本文主要是介绍ELFK (Filebeat+ELK)日志分析系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一. 相关介绍
Filebeat:轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。常应用于 EFLK 架构当中。行解析
filebeat 结合 logstash 带来好处:
1)通过 Logstash 具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻 Elasticsearch 持续写入数据的压力
2)从其他数据源(例如数据库,S3对象存储或消息传递队列)中提取
3)将数据发送到多个目的地,例如S3,HDFS(Hadoop分布式文件系统)或写入文件
4)使用条件数据流逻辑组成更复杂的处理管道
Fluentd:是一个流行的开源数据收集器。由于 logstash 太重量级的缺点,Logstash 性能低、资源消耗比较多等问题,随后就有 Fluentd 的出现。相比较 logstash,Fluentd 更易用、资源消耗更少、性能更高,在数据处理上更高效可靠,受到企业欢迎,成为 logstash 的一种替代方案,常应用于 EFK 架构当中。在 Kubernetes 集群中也常使用 EFK 作为日志数据收集的方案。
在 Kubernetes 集群中一般是通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。 它通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。

二. 搭建ELFK
Filebeat+ELK 部署
在ELK的基础上,再加一台 filebeat 机器

2.1 安装 Filebeat

2.2 设置 filebeat 的主配置文件

修改主配置文件
vim filebeat.yml
filebeat.prospectors:
- type: log #指定 log 类型,从日志文件中读取消息enabled: truepaths:- /var/log/messages #指定监控的日志文件- /var/log/*.logfields: #可以使用 fields 配置选项设置一些参数字段添加到 output 中service_name: filebeatlog_type: logservice_id: 192.168.44.40--------------Elasticsearch output-------------------
(全部注释掉)----------------Logstash output---------------------
output.logstash:hosts: ["192.168.44.70:5044"] #指定 logstash 的 IP 和端口
启动 filebeat
filebeat -e -c filebeat.yml
在 Logstash 组件所在节点上新建一个 Logstash 配置文件
input {beats {port => "5044"}
}
output {elasticsearch {hosts => ["192.168.44.60:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}
启动 logstash
启动 logstash
logstash -f logstash.conf下面这个不开启会报错,起不来

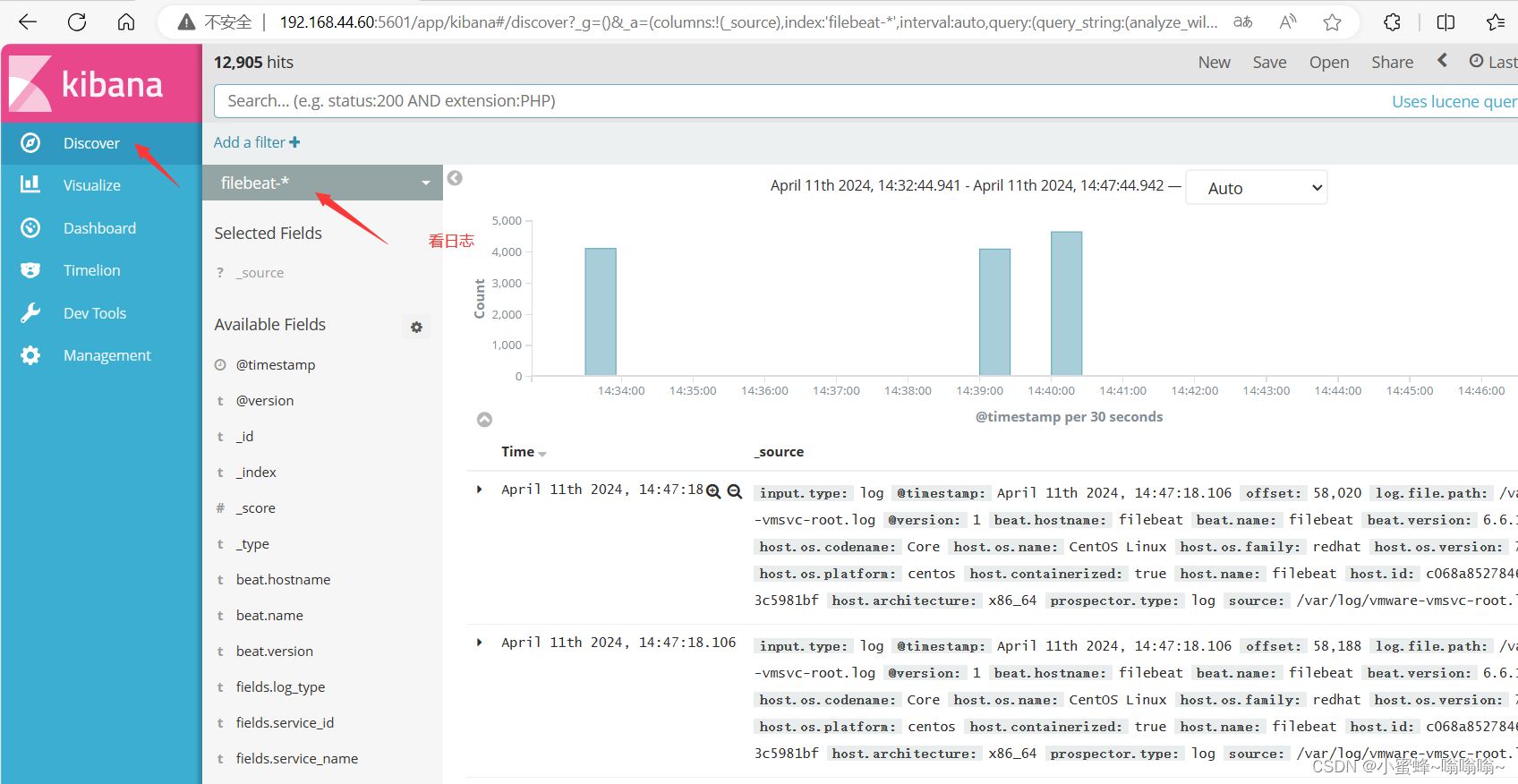
浏览器访问 http://192.168.44.60:5601 登录 Kibana,
单击“Create Index Pattern”按钮添加索引“filebeat-*”,
单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。

这篇关于ELFK (Filebeat+ELK)日志分析系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






