本文主要是介绍如何使用pgvector为RDS PostgreSQL构建专属ChatBot?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
越来越多的企业和个人希望能够利用LLM和生成式人工智能来构建专注于其特定领域的具备AI能力的产品。目前,大语言模型在处理通用问题方面表现较好,但由于训练语料和大模型的生成限制,对于专业知识和时效性方面存在一些局限。在信息时代,企业的知识库更新频率越来越高,而企业所拥有的垂直领域知识库(如文档、图像、音视频等)可能是未公开或不可公开的。因此,对于企业而言,如果想在大语言模型的基础上构建属于特定垂直领域的AI产品,就需要不断将自身的知识库输入到大语言模型中进行训练。
目前有两种常见的方法实现:
- 微调(Fine-tuning):通过提供新的数据集对已有模型的权重进行微调,不断更新输入以调整输出,以达到所需的结果。这适用于数据集规模不大或针对特定类型任务或风格进行训练,但训练成本和价格较高。
- 提示调整(Prompt-tuning):通过调整输入提示而非修改模型权重,从而实现调整输出的目的。相较于微调,提示调整具有较低的计算成本,需要的资源和训练时间也较少,同时更加灵活。
基于RDS PostgreSQL构建ChatBot的优势如下:
- 借助RDS PostgreSQL的pgvector插件,可以将实时内容或垂直领域的专业知识和内容转化为向量化的embedding表示,并存储在RDS PostgreSQL中,以实现高效的向量化检索,从而提高私域内容的问答准确性。
- 作为先进的开源OLTP引擎,RDS PostgreSQL能够同时完成在线用户数据交互和数据存储的任务,例如,它可以用于处理对话的交互记录、历史记录、对话时间等功能。RDS PostgreSQL一专多长的特性使得私域业务的构建更加简单,架构也更加轻便。
- pgvector插件目前已经在开发者社区以及基于PostgreSQL的开源数据库中得到广泛应用,同时ChatGPT Retrieval Plugin等工具也及时适配了PostgreSQL。这表明RDS PostgreSQL在向量化检索领域具有良好的生态支持和广泛的应用基础,为用户提供了丰富的工具和资源。
本文将以RDS PostgreSQL提供的开源向量索引插件(pgvector)和OpenAI提供的embedding能力为例,展示如何构建专属的ChatBot。
快速体验
阿里云提供云速搭CADT平台模板,该方案模板已预部署了ECS以及RDS PostgreSQL数据库,并且预安装了前置安装包,能够帮助您快速体验专属ChatBot,您可以前往云速搭CADT控制台,参考大模型结合RDS PostgreSQL数据库构建企业级专属Chatbot进行体验。
前提条件
- 已创建RDS PostgreSQL实例且满足以下条件:
-
- 实例大版本为PostgreSQL 14或以上。
- 实例内核小版本为20230430或以上。
- 说明
如需升级实例大版本或内核小版本,请参见升级数据库大版本或升级内核小版本。 - 本文展示的专属的ChatBot基于RDS PostgreSQL提供的开源插件pgvector,请确保已完全了解其相关用法及基本概念,更多信息,请参见高维向量相似度搜索(pgvector)。
- 本文展示的专属的ChatBot使用了OpenAI的相关能力,请确保您具备
Secret API Key,并且您的网络环境可以使用OpenAI,本文展示的代码示例均部署在新加坡地域的ECS中。 - 本文示例代码使用的Python语言,请确保已具备Python开发环境,本示例使用的Python版本为
3.11.4,使用的开发工具为PyCharm 2023.1.2。
相关概念
嵌入
嵌入(embedding)是指将高维数据映射为低维表示的过程。在机器学习和自然语言处理中,嵌入通常用于将离散的符号或对象表示为连续的向量空间中的点。
在自然语言处理中,词嵌入(word embedding)是一种常见的技术,它将单词映射到实数向量,以便计算机可以更好地理解和处理文本。通过词嵌入,单词之间的语义和语法关系可以在向量空间中得到反映。
OpenAI提供Embeddings能力。
实现原理
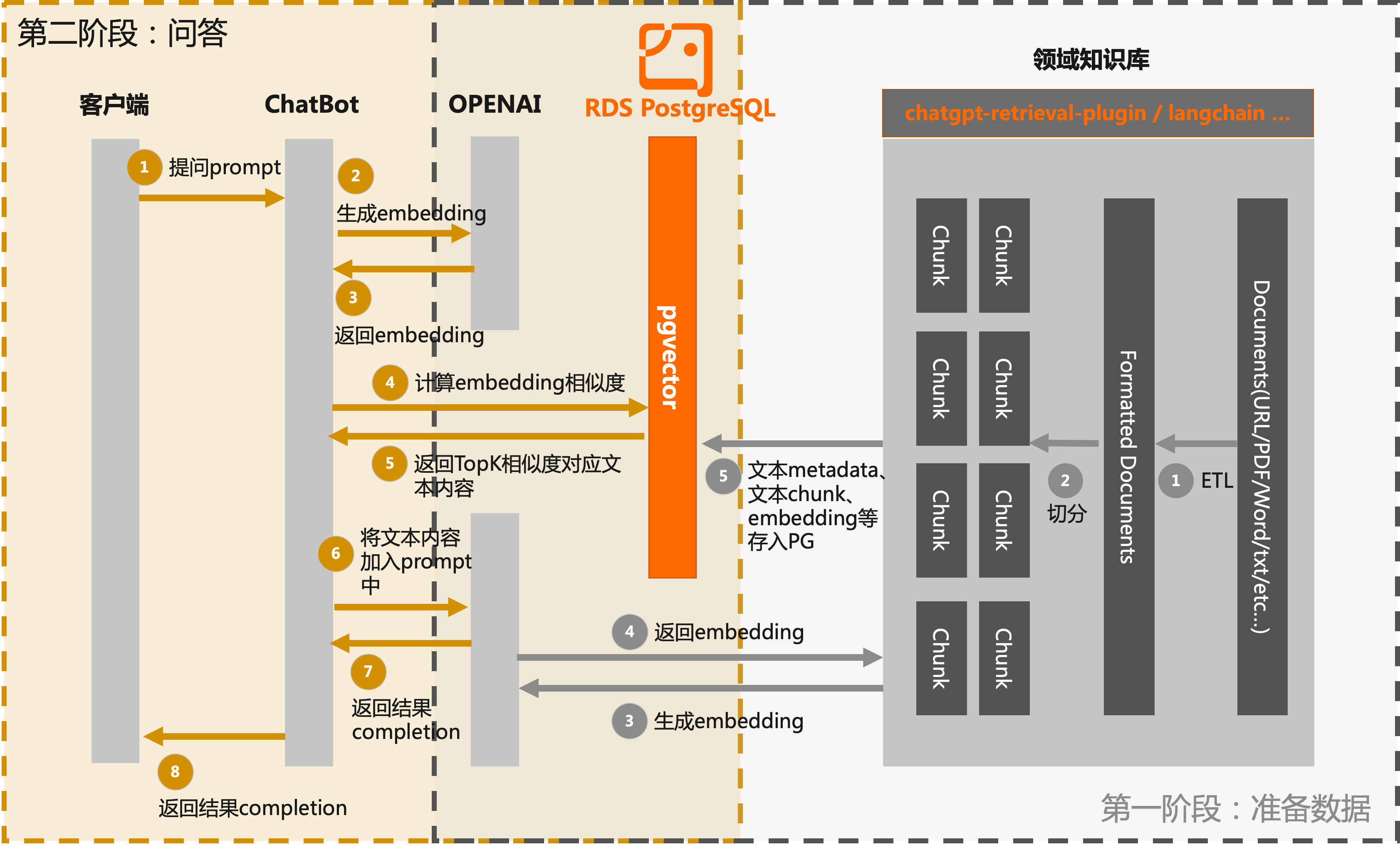
本文展示的专属ChatBot的实现流程分为两个阶段:
第一阶段:数据准备
- 知识库信息提取和分块:从领域知识库中提取相关的文本信息,并将其分块处理。这可以包括将长文本拆分为段落或句子,提取关键词或实体等。这样可以将知识库的内容更好地组织和管理。
- 调用LLM接口生成embedding:利用LLM(如OpenAI)提供的接口,将分块的文本信息输入到模型中,并生成相应的文本embedding。这些embedding将捕捉文本的语义和语境信息,为后续的搜索和匹配提供基础。
- 存储embedding信息:将生成的文本embedding信息、文本分块以及文本关联的metadata信息存入RDS PostgreSQL数据库中。
第二阶段:问答
- 用户提问。
- 通过OpenAI提供的embedding接口创建该问题的embedding。
- 通过pgvector过滤出RDS PostgreSQL数据库中相似度大于一定阈值的文档块,将结果返回。
流程图如下:
操作步骤
第一阶段:数据准备
本文以创建RDS PostgreSQL实例文档的文本内容为例,将其拆分并存储到RDS PostgreSQL数据库中,您需要准备自己的专属领域知识库。
数据准备阶段的关键在于将专属领域知识转化为文本embedding,并有效地存储和匹配这些信息。通过利用LLM的强大语义理解能力,您可以获得与特定领域相关的高质量回答和建议。当前的一些开源框架,可以方便您上传和解析知识库文件,包括URL、Markdown、PDF、Word等格式。例如LangChain和OpenAI开源的ChatGPT Retrieval Plugin。LangChain和ChatGPT Retrieval Plugin均已经支持了基于pgvector扩展的PostgreSQL作为其后端向量数据库,这使得与RDS PostgreSQL实例的集成变得更加便捷。通过这样的集成,您可以方便地完成第一阶段领域知识库的数据准备,并充分利用pgvector提供的向量索引和相似度搜索功能,实现高效的文本匹配和查询操作。
- 连接PostgreSQL实例。
- 创建测试数据库,以
rds_pgvector_test为例。
CREATE DATABASE testdb;- 进入测试数据库,并创建pgvector插件。
CREATE EXTENSION IF NOT EXISTS vector;- 创建测试表(本文以
rds_pg_help_docs为例),用于存储知识库内容。
CREATE TABLE rds_pg_help_docs (id bigserial PRIMARY KEY, title text, -- 文档标题description text, -- 描述doc_chunk text, -- 文档分块token_size int, -- 文档分块字数embedding vector(1536)); -- 文本嵌入信息- 为embedding列创建索引,用于查询优化和加速。
CREATE INDEX ON rds_pg_help_docs USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);- 说明
向量列创建索引的更多说明,请参见高维向量相似度搜索(pgvector)。 - 在PyCharm中,创建项目,然后打开Terminal,输入如下语句,安装如下依赖库。
pip install openai psycopg2 tiktoken requests beautifulsoup4 numpy- 创建
.py文件(本文以knowledge_chunk_storage.py为例),拆分知识库文档内容并存储到数据库中,示例代码如下:
说明
如下示例代码中,自定义的拆分方法仅仅是将知识库文档内容按固定字数进行了拆分,您可以使用LangChain和OpenAI开源的ChatGPT Retrieval Plugin等开源框架中提供的方法进行拆分。知识库中的文档质量和分块结果对最终的输出的结果有较大的影响。
import openai
import psycopg2
import tiktoken
import requests
from bs4 import BeautifulSoup
EMBEDDING_MODEL = "text-embedding-ada-002"
tokenizer = tiktoken.get_encoding("cl100k_base")
# 连接RDS PostgreSQL数据库
conn = psycopg2.connect(database="<数据库名>",host="<RDS实例连接地址>",user="<用户名>",password="<密码>",port="<数据库端口>")
conn.autocommit = True
# OpenAI的API Key
openai.api_key = '<Secret API Key>'
# 自定义拆分方法(仅为示例)
def get_text_chunks(text, max_chunk_size):chunks_ = []soup_ = BeautifulSoup(text, 'html.parser')content = ''.join(soup_.strings).strip()length = len(content)start = 0while start < length:end = start + max_chunk_sizeif end >= length:end = lengthchunk_ = content[start:end]chunks_.append(chunk_)start = endreturn chunks_
# 指定需要拆分的网页
url = 'https://help.aliyun.com/document_detail/148038.html'
response = requests.get(url)
if response.status_code == 200:# 获取网页内容web_html_data = response.textsoup = BeautifulSoup(web_html_data, 'html.parser')# 获取标题(H1标签)title = soup.find('h1').text.strip()# 获取描述(class为shortdesc的p标签内容)description = soup.find('p', class_='shortdesc').text.strip()# 拆分并存储chunks = get_text_chunks(web_html_data, 500)for chunk in chunks:doc_item = {'title': title,'description': description,'doc_chunk': chunk,'token_size': len(tokenizer.encode(chunk))}query_embedding_response = openai.Embedding.create(model=EMBEDDING_MODEL,input=chunk,)doc_item['embedding'] = query_embedding_response['data'][0]['embedding']cur = conn.cursor()insert_query = '''INSERT INTO rds_pg_help_docs (title, description, doc_chunk, token_size, embedding) VALUES (%s, %s, %s, %s, %s);'''cur.execute(insert_query, (doc_item['title'], doc_item['description'], doc_item['doc_chunk'], doc_item['token_size'],doc_item['embedding']))conn.commit()
else:print('Failed to fetch web page')- 运行python程序。
- 登录数据库使用如下命令查看是否已将知识库文档内容拆分并存储为向量数据。
SELECT * FROM rds_pg_help_docs;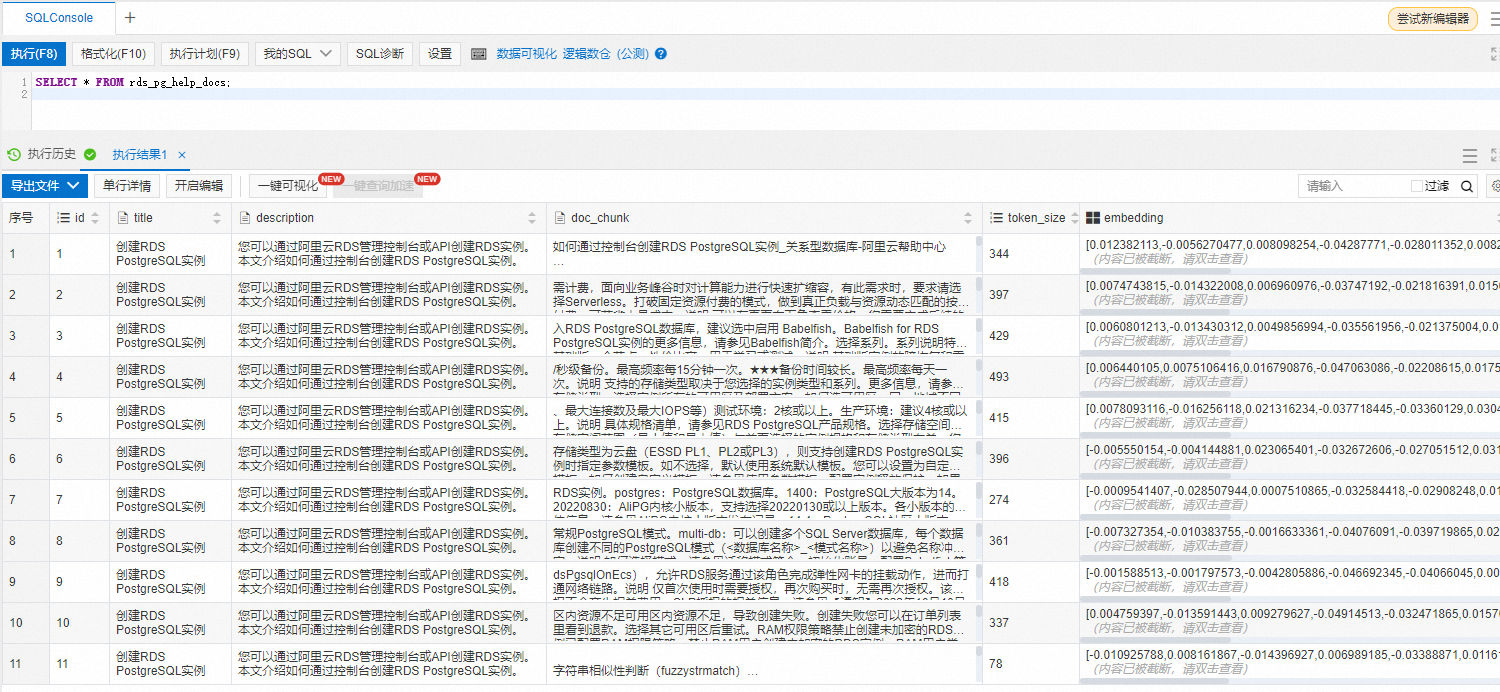
第二阶段:问答
- 在python项目中,创建
.py文件(本文以chatbot.py为例),创建问题并与数据库中的知识库内容比较相似度,返回结果。
import openai
import psycopg2
from psycopg2.extras import DictCursor
GPT_MODEL = "gpt-3.5-turbo"
EMBEDDING_MODEL = "text-embedding-ada-002"
GPT_COMPLETIONS_MODEL = "text-davinci-003"
MAX_TOKENS = 1024
# OpenAI的API Key
openai.api_key = '<Secret API Key>'
prompt = '如何创建一个RDS PostgreSQL实例'
prompt_response = openai.Embedding.create(model=EMBEDDING_MODEL,input=prompt,
)
prompt_embedding = prompt_response['data'][0]['embedding']
# 连接RDS PostgreSQL数据库
conn = psycopg2.connect(database="<数据库名>",host="<RDS实例连接地址>",user="<用户名>",password="<密码>",port="<数据库端口>")
conn.autocommit = True
def answer(prompt_doc, prompt):improved_prompt = f"""按下面提供的文档和步骤来回答接下来的问题:(1) 首先,分析文档中的内容,看是否与问题相关(2) 其次,只能用文档中的内容进行回复,越详细越好,并且以markdown格式输出(3) 最后,如果问题与RDS PostgreSQL不相关,请回复"我对RDS PostgreSQL以外的知识不是很了解"文档:\"\"\"{prompt_doc}\"\"\"问题: {prompt}"""response = openai.Completion.create(model=GPT_COMPLETIONS_MODEL,prompt=improved_prompt,temperature=0.2,max_tokens=MAX_TOKENS)print(f"{response['choices'][0]['text']}\n")
similarity_threshold = 0.78
max_matched_doc_counts = 8
# 通过pgvector过滤出相似度大于一定阈值的文档块
similarity_search_sql = f'''
SELECT doc_chunk, token_size, 1 - (embedding <=> '{prompt_embedding}') AS similarity
FROM rds_pg_help_docs WHERE 1 - (embedding <=> '{prompt_embedding}') > {similarity_threshold} ORDER BY id LIMIT {max_matched_doc_counts};
'''
cur = conn.cursor(cursor_factory=DictCursor)
cur.execute(similarity_search_sql)
matched_docs = cur.fetchall()
total_tokens = 0
prompt_doc = ''
print('Answer: \n')
for matched_doc in matched_docs:if total_tokens + matched_doc['token_size'] <= 1000:prompt_doc += f"\n---\n{matched_doc['doc_chunk']}"total_tokens += matched_doc['token_size']continueanswer(prompt_doc,prompt)total_tokens = 0prompt_doc = ''
answer(prompt_doc,prompt)- 运行Python程序后,您可以在运行窗口看到类似如下的对应答案:
说明
您可以对拆分方法以及问题prompt进行优化,以获得更加准确、完善的回答,本文仅为示例。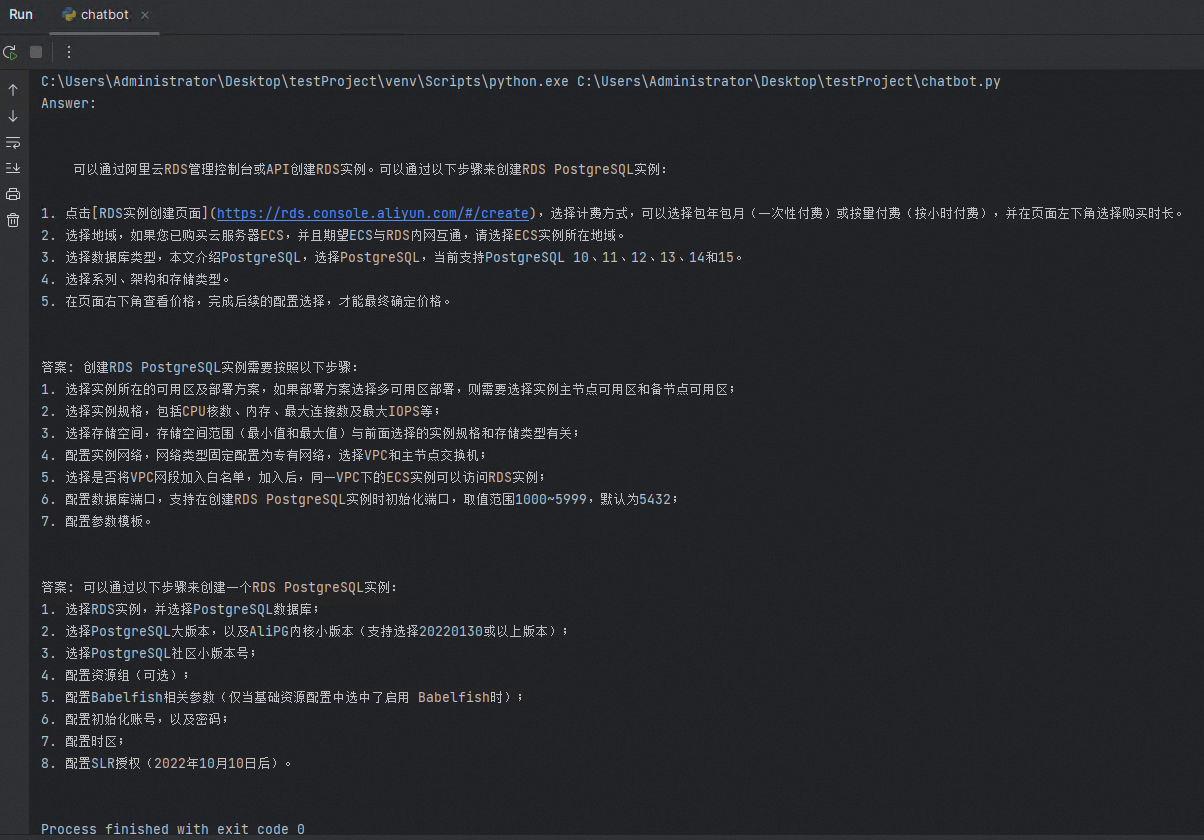
总结
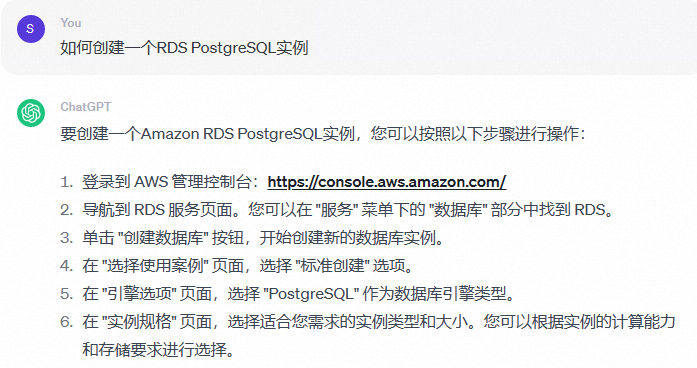
如果未接入专属知识库,OpenAI对于问题“如何创建一个RDS PostgreSQL实例”的回答往往与阿里云不相关,例如:
在接入存储在RDS PostgreSQL数据库中的专属知识库后,对于问题“如何创建一个RDS PostgreSQL实例”,我们将会得到只属于阿里云RDS PostgreSQL数据库的相关回答。
根据上述实践内容,可以看出RDS PostgreSQL完全具备构建基于LLM的垂直领域知识库的能力。
这篇关于如何使用pgvector为RDS PostgreSQL构建专属ChatBot?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






