural language instructions.These developments are powered by two key components: large pretrained language models (LM) and human-written instruction data.However, collecting such instruction data is costly and often suffers limited diversity given that most human generations tend to be popular NLP tasks, falling short of covering a true variety of tasks and different ways to describe them. Continuing to improve the quality and coverage of instruction-tuned models necessitates the development of alternative approaches for supervising the instruction tuning process.
简单来说,传统的NLP技术需要涉及两大不可或缺的步骤:大型的预训练好的大语言模型以及人工搜集的语料(指令数据)。而搜集这些语料非常费工费时。因此需要一个替代的方式来生成语料并监督这个过程。
换句话说,我们不用自己搜集成千上万条语料了,而是由上百条初始的语料生成一个大规模的语料库并用于训练。
2.2. Working Pipeline
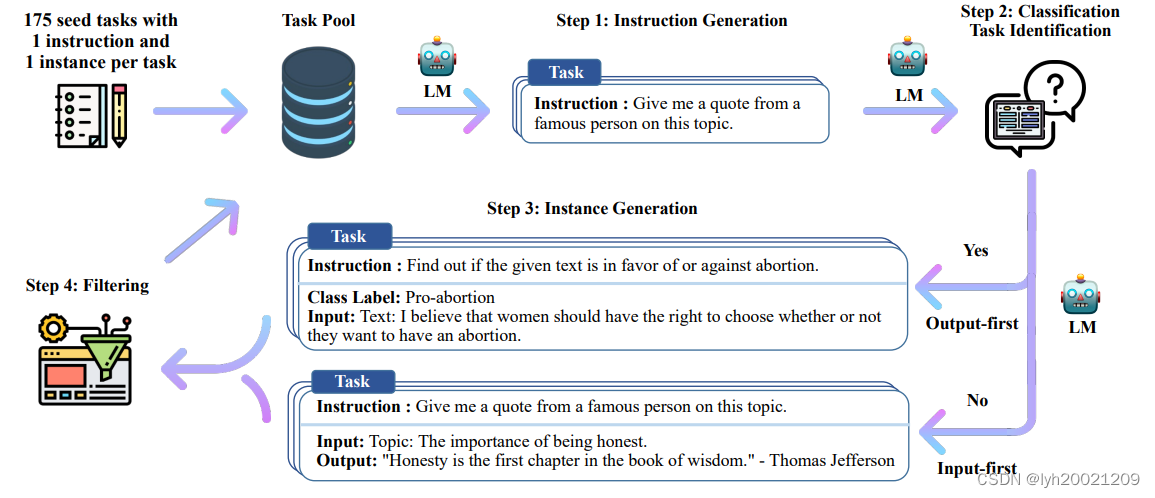
截图来自于论文。
简单来说,我们把一个初始的种子指令库输入到任务池中,随后每次从任务池中挑选一定批量的指令作为询问大模型的输入,并将其分为两类:
- 第一类是分类问题,采用Output-first模式。也就是先打上一个分类的标签(Class Label),然后根据这个标签去生成问题。
- 第二类是非分类问题,采用Input-first模式。也就是先生成问题,然后再生成回答。
不过我们的语料库中,没有分类问题,因此统一采用了Input-first模式。
最后计算生成的指令与已有指令的相似度,如果过高,则应该舍弃这条新的指令。
3. 基于ChatGLM-4的self-instruct
智谱AI提供了国产开源大模型ChatGLM系列,我们打算基于这个系列的LM,为后续的训练生成需要的指令。
3.1. 智谱AI开发者注册
智谱AI开发平台:智谱AI开发平台
用一个没注册过的手机号就能注册进去。现在他们家搞活动,新用户注册还送token(请求ChatGLM回答的必要资源),500w个,在财务管理->资源包管理可以查看:

还有个比较重要的,是调用API时需要的key。可以在查看APIkey中看到:

如果需要调用智谱的API,可以查看文档:智谱AI开放平台 (bigmodel.cn)
3.2. 初始化Seed Instructions
self-instruct技术需要初始化一些种子指令并加入Task pool,用来迭代生成新的问题,这个技术可以大幅减少人工搜集语料的成本,但不代表一点人工搜集的过程都没有。一开始的初始语料还是需要我们自己搜集的。
在做前期准备工作的时候,团队就已经搜集了一批有关易学的问答对,根据step1:Instruction Generation,我们把这批问答对的问题作为instruction输入LM。
可能会疑惑的是,一个完整的task,包括了instruction,input和output。为什么这里可以直接用input替代instruction呢?关于这一点,这项技术的提出者在文章中写到:
Note that the instruction and instance input does not have a strict boundary in many cases. For example, “write an essay about school safety” can be a valid instruction that we expect models to respond to directly, while it can also be formulated as “write an essay about the following topic” as the instruction, and “school safety” as an instance input.
需要注意的是,指令和实例的输入(也即问题)在定义上很多时候并没有严格意义的边界。例如,”写一篇有关校园安全的短文“可以是一个合法的、我们期望LM直接回答的问题,但当他变成”写一篇有关下述主题的短文“,就成了一个指令,随后”校园安全“可以作为一个实例的输入(也即问题)。
在无法严格区分instruction和input时,我们为了数据格式的多样性,可以直接拿input代替instruction。
作为初始种子指令的instruction如下(其实就是我上一篇日志中,通过易学百科全书提取出来的QA对):

这里不会把所有内容放出来,因为这是团队成员共同努力的成果,我没有理由把它随意共享到网络上。如果你有正当的理由查看这些语料文档,请通过合法渠道联系我。
3.3. 迭代生成新的指令
(1)连接智谱AI服务器
首先我们要连接上智谱AI的服务器:
client = ZhipuAI(api_key="xxx") # 填写你自己的APIKey这里为了保护我自己的隐私,这个key我用xxx替换掉了,如果你想通过我的代码复现这个过程,请自己注册账号并填写key。
(2)打开种子指令与迭代指令文件
然后我们打开存储了种子指令的excel表格,以及迭代生成的指令的txt文件(一开始我们可以把种子指令直接放到这个txt文件中作为迭代生成的一部分)
# 打开 Excel 文件workbook = load_workbook(origin_QA)# 获取工作表sheet = workbook.active# 遍历行和列input_list = []output_list = []for row in sheet.iter_rows(min_row=2, max_row=97, values_only=True):input_list.append(list(row)[0])output_list.append(list(row)[1])print(input_list)print(output_list)with open("./self_instruct/target/generation_instruction.txt", 'r', encoding="UTF-8") as file2:generation_instructions_list = file2.readlines()(3)判断是否结束迭代
随后看一下迭代生成的指令是否达到5000条(5000条是用来训练大模型的语料数量的下限),如果没达到5000条,我们就开启本轮迭代更新,否则就退出程序:
if len(generation_instructions_list) >= 5000:break(4)挑选本轮迭代的语料
之后,根据step1:Instruction Generation,从种子指令中挑选5条,迭代生成的指令中挑选5条(可能会重复,但不用担心,最后我们会去重的)。原文中是28开,这里试了几个参数后,决定是55开比较好:
# 随机从种子指令和生成指令中取5条seed_instructions = random.sample(input_list, 5)generation_instructions = random.sample(generation_instructions_list, 5)(5)请求大模型
拿到这部分语料后,我们就可以向大模型提问了,让他基于这些指令,自己再生成一批指令。这里就要写一个需求明确、逻辑清晰的prompt来提示大模型:
# 建立模版prompt = "你是一名精通周易的专家,下面是一些与周易相关的问题:\n"for index, instruction in enumerate(seed_instructions):prompt += f"{str(index + 1)}、问题:{instruction.strip()}\n"for index, instruction in enumerate(generation_instructions):prompt += f"{str(index + 6)}、问题:{instruction.strip()}\n"prompt += "请参考上面问题的内容和形式,对上述问题进行补充和拓展,再提出10个关于周易的比较深入的问题"print(prompt)因为我们的语料是10条,所以这里问他也是问了10条。
之后就可以调用api,向chatGLM4提出请求了:
# 向GLM4提问并返回答案response = client.chat.completions.create(model="glm-4", # 填写需要调用的模型名称messages=[{"role": "user","content": prompt}],)(6)正则表达式提取响应的instruction
得到响应后,从返回的message中提取出问题:
# 提取问题questions = extract_questions(response.choices[0].message.content)for i, question in enumerate(questions, start=1):print(f"{question}")这里chatGLM响应的问题的格式和我们提问的格式是一样的,都是一个索引+.+问题:+问题内容。所以就可以用正则表达式去匹配文本,提取问题内容。总结一下这个模式串的格式,应该为:
- 以一串数字开始(可能后面有空白字符)。
- 接着可能有一个中文顿号或英文句号(也可能没有),并可能后面有空白字符。
- 然后是“问题”这个词,并可能后面有空白字符。
- 接着可能有一个中文冒号或英文冒号(也可能没有),并可能后面有空白字符。
- 最后是任意数量的任意字符,直到字符串的结束。
因此正则表达式串为:
^\d+\s*[、.]?\s*问题\s*[::]?\s*(.*)$
逻辑为:
^\d+:
^:表示匹配字符串的开始。\d+:匹配一个或多个数字(\d是数字的简写,+表示一个或多个)。
\s*:
\s:匹配任何空白字符,包括空格、制表符、换页符等。*:表示前面的字符(在这里是\s)可以出现零次或多次。
[、.]?:
[、.]:匹配中文顿号(、)或英文句号(.)。?:表示前面的字符(在这里是[、.])是可选的,即可以出现零次或一次。
\s*:再次匹配零个或多个空白字符。
问题:
- 匹配字面字符串“问题”。
\s*:再次匹配零个或多个空白字符。
[::]?:
[::]:匹配中文冒号(:)或英文冒号(:)。?:表示前面的字符(在这里是[::])是可选的,即可以出现零次或一次。
\s*:再次匹配零个或多个空白字符。
(.*)$:
.*:匹配任意数量的任意字符(.表示任意字符,*表示零个或多个)。$:表示匹配字符串的结束。- 括号
()用于捕获匹配的子字符串。
# 将模型的回答转换成问题的列表
def extract_questions(text):# 使用正则表达式匹配以数字、空格、英文句号和冒号开头的行pattern = r'^\d+\s*[、.]?\s*问题\s*[::]?\s*(.*)$'questions = []# 遍历文本的每一行for line in text.split('\n'):# 使用正则表达式进行匹配match = re.match(pattern, line)if match:question = match.group(1).strip() # 提取匹配的问题,并去除两端的空格questions.append(question)return questions(7)判断生成的指令是否与先前的指令重复
新生成的指令可能和早先已经生成的指令相似(甚至重复),我们要把这样的指令剔除掉。jieba分词器组件提供了计算语料相似程度的API:
# 计算bleu
def calculate_bleu(reference, hypothesis):reference_tokens = list(jieba.cut(reference))hypothesis_tokens = list(jieba.cut(hypothesis))smoothing_function = SmoothingFunction().method7score = sentence_bleu([reference_tokens], hypothesis_tokens, smoothing_function=smoothing_function)return score对于短文本(比如这里的一个指令,采取BLEU分数来评估相似度比较合适;对于长文本,使用ROUGE_L分数比较合适)
jieba.cut用于对中文文本进行分词。SmoothingFunction().method7提供了一种平滑方法,用于处理BLEU分数计算中可能出现的零分问题。sentence_bleu计算BLEU分数,它接受一个参考句子的分词列表(在这里是一个列表的列表,因为我们只有一个参考句子),一个假设句子的分词列表,以及一个平滑函数。
如果相似度在0.7以下,我们认为可以作为新的指令纳入Task Pool:
# 指令存储到文件for question in questions:max_rouge = 0for generation_instruction in generation_instructions_list:bleu = calculate_bleu(question, generation_instruction)if bleu > max_rouge:max_rouge = bleuif max_rouge < 0.7:print(f"录入:{question}")file.write(question + '\n')3.4. 运行过程

4. 开源与复现
https://github.com/Liyanhao1209/ZhouYiLLM.git
python_scripts分支。
这篇关于创新实训2024.04.11日志:self-instruct生成指令的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



