本文主要是介绍谢宝友:深入理解 Linux RCU 从硬件说起之内存屏障,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文简介:本文从硬件的角度引申出内存屏障,这不是内存屏障的详尽手册,但是相关知识对于理解RCU有所帮助。这不是一篇单独的文章,这是《谢宝友:深入理解Linux RCU》系列的第2篇,前序文章:《谢宝友:深入理解 Linux RCU 从硬件说起之内存屏障》
作者简介:谢宝友,在编程一线工作已经有20年时间,其中接近10年时间工作于Linux操作系统。在中兴通讯操作系统产品部工作期间,他作为技术总工参与的电信级嵌入式实时操作系统,获得了行业最高奖----中国工业大奖。 同时,他也是《深入理解并行编程》一书的译者。该书作者Paul E.McKeney是IBM Linux中心领导者,Linux RCU Maintainer。《深入理解RCU》系列文章整理了Paul E.McKeney的相关著作,希望能帮助读者更深刻的理解Linux内核中非常难于理解的模块----RCU。
联系方式:mail:scxby@163.com 微信:linux-kernel
一、内存Cache还有哪些不足?
上一篇文章我们谈到了内存Cache,并且描述了典型的Cache一致性协议MESI。Cache的根本目的,是解决内存与CPU速度多达两个数量级的性能差异。一个包含Cache的计算机系统,其结构可以简单的表示为下图:
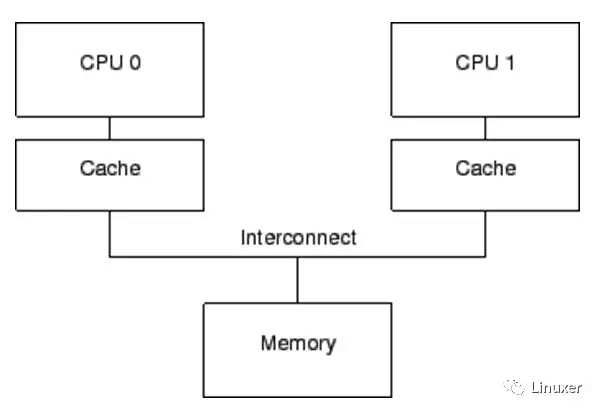
仅仅只有Cache的计算机系统,它还存在如下问题: 1、Cache的速度,虽然比内存有了极大的提升,但是仍然比CPU慢几倍。 2、在发生“warmup cache miss”、“capacity miss”、“associativity miss”时,CPU必须等待从内存中读取数据,此时CPU会处于一种Stall的状态。其等待时间可能达到几百个CPU指令周期。
显然,这是现代计算机不能承受之重:)
二、Write buffer是为了解决什么问题?
如果CPU仅仅是执行foo = 1这样的语句,它其实无须从内存或者缓存中读取foo现在的值。因为无论foo当前的值是什么,它都会被覆盖。在仅仅只有Cache的系统中,foo = 1 这样的操作也会形成写停顿。自然而然的,CPU设计者应当会想到在Cache 和CPU之间再添加一级缓存。由于这样的缓存主要是应对写操作引起的Cache Miss,并且缓存的数据与写操作相关,因此CPU设计者将它命名为“Write buffer”。调整后的结构示意图如下(图中的store buffer即为write buffer):
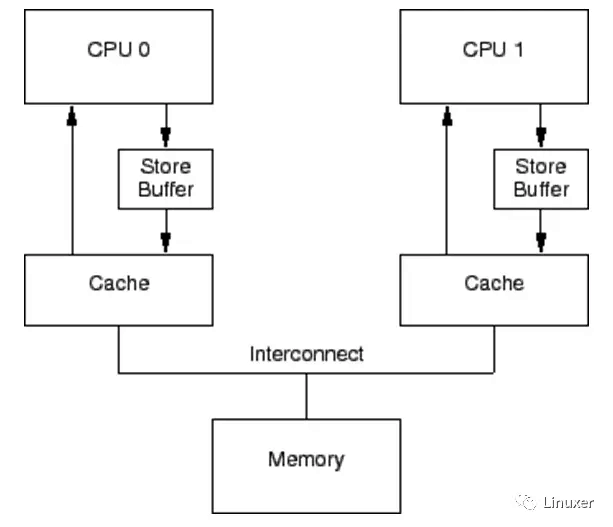
通过增加这些Write buffer,CPU可以简单的将要保存的数据放到Write buffer 中,并且继续运行,而不会真正去等待Cache从内存中读取数据并返回。
对于特定CPU来说,这些Write buffer是属于本地的。或者在硬件多线程系统中,它对于特定核来说,是属于本地的。无论哪一种情况,一个特定CPU仅仅允许访问分配给它的Writebuffer。例如,在上图中,CPU 0不能访问CPU 1的存储缓冲,反之亦然。
Write buffer进一步提升了系统性能,但是它也会为硬件设计者带来一些困扰: 第一个困扰:违反了自身一致性。
考虑如下代码:变量“a”和“b”都初始化为0,包含变量“a”缓存行,最初被CPU 1所拥有,而包含变量“b”的缓存行最初被CPU0所拥有:
1 a = 1;2 b = a + 1;3 assert(b == 2);
没有哪一位软件工程师希望断言被触发!
然而,如果采用上图中的简单系统结构,断言确实会被触发。理解这一点的关键在于:a最初被CPU 1所拥有,而CPU 0在执行a = 1时,将a的新值存储在CPU 0的Write buffer中。 在这个简单系统中,触发断言的事件顺序可能如下: 1.CPU 0 开始执行a = 1。 2.CPU 0在缓存中查找“a”,并且发现缓存缺失。 3.因此,CPU 0发送一个“读使无效(read-invalidate message)”消息,以获得包含“a”的独享缓存行。 4.CPU 0将“a”记录到存储缓冲区。 5.CPU 1接收到“读使无效”消息,它通过发送缓存行数据,并从它的缓存行中移除数据来响应这个消息。 6.CPU 0开始执行b = a + 1。 7.CPU 0从CPU 1接收到缓存行,它仍然拥有一个为“0”的“a”值。 8.CPU 0从它的缓存中读取到“a”的值,发现其值为0。 9.CPU 0将存储队列中的条目应用到最近到达的缓存行,设置缓存行中的“a”的值为1。 10.CPU 0将前面加载的“a”值0加1,并存储该值到包含“b”的缓存行中(假设已经被CPU 0所拥有)。 11.CPU 0 执行assert(b == 2),并引起错误。 针对这种情况,硬件设计者对软件工程师还是给予了必要的同情。他们会对系统进行稍许的改进,如下图:
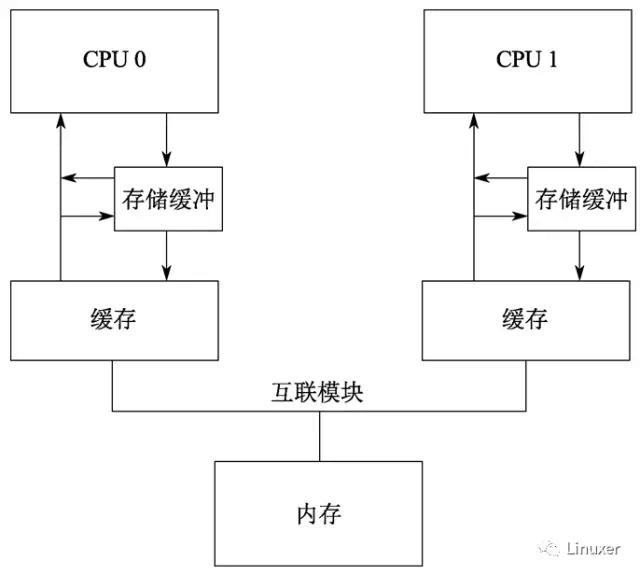
在调整后的架构中,每个CPU在执行加载操作时,将考虑(或者嗅探)它的Writebuffer。这样,在前面执行顺序的第8步,将在存储缓冲区中为“a”找到正确的值1 ,因此最终的“b”值将是2,这正是我们期望的。 Write buffer带来的第二个困扰,是违反了全局内存序。考虑如下的代码顺序,其中变量“a”、“b”的初始值是0。
1 void foo(void)2 {3 a = 1;4 b = 1;5 }67 void bar(void)8 {9 while (b == 0) continue;10 assert(a == 1);11 }
假设CPU 0执行foo(),CPU1执行bar(),再进一步假设包含“a”的缓存行仅仅位于CPU1的缓存中,包含“b”的缓存行被CPU 0所拥有。那么操作顺序可能如下: 1.CPU 0 执行a = 1。缓存行不在CPU0的缓存中,因此CPU0将“a”的新值放到Write buffer,并发送一个“读使无效”消息。 2.CPU 1 执行while (b == 0) continue,但是包含“b”的缓存行不在它的缓存中,因此它发送一个“读”消息。 3.CPU 0 执行 b = 1,它已经拥有了该缓存行(换句话说,缓存行要么已经处于“modified”,要么处于“exclusive”状态),因此它存储新的“b”值到它的缓存行中。 4.CPU 0 接收到“读”消息,并且发送缓存行中的最近更新的“b”的值到CPU1,同时将缓存行设置为“shared”状态。 5.CPU 1 接收到包含“b”值的缓存行,并将其值写到它的缓存行中。 6.CPU 1 现在结束执行while (b ==0) continue,因为它发现“b”的值是1,它开始处理下一条语句。 7.CPU 1 执行assert(a == 1),并且,由于CPU 1工作在旧的“a”的值,因此断言验证失败。 8.CPU 1 接收到“读使无效”消息,并且发送包含“a”的缓存行到CPU 0,同时在它的缓存中,将该缓存行变成无效。但是已经太迟了。 9.CPU 0 接收到包含“a”的缓存行,并且及时将存储缓冲区的数据保存到缓存行中,CPU1的断言失败受害于该缓存行。 请注意,“内存屏障”已经在这里隐隐约约露出了它锋利的爪子!!!!
三、使无效队列又是为了解决什么问题?
一波未平,另一波再起。
问题的复杂性还不仅仅在于Writebuffer,因为仅仅有Write buffer,硬件还会形成严重的性能瓶颈。
问题在于,每一个核的Writebuffer相对而言都比较小,这意味着执行一段较小的存储操作序列的CPU,很快就会填满它的Writebuffer。此时,CPU在能够继续执行前,必须等待Cache刷新操作完成,以清空它的Write buffer。
清空Cache是一个耗时的操作,因为必须要在所在CPU之间广播MESI消息(使无效消息),并等待对这些MESI消息的响应。为了加快MESI消息响应速度,CPU设计者增加了使无效队列。也就是说,CPU将接收到的使无效消息暂存起来,在发送使无效消息应答时,并不真正将Cache中的值无效。而是等待在合适的时候,延迟使无效操作。
下图是增加了使无效队列的系统结构:
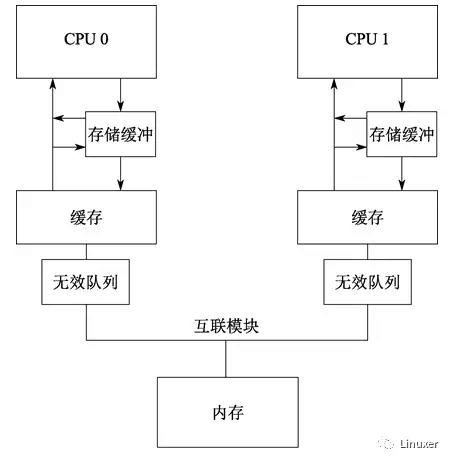
将一个条目放进使无效队列,实际上是由CPU承诺:在发送任何与该缓存行相关的MESI协议消息前,处理该条目。在Cache竞争不太剧烈的情况下,CPU会很出色地完成此事。
使无效队列带来的问题是:在没有真正将Cache无效之前,就告诉其他CPU已经使无效了。这多少有一点欺骗的意思。然而现代CPU确实是这样设计的。
这个事实带来了额外的内存乱序的机会,看看如下示例: 假设“a”和“b”被初始化为0,“a”是只读的(MESI“shared”状态),“b”被CPU 0拥有(MESI“exclusive”或者“modified”状态)。然后假设CPU 0执行foo()而CPU1执行bar(),代码片段如下:
1 void foo(void)2 {3 a = 1;4 smp_mb();5 b = 1;6 }78 void bar(void)9 {10 while (b == 0) continue;11 assert(a == 1);12 }
操作顺序可能如下: 1.CPU 0执行a = 1。在CPU0中,相应的缓存行是只读的,因此CPU 0将“a”的新值放入存储缓冲区,并发送一个“使无效”消息,这是为了使CPU1的缓存中相应的缓存行失效。 2.CPU 1执行while (b == 0)continue,但是包含“b”的缓存行不在它的缓存中,因此它发送一个“读”消息。 3.CPU 1接收到CPU 0的“使无效”消息,将它排队,并立即响应该消息。 4.CPU 0接收到来自于CPU 1的响应消息,因此它放心的通过第4行的smp_mb(),从存储缓冲区移动“a”的值到缓存行。 5.CPU 0执行b = 1。它已经拥有这个缓存行(也就是说,缓存行已经处于“modified”或者“exclusive”状态),因此它将“b”的新值存储到缓存行中。 6.CPU 0接收到“读”消息,并且发送包含“b”的新值的缓存行到CPU 1,同时在自己的缓存中,标记缓存行为“shared”状态。 7.CPU 1接收到包含“b”的缓存行并且将其应用到本地缓存。 8.CPU 1现在可以完成while (b ==0) continue,因为它发现“b”的值为1,接着处理下一条语句。 9.CPU 1执行assert(a == 1),并且,由于旧的“a”值还在CPU 1的缓存中,因此陷入错误。 10.虽然陷入错误,CPU 1处理已经排队的“使无效”消息,并且(迟到)在自己的缓存中刷新包含“a”值的缓存行。
四、内存屏障
既然硬件设计者通过Write buffer和使无效队列引入了额外的内存乱序问题,那么就应当为软件工程师提供某种方法来解决这个问题。即使相应的解决方法会折磨软件工程师。
答案就是内存屏障。对于Linux内核资深工程师来说,这个答案也显得比较沉重,它太折磨人了:)
我们先看看Write buffer一节中,触发断言的例子,应该怎么修改。 在那个例子中,硬件设计者不能直接帮助我们,因为 CPU没有办法识别那些相关联的变量(例子中的a和b),更不用说它们如何关联。因此,硬件设计者提供内存屏障指令,以允许软件告诉CPU这些关系的存在。程序必须修改,以包含内存屏障:
1 void foo(void)2 {3 a = 1;4 smp_mb();5 b = 1;6 }78 void bar(void)9 {10 while (b == 0) continue;11 assert(a == 1);12 }
内存屏障smp_mb()将导致CPU在刷新后续的缓存行(包含b的缓存行)之前,前面的Write buffer被先刷新。在继续处理之前,CPU可能采取的动作是:
1、简单的停顿下来,直到存储缓冲区变成空; 2、也可能是使用存储缓冲区来持有后续的存储操作,直到前面所有的存储缓冲区已经被保存到缓存行中。 理解其中第2点,能够帮助我们理解“内存屏障”这个单词的来历!! 后一种情况下,操作序列可能如下所示: 1.CPU 0执行a= 1。缓存行不在CPU0的缓存中,因此CPU 0将“a”的新值放到存储缓冲中,并发送一个“读使无效”消息。 2.CPU 1 执行while(b == 0) continue,但是包含“b”的缓存行不在它的缓存中,因此它发送一个“读”消息。 3.CPU 0执行smp_mb(),并标记当前所有存储缓冲区的条目。(也就是说a = 1这个条目)。 4.CPU 0执行b= 1。它已经拥有这个缓存行了。(也就是说, 缓存行已经处于“modified”或者“exclusive”状态),但是在存储缓冲区中存在一个标记条目。因此,它不将“b”的新值存放到缓存行,而是存放到存储缓冲区中。(但是“b”不是一个标记条目)。 5.CPU 0接收“读”消息,随后发送包含原始“b”值的缓存行给CPU1。它也标记该缓存行的复制为“shared”状态。 6.CPU 1读取到包含“b”的缓存行,并将它复制到本地缓存中。 7.CPU 1现在可以装载“b”的值了,但是,由于它发现其值仍然为“0”,因此它重复执行while语句。“b”的新值被安全的隐藏在CPU0的存储缓冲区中。 8.CPU 1接收到“读使无效”消息,发送包含“a”的缓存行给CPU 0,并且使它的缓存行无效。 9.CPU 0接收到包含“a”的缓存行,使用存储缓冲区的值替换缓存行,将这一行设置为“modified”状态。 10.由于被存储的“a”是存储缓冲区中唯一被smp_mb()标记的条目,因此CPU0能够存储“b”的新值到缓存行中,除非包含“b”的缓存行当前处于“shared”状态。 11.CPU 0发送一个“使无效”消息给CPU 1。 12.CPU 1接收到“使无效”消息,使包含“b”的缓存行无效,并且发送一个“使无效应答”消息给 CPU 0。 13.CPU 1执行while(b == 0) continue,但是包含“b”的缓存行不在它的缓存中,因此它发送一个“读”消息给 CPU 0。 14.CPU 0接收到“使无效应答”消息,将包含“b”的缓存行设置成“exclusive”状态。CPU 0现在存储新的“b”值到缓存行。 15.CPU 0接收到“读”消息,同时发送包含新的“b”值的缓存行给 CPU 1。它也标记该缓存行的复制为“shared”状态。 16.CPU 1接收到包含“b”的缓存行,并将它复制到本地缓存中。 17.CPU 1现在能够装载“b”的值了,由于它发现“b”的值为1,它退出while循环并执行下一条语句。 18.CPU 1执行assert(a== 1),但是包含“a”的缓存行不在它的缓存中。一旦它从CPU0获得这个缓存行,它将使用最新的“a”的值,因此断言语句将通过。
正如你看到的那样,这个过程涉及不少工作。即使某些事情从直觉上看是简单的操作,就像“加载a的值”这样的操作,都会包含大量复杂的步骤。
前面提到的,其实是写端的屏障,它解决Write buffer引入的内存乱序。接下来我们看看读端的屏障,它解决使无效队列引入的内存乱序。
要避免使无效队列例子中的错误,应当再使用读端内存屏障: 读端内存屏障指令能够与使无效队列交互,这样,当一个特定的CPU执行一个内存屏障时,它标记无效队列中的所有条目,并强制所有后续的装载操作进行等待,直到所有标记的条目都保存到CPU的Cache中。因此,我们可以在bar函数中添加一个内存屏障,如下:
1 void foo(void)2 {3 a = 1;4 smp_mb();5 b = 1;6 }78 void bar(void)9 {10 while (b == 0) continue;11 smp_mb();12 assert(a == 1);13 }
有了这个变化后,操作顺序可能如下:
1.CPU 0执行a= 1。相应的缓存行在CPU0的缓存中是只读的,因此CPU0将“a”的新值放入它的存储缓冲区,并且发送一个“使无效”消息以刷新CPU1相应的缓存行。 2.CPU 1 执行while(b == 0) continue,但是包含“b”的缓存行不在它的缓存中,因此它发送一个“读”消息。 3.CPU 1 接收到 CPU 0的“使无效”消息,将它排队,并立即响应它。 4.CPU 0 接收到CPU1的响应,因此它放心的通过第4行的smp_mb()语句,将“a”从它的存储缓冲区移到缓存行。 5.CPU 0 执行b= 1。它已经拥有该缓存行(换句话说, 缓存行已经处于“modified”或者“exclusive”状态),因此它存储“b”的新值到缓存行。 6.CPU 0 接收到“读”消息,并且发送包含新的“b”值的缓存行给CPU1,同时在自己的缓存中,标记缓存行为“shared”状态。 7.CPU 1 接收到包含“b”的缓存行并更新到它的缓存中。 8.CPU 1 现在结束执行while (b == 0) continue,因为它发现“b”的值为 1,它处理下一条语句,这是一条内存屏障指令。 9.CPU 1 必须停顿,直到它处理完使无效队列中的所有消息。 10.CPU 1 处理已经入队的“使无效”消息,从它的缓存中使无效包含“a”的缓存行。 11.CPU 1 执行assert(a== 1),由于包含“a”的缓存行已经不在它的缓存中,它发送一个“读”消息。 12.CPU 0 以包含新的“a”值的缓存行响应该“读”消息。 13.CPU 1 接收到该缓存行,它包含新的“a”的值1,因此断言不会被触发。
即使有很多MESI消息传递,CPU最终都会正确的应答。这一节阐述了CPU设计者为什么必须格外小心地处理它们的缓存一致性优化操作。
但是,这里真的需要一个读端内存屏障么?在assert()之前,不是有个循环么?
难道在循环结束之前,会执行assert(a == 1)?
对此有疑问的读者,您需要补充一点关于猜测(冒险)执行的背景知识!可以找CPU参考手册看看。简单的说,在循环的时候,a== 1这个比较条件,有可能会被CPU预先加载a的值到流水线中。临时结果不会被保存到Cache或者Write buffer中,而是在CPU流水线中的临时结果寄存器中暂存起来 。
这是不是非常的反直觉?然而事实就是如此。
对CPU世界中反直觉的东西有兴趣的朋友,甚至可以看看量子力学方面的书,量子计算机真的需要懂量子力学。让《深入理解并行编程》一书中提到的“薛定谔的猫”来烧一下脑,这只猫已经折磨了无数天才的大脑。除了霍金,还有爱因斯坦的大脑!
五、关于内存屏障进一步的思考
本文仅仅从硬件的角度,引申出内存屏障。其目的是为了后续文章中,更好的讲解RCU。因此,并不会对内存屏障进行深入的剖析。但是,对于理解RCU来说,本文中的内存屏障知识已经可以了。
更深入的思考包括:
1、读屏障、写屏障、读依赖屏障的概念 2、各个体系架构中,屏障的实现、及其微妙的差别 3、深入思考内存屏障是否是必须的,有没有可能通过修改硬件,让屏障不再有用? 4、内存屏障的传递性,这是Linux系统中比较微妙而难于理解的概念。 5、单核架构中的屏障,是为了解决什么问题?怎么使用? 6、屏障在内核同步原语中的使用,满足了什么样的同步原语语义?
感兴趣的读者,可以参考如下资料:
1、我在CLK 2015大会上关于内存屏障的演讲: xiebaoyou的资源 2、《深入理解并行编程》中文版本: 《深入理解并行编程(博文视点出品)》([美]Paul E.Mckenney(保罗·E·麦肯尼))【摘要 书评 试读】- 京东图书
谢宝友:深入理解 Linux RCU 从硬件说起之内存屏障 - 云+社区 - 腾讯云 (tencent.com)
这篇关于谢宝友:深入理解 Linux RCU 从硬件说起之内存屏障的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



