本文主要是介绍k8s 控制器StatefulSet原理解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🐇明明跟你说过:个人主页
🏅个人专栏:《Kubernetes航线图:从船长到K8s掌舵者》 🏅
🔖行路有良友,便是天堂🔖
目录
一、前言
1、k8s概述
2、有状态服务和无状态服务
二、StatefulSet基本概念
1、StatefulSet特性
2、StatefulSet与Deployment、DaemonSet的对比
三、StatefulSet核心组件
1、Headless Service
2、VolumeClaimTemplates
四、StatefulSet的工作原理
1、Pod名称与网络标识的确定性
2、存储卷的动态分配与绑定
3、故障恢复与重建机制
一、前言
1、k8s概述
Kubernetes单词起源于希腊语, 是“舵手”或者“领航员、飞行员”的意思。
Kubernetes(简称K8s)的前世今生可以追溯到谷歌(Google)内部的一个项目,它起源于2003年,当时谷歌正面临着不断增长的应用程序和服务的管理挑战。这个项目最初被称为"Borg",是一个早期的容器编排系统。Borg 的成功经验成为 Kubernetes 开发的契机。
有关k8s起源的介绍,请参考《初识K8s之前世今生、架构、组件、前景》这篇文章

Kubernetes的优点包括可移植性、可伸缩性和扩展性。它使用轻型的YAML清单文件实现声明性部署方法,对于应用程序更新,无需重新构建基础结构。管理员可以计划和部署容器,根据需要扩展容器并管理其生命周期。借助Kubernetes的开放源代码API,用户可以通过首选编程语言、操作系统、库和消息传递总线来构建应用程序,还可以将现有持续集成和持续交付(CI/CD)工具集成。

2、有状态服务和无状态服务
1.有状态服务(Stateful Service):
- 有状态服务在处理请求时会在多个请求之间维护一些状态信息,这些状态信息可能包括用户会话信息、缓存数据、数据库连接等。这些状态信息会被保存在服务的内存、数据库或其他持久化存储中。
- 有状态服务会对每个请求的处理结果依赖于之前的请求状态,因此需要保持一致的状态信息。这可能会导致在水平扩展时出现一些问题,因为需要确保每个请求都被路由到正确的具有相同状态的实例上。
- 典型的有状态服务包括数据库服务、消息队列服务和一些分布式系统的状态节点。
2.无状态服务(Stateless Service):
- 无状态服务在处理请求时不会保存任何状态信息,每个请求都是独立的,不依赖于之前的请求状态。服务会根据请求的参数和当前的环境进行计算和处理,并返回结果。
- 无状态服务通常会将状态信息保存在外部的存储系统中,如数据库或缓存中。每个请求处理完成后,服务不会保留任何状态,因此可以轻松实现水平扩展,通过增加更多的实例来处理更多的请求。
- 典型的无状态服务包括Web服务器、负载均衡器、静态文件服务器和一些微服务架构中的服务。

总结起来说,无状态服务通常包括前后端代码、中间件等这些不需要做数据持久化的服务,因为这些服务不用担心因故障导致的服务重建而造成的数据丢失。
而有状态服务通常指数据库和消息队列,比如说MySQL、ES、kafka等需要做数据持久化的服务,因为这些服务所在的Pod如果没有数据持久化,一旦Pod重启或飘逸,就会丢失数据。
二、StatefulSet基本概念
1、StatefulSet特性
StatefulSet是Kubernetes中用于管理有状态应用的控制器。与Deployment不同,StatefulSet维护了有状态应用的稳定标识符,并且为每个Pod分配了一个唯一的标识符。这使得StatefulSet非常适合运行需要稳定标识符的应用程序,例如数据库。
以下是StatefulSet的一些主要特性:
- 稳定的网络标识符:每个StatefulSet中的Pod都具有稳定的网络标识符,可以通过其索引或名称进行访问。这些标识符会随着Pod的重启而保持不变。
- 有序部署和扩展:StatefulSet可以确保Pod按照指定的顺序进行部署和扩展。这对于有状态应用程序非常重要,因为它们通常需要在集群中的不同节点上以特定的顺序启动。
- 稳定的存储:StatefulSet可以为每个Pod提供独立的持久化存储。这些存储卷可以在Pod重启时保持不变,确保数据的持久性。
- 有状态的服务发现:StatefulSet会为每个Pod分配一个唯一的DNS名称,可以通过该名称进行服务发现。这使得有状态应用程序可以通过DNS名称进行通信,而不必担心Pod的IP地址变化。
- 有序的Pod终止:与部署不同,StatefulSet可以确保Pod按照指定的顺序终止。这对于有状态应用程序的升级和维护非常重要,因为它们可能需要在终止之前执行一些清理操作。

2、StatefulSet与Deployment、DaemonSet的对比
StatefulSet、Deployment和DaemonSet是Kubernetes中常用的控制器,用于管理不同类型的应用。它们之间有以下几点区别:
StatefulSet:
- 用于管理有状态应用程序,如数据库。
- 每个Pod都有一个唯一的稳定标识符,可以持久化地保留在Pod的整个生命周期中。
- 可以按照指定的顺序部署、扩展和终止Pod,以确保有状态应用程序的稳定性。
- 可以为每个Pod提供独立的持久化存储。
Deployment:
- 用于管理无状态应用程序,如Web服务。
- 负责确保指定数量的Pod副本运行在集群中,无需关注Pod的顺序或标识符。
- 可以进行滚动更新,快速部署新版本的应用程序,并确保不中断服务。
- 适用于需要水平扩展的应用程序,例如负载均衡的Web服务。
DaemonSet:
- 用于在集群中的每个节点上运行一个副本的Pod,通常用于运行后台任务或监控代理。
- 与Deployment不同,DaemonSet确保每个节点都有一个Pod副本运行,而不管节点的数量如何变化。
- 可以用于部署一些与节点相关的服务,例如日志收集器或网络代理。

三、StatefulSet核心组件
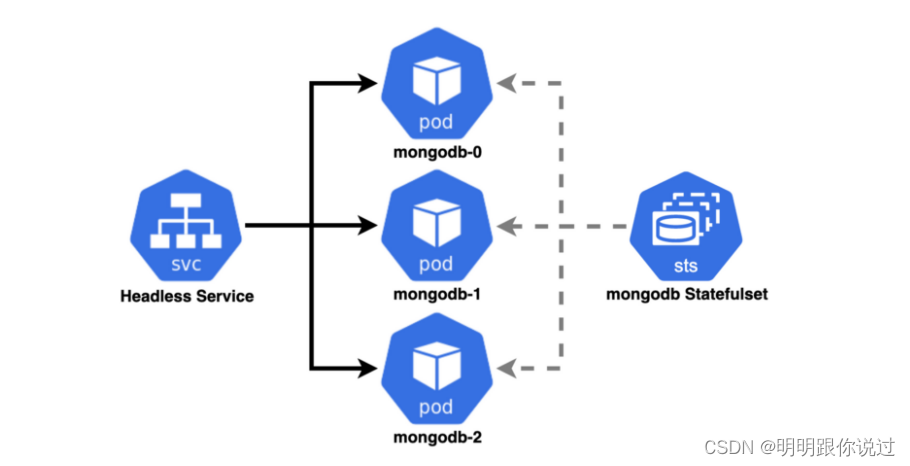
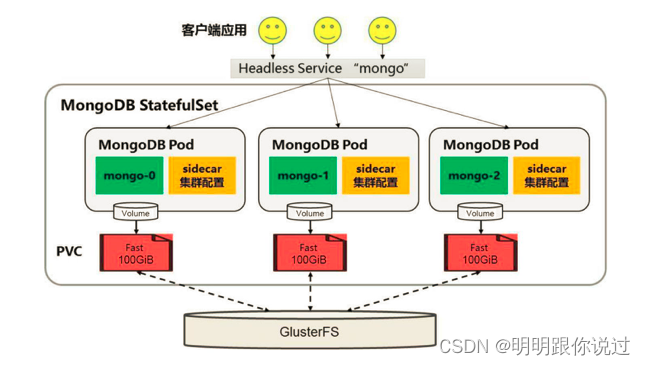
1、Headless Service
StatefulSet与Headless Service通常结合使用,以管理有状态应用程序的网络通信。这两者的关系如下:
StatefulSet:
- 用于管理有状态的应用程序,如数据库或其他需要持久标识符的服务。
- 每个Pod都有一个唯一的、稳定的标识符,可以通过索引或名称访问。
- 通常需要与Headless Service结合使用,以便为每个Pod提供唯一的DNS记录,以支持服务发现和网络通信。
Headless Service:
- 是一种特殊类型的Kubernetes Service,它没有ClusterIP。
- 通过为每个Pod提供一个DNS记录,允许直接通过Pod的IP地址进行网络通信。
- 通常与StatefulSet一起使用,为StatefulSet中的每个Pod提供唯一的DNS记录,以便其他应用程序可以通过这些DNS记录直接访问每个Pod。
在StatefulSet中,每个Pod都有一个唯一的DNS记录,该DNS记录遵循以下格式:
$(podname).$(service name).$(namespace).svc.cluster.local
通过这种方式,其他应用程序可以直接使用该DNS记录来访问StatefulSet中的每个Pod,从而实现服务发现和网络通信。
2、VolumeClaimTemplates
VolumeClaimTemplates是StatefulSet中的一个重要组件,用于定义与每个Pod相关联的PersistentVolumeClaim(PVC)的模板。在StatefulSet中,每个Pod都会有一个关联的PVC,用于请求持久化存储资源,以便数据在Pod之间的迁移和持久化。
VolumeClaimTemplates的主要作用包括:
-
定义模板:VolumeClaimTemplates允许定义PVC的模板,其中包括存储类、访问模式、存储资源请求等信息。这些模板将被用于为StatefulSet中的每个Pod创建对应的PVC。
-
自动生成PVC:根据定义的模板,Kubernetes会自动为StatefulSet中的每个Pod创建对应的PVC。这样可以确保每个Pod都有自己的持久化存储资源。
-
与StatefulSet关联:VolumeClaimTemplates与StatefulSet关联,使得它们能够一起协同工作。当创建或更新StatefulSet时,Kubernetes会根据VolumeClaimTemplates的定义自动创建或更新PVC。
-
简化配置:通过使用VolumeClaimTemplates,可以简化配置,避免手动为每个Pod创建PVC的繁琐工作。只需定义一个模板,Kubernetes就会为每个Pod生成相应的PVC,提高了部署和管理的效率。

四、StatefulSet的工作原理
1、Pod名称与网络标识的确定性
StatefulSet在创建Pod时,会为每个Pod分配一个唯一的名称,并使用该名称来确定Pod的网络标识。这种确定性是通过StatefulSet控制器的设计来实现的,
其工作原理如下:
Pod名称的确定性:
- StatefulSet控制器根据定义的Pod模板和副本数量,生成一系列Pod的名称。通常,Pod的名称会包含StatefulSet的名称以及一个唯一的索引号,例如<statefulset-name>-<ordinal>。
- 这些Pod名称的确定性保证了每个Pod都有一个唯一的标识符,便于管理和识别。
网络标识的确定性:
- StatefulSet控制器会为每个Pod分配一个稳定的DNS名称,通常是基于Pod名称的域名。例如,如果StatefulSet的名称是myapp,则第一个Pod的DNS名称可能是myapp-0.myapp.default.svc.cluster.local。
- 这种确定性的DNS名称确保了每个Pod都有一个稳定的网络标识符,其他应用可以通过DNS来发现和访问这些Pod。
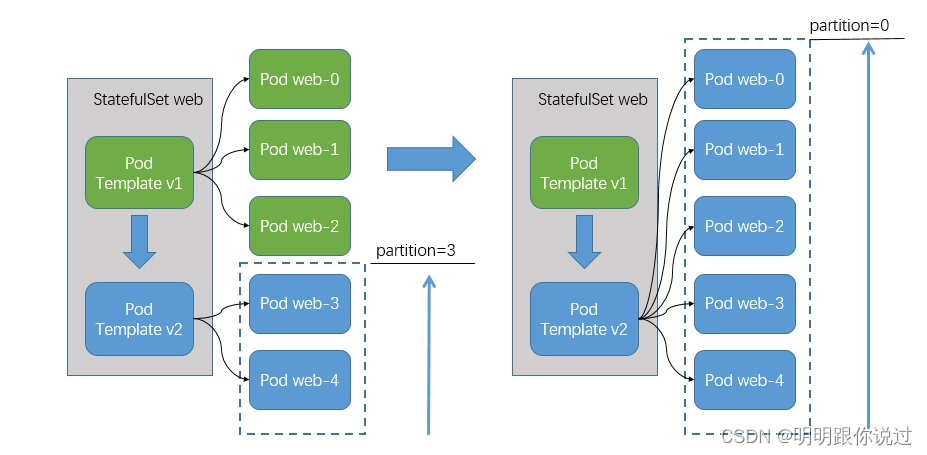
启动和更新顺序:
- StatefulSet控制器按照定义的副本数量和启动顺序逐个创建和更新Pod。通常情况下,后续Pod的启动和更新会等待前一个Pod完全启动和准备就绪后再开始。
- 这种有序的启动和更新顺序保证了应用的可靠性和稳定性,确保了应用的初始化和数据同步等过程能够顺利进行。
2、存储卷的动态分配与绑定
StatefulSet的工作原理中,存储卷的动态分配与绑定是通过volumeClaimTemplates字段实现的。这个字段允许定义一个或多个VolumeClaimTemplates,它们描述了每个Pod所需的存储卷大小和访问模式。在创建StatefulSet时,Kubernetes将根据这些模板动态地创建PersistentVolumeClaim(PVC),然后将其与对应的PersistentVolume(PV)绑定。
工作原理大致如下:
定义VolumeClaimTemplates:
- 在StatefulSet的配置中,通过volumeClaimTemplates字段定义每个Pod所需的存储卷模板。这些模板包含了存储卷的名称、大小、访问模式等信息。
动态创建PVC:
- 当创建StatefulSet时,Kubernetes会根据定义的VolumeClaimTemplates动态地创建对应数量的PVC。每个PVC都会根据模板中的定义,分配一个唯一的名称,并指定所需的存储卷大小和访问模式。
PV的动态绑定:
- 一旦PVC被创建,Kubernetes会自动查找满足其需求的可用PV。如果存在符合条件的PV,则将PVC与PV进行绑定。如果没有可用的PV,Kubernetes将根据定义的StorageClass动态创建新的PV,并将其与PVC进行绑定。
PVC的挂载:
- 绑定完成后,StatefulSet会将每个Pod的PVC挂载到对应的容器中。容器可以通过挂载的PVC来访问和使用持久化存储。
通过这种方式,StatefulSet能够自动管理存储卷的动态分配和绑定过程,确保每个Pod都拥有自己独立的持久化存储,并且能够持久化地保存应用程序的数据。这种动态的存储卷管理机制使得StatefulSet适用于需要持久化存储的有状态应用,如数据库、消息队列等。
3、故障恢复与重建机制
- 稳定的网络标识和稳定的持久化存储:StatefulSet保证每个Pod都有唯一的网络标识和持久化存储。即使Pod重新启动或迁移到其他节点,它们也会保持相同的网络标识和持久化存储,从而确保应用程序状态的持久性。
- 有序的Pod部署和终止:StatefulSet会按照定义的顺序逐个部署和终止Pod。这确保了在更新或扩容时,每个Pod都能以有序的方式启动和停止,从而避免了并发启动或停止可能导致的问题。
- 滚动更新策略:StatefulSet支持滚动更新策略,可以逐个替换旧的Pod实例。在进行滚动更新时,它会等待新Pod就绪后再继续更新下一个Pod,从而确保更新过程的稳健性和可控性。
- 自动重启和重建:如果某个Pod失败或被终止,StatefulSet会自动重启该Pod或在另一个节点上重建一个新的Pod,以保持所需的副本数量。
- 管理PVC的生命周期:StatefulSet还负责管理与之关联的PersistentVolumeClaim(PVC)的生命周期。当StatefulSet被删除时,它会根据定义的回收策略来处理PVC,可以选择保留或删除与之关联的持久化存储。
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些关于Kubernetes的文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
这篇关于k8s 控制器StatefulSet原理解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


