本文主要是介绍编译器的构建:词法分析、语法分析、语义分析、中间代码生成、最终的代码优化、目标代码生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
编译器的构建是一个复杂的过程,主要包括词法分析、语法分析、语义分析、中间代码生成以及最终的代码优化和目标代码生成等步骤。每个步骤承担着编译过程中的特定任务,确保源代码能够被正确地转换为目标机器能执行的代码。
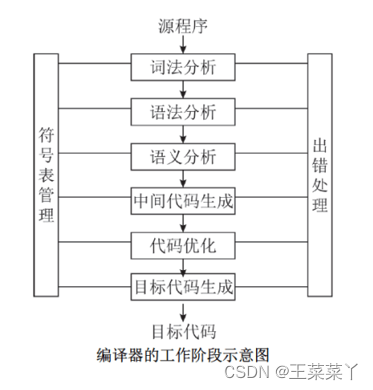
1. 词法分析(Lexical Analysis)
目的:将输入的字符流(源代码)转换成一系列的记号(tokens)。这些记号是构成语言的最小单位,例如关键字、标识符、常数、运算符等。
过程:扫描器(Scanner)读取源代码,去除空白字符和注释,并将字符序列分割成有意义的记号。例如,int a = 5;会被分解为记号INT, IDENTIFIER(a), EQUALS(=), NUMBER(5), SEMICOLON(; ) 。
工具:通常使用正则表达式来描述每种记号的模式,并使用工具如Lex、Flex等生成词法分析器。
2. 语法分析(Syntax Analysis)
目的:根据语言的语法规则(通常以上下文无关文法表示),将记号流组装成语法树(抽象语法树,AST)。这一步检查程序是否遵循了语言的语法。
过程:解析器(Parser)采取记号,并构建AST,每个节点代表语言构造(如表达式、语句、函数定义等)。例如,int a = 5;的AST可能有一个根节点表示声明,孩子节点表示类型int和变量a,以及初始化表达式5。
工具:常用的语法分析方法包括LL、LR、LALR等,工具如Yacc、Bison能够自动生成这部分代码。
3. 语义分析(Semantic Analysis)
目的:确保AST中的构造在语义上是有意义的,包括类型检查、变量使用前声明的检查、控制流检查等。
过程:遍历AST,检查静态语义规则是否得到满足。例如,确保用于算术运算的是数值类型,保证每个变量在使用前已声明,函数调用时实参与形参类型相符等。
工具:通常是编译器手动编码的部分,依赖于具体语言的语义规则。
4. 中间代码生成
目的:将AST转换为中间代码(如三地址代码),这种代码形式更接近机器代码,但保持与具体硬件无关,便于进行优化。
过程:遍历AST,生成一系列的中间指令,这些指令容易被进一步转化为机器代码。
5. 代码优化
目的:改进中间代码,提高运行效率而不改变程序的功能。
过程:包括删除无用代码、循环优化、常量折叠、强度削弱等多种技术。
6. 目标代码生成
目的:将优化后的中间代码转换为目标机器代码,通常是汇编代码或直接是机器码,依赖于目标平台。
过程:根据目标机器的指令集,将每条中间指令翻译成机器指令。
工具:特定平台的编译器后端,如GCC、LLVM等。
每个编译阶段都至关重要,它们共同确保了高级语言编写的程序能够被不同平台的计算机正确执行。
关键点凝练
- 词法分析
输入:源程序;输出:记号流;主要作用是:分析构成程序的字符,及由字符按照构造规则构成的符号是否符合程序语言的规定。 - 语法分析
输入:记号流;输出:语法树(分析树);语法分析阶段可以发现程序中所有的语法错误;主要作用是:对各条语句的结构进行合法性分析;分析程序中的句子结构是否正确。 - 语义分析
输入:语法树(分析树);主要作用是进行类型分析和检查;
注意:语法分析阶段可以发现程序中的所有语法错误,语义分析阶段不能发现程序中所有的语义错误:语义分析阶段可以发现静态语义错误,不能发现动态语义错误,动态语义错误运行时才能发现 - 目标代码生成
目标代码生成阶段的工作与具体的机器密切相关,寄存器的分配工作处于目标代码生成阶段
这篇关于编译器的构建:词法分析、语法分析、语义分析、中间代码生成、最终的代码优化、目标代码生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





