本文主要是介绍蒙特卡洛方法【强化学习】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
强化学习笔记
主要基于b站西湖大学赵世钰老师的【强化学习的数学原理】课程,个人觉得赵老师的课件深入浅出,很适合入门.
第一章 强化学习基本概念
第二章 贝尔曼方程
第三章 贝尔曼最优方程
第四章 值迭代和策略迭代
第五章 强化学习实践—GridWorld
第六章 蒙特卡洛方法
文章目录
- 强化学习笔记
- 一、 Motivating example
- 二、 MC-Basic method
- 三、MC Exploring Starts
- 四、MC without exploring starts
- 五、参考资料
前面介绍的值迭代和策略迭代算法,我们都假设模型已知,也就是环境的动态特性(比如各种概率)我们都预先知道。然而在实际问题中,我们可能对环境的动态特性并不是那么清楚,但是我们可以得到足够多的数据,那么我们同样可以用强化学习来建模解决这个问题,这类不利用模型的算法被称为Model-free的方法。Monte Carlo方法便是一种Model-free的方法。
一、 Motivating example
下面我们通过一个例子对Model-free有一个更加直观的了解,以及Monte Carlo方法是怎么做的,这个例子是概率论中的典型例子——Monty Hall Problem.
Suppose you’re on a game show, and you’re given the choice of three doors: Behind one door is a car; behind the others, goats. You pick a door, say No. 1, and the host, who knows what’s behind the other doors, opens another door, say No. 3, which has a goat. He then says to you, ‘Do you want to pick door No. 2?’ Is it to your advantage to take the switch?
由概率论的基本知识我们可以算出每种情况的概率如下:
- 不改变选择,选中car的概率为 p = 1 3 p=\frac13 p=31;
- 改变选择,选中car的概率 p = 2 3 p=\frac23 p=32.
如果我们不能通过理论知识得到这个概率,能不能通过做实验来得到这个结果呢?这就是Monte Carlo要做的事,我们可以通过python编程来模拟这个游戏:
import numpy as np
import matplotlib.pyplot as pltdef game(switch):doors = [0, 0, 1] # 0代表山羊,1代表汽车np.random.shuffle(doors)# 参赛者初始选择一扇门choice = np.random.randint(3)# 主持人打开一扇有山羊的门reveal = np.random.choice([i for i in range(3) if i != choice and doors[i] == 0])if switch:new_choice = [i for i in range(3) if i != choice and i != reveal][0]return doors[new_choice] # 返回参赛者的奖励结果,1代表获得汽车,0代表获得山羊else:return doors[choice]# 模拟实验
num_trials = 2000
switch_rewards = [] # 记录每次选择换门后的奖励
no_switch_rewards = [] # 记录每次选择坚持原先选择的奖励
switch_wins = 0 # 记录换门策略的获胜次数
no_switch_wins = 0 # 记录坚持原先选择的获胜次数for i in range(num_trials):# 选择换门switch_result = game(switch=True)switch_rewards.append(switch_result)if switch_result == 1:switch_wins += 1# 选择坚持原先选择的门no_switch_result = game(switch=False)no_switch_rewards.append(no_switch_result)if no_switch_result == 1:no_switch_wins += 1# 计算每次试验的平均奖励
switch_avg_rewards = np.cumsum(switch_rewards) / (np.arange(num_trials) + 1)
no_switch_avg_rewards = np.cumsum(no_switch_rewards) / (np.arange(num_trials) + 1)# 绘制平均奖励曲线
plt.figure(dpi=150)
plt.plot(np.arange(num_trials), switch_avg_rewards, label='换门')
plt.plot(np.arange(num_trials), no_switch_avg_rewards, label='坚持原先选择')
plt.xlabel('试验次数')
plt.ylabel('平均奖励')
plt.title('2000次试验中的平均奖励')
plt.legend()
plt.show()# 输出获胜概率
switch_win_percentage = switch_wins / num_trials
no_switch_win_percentage = no_switch_wins / num_trials
print("选择换门的获胜概率:", switch_win_percentage)
print("选择坚持原先选择的获胜概率:", no_switch_win_percentage)
结果如下:
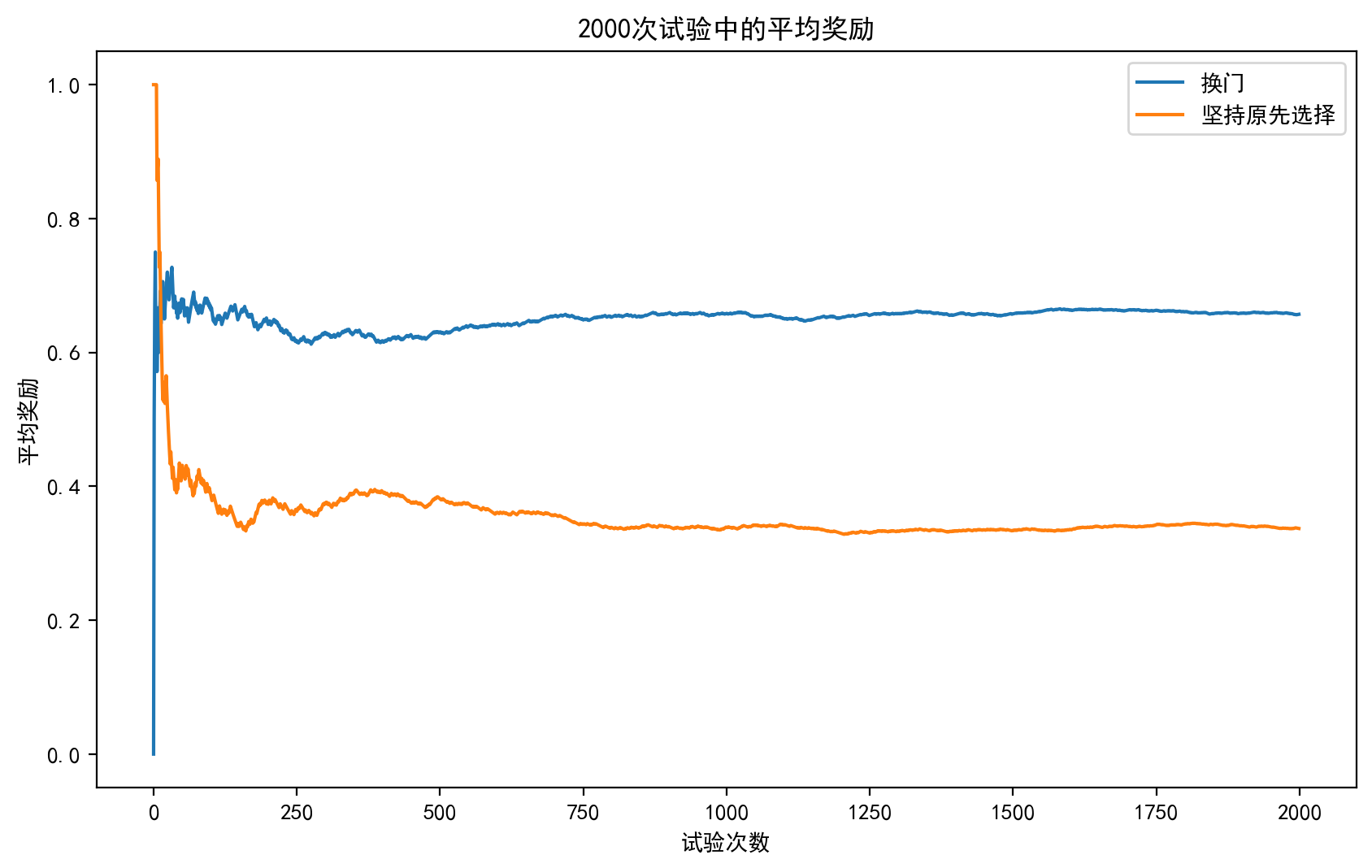
我们可以看到,随着实验次数的增加,概率逐渐收敛到理论值,而这有大数定理进行理论保证.通过这个例子我们可以看到即使我们不知道模型的某些性质(这里是p),但我们可以通过Monte Carlo的方法来得到近似值.

- 第一个等式说明样本均值是 E [ X ] \mathbb{E}[X] E[X]的无偏估计;
二、 MC-Basic method
我们回顾一下Policy iteration 的核心算法步骤:
{ Policy evaluation: v π k = r π k + γ P π k v π k Policy improvement: π k + 1 = arg max π ( r π + γ P π v π k ) \left\{\begin{array}{l}\text{Policy evaluation: }v_{\pi_k}=r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k}\\\text{Policy improvement: }\pi_{k+1}=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{\pi_k})\end{array}\right. {Policy evaluation: vπk=rπk+γPπkvπkPolicy improvement: πk+1=argmaxπ(rπ+γPπvπk)
其中我们将PI展开如下:
π k + 1 ( s ) = arg max π ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π k ( s ′ ) ] = arg max π ∑ a π ( a ∣ s ) q π k ( s , a ) , s ∈ S \begin{aligned}\pi_{k+1}(s)&=\arg\max_\pi\sum_a\pi(a|s)\left[\sum_rp(r|s,a)r+\gamma\sum_{s'}p(s'|s,a)v_{\pi_k}(s')\right]\\&=\arg\max_\pi\sum_a\pi(a|s)q_{\pi_k}(s,a),\quad s\in\mathcal{S}\end{aligned} πk+1(s)=argπmaxa∑π(a∣s)[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπk(s′)]=argπmaxa∑π(a∣s)qπk(s,a),s∈S
从上面的表达式我们可以看到,无论是算 v v v还是 q q q都需要知道模型的概率 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a),但在Model-free算法里我们不知道 p p p,所以需要用Monte Carlo的方法进行估计,但是在这里我们不估计 p p p,而是直接估计 q ( s , a ) q(s,a) q(s,a),因为有了 p p p还需要算一下 q q q,所以直接估计 q q q更高效,下面给出伪代码.

其核心思想就是通过Monte Carlo的方法来估计所有的 q ( s , a ) q(s,a) q(s,a),通过实验得到很多 q ( s , a ) q(s,a) q(s,a)的数据,然后用均值作为其准确值的估计.

三、MC Exploring Starts
在上面的算法中,给定一个策略 π \pi π,我们可以得到如下的一个episode:

- 每一个
episode包含多个 ( s , a ) (s,a) (s,a),但在上面的算法中我们只用来计算第一个 ( s , a ) (s,a) (s,a)的 q q q - 显然我们可以充分利用每一个
episode的数据

- 每个
episode的数据只用来计算第一个 q ( s , a ) q(s,a) q(s,a)的值被称为first-visit method; - 每个
episode的数据用来计算episode中每个 q ( s , a ) q(s,a) q(s,a)的值被称为every-visit method.

Note:
- 要确保所有 ( s , a ) (s,a) (s,a)都被计算到,
Exploring Starts意味着我们需要从每个 ( s , a ) (s,a) (s,a)对开始生成足够多的episode. - 在实践中,该算法很难实现的。对于许多应用,特别是那些涉及与环境的物理交互的应用,很难从每个state-action pair.作为起始点得到一段
episode. - 因此,理论和实践之间存在差距。我们可以去掉
Exploring Starts的假设吗?答案是肯定的,可以通过使用soft policy来实现这一点。
四、MC without exploring starts
Soft Policy
如果一个策略 π \pi π采取任何行动的概率为正,则称为soft policy.
- 在soft policy下,一些足够长的episodes中可能就会包含每个状态-动作对足够多次;
- 然后,我们不需要从每个状态-动作对开始采集大量episodes.
下面介绍一种soft policy—— ε \varepsilon ε -greedy策略:
π ( a ∣ s ) = { 1 − ε ∣ A ( s ) ∣ ( ∣ A ( s ) ∣ − 1 ) , for the greedy action, ε ∣ A ( s ) ∣ , for the other ∣ A ( s ) ∣ − 1 actions. \pi(a \mid s)= \begin{cases}1-\frac{\varepsilon}{|\mathcal{A}(s)|}(|\mathcal{A}(s)|-1), & \text { for the greedy action, } \\ \frac{\varepsilon}{|\mathcal{A}(s)|}, & \text { for the other }|\mathcal{A}(s)|-1 \text { actions. }\end{cases} π(a∣s)={1−∣A(s)∣ε(∣A(s)∣−1),∣A(s)∣ε, for the greedy action, for the other ∣A(s)∣−1 actions.
其中 ε ∈ [ 0 , 1 ] \varepsilon \in[0,1] ε∈[0,1]和 ∣ A ( s ) ∣ |\mathcal{A}(s)| ∣A(s)∣是 s s s的总数。
- 选择贪婪行动的机会总是大于其他行动,因为 1 − ε ∣ A ( s ) ∣ ( ∣ A ( s ) ∣ − 1 ) = 1 − ε + ε ∣ A ( s ) ∣ ≥ ε ∣ A ( s ) ∣ 1-\frac{\varepsilon}{|\mathcal{A}(s)|}(|\mathcal{A}(s)|-1)=1-\varepsilon+\frac{\varepsilon}{|\mathcal{A}(s)|} \geq \frac{\varepsilon}{|\mathcal{A}(s)|} 1−∣A(s)∣ε(∣A(s)∣−1)=1−ε+∣A(s)∣ε≥∣A(s)∣ε。
- 为什么使用 ε \varepsilon ε -greedy?Balance between exploitation and exploration
- 当 ε = 0 \varepsilon=0 ε=0,它变得贪婪! Less exploration but more exploitation.
- 当 ε = 1 \varepsilon=1 ε=1时,它成为均匀分布。More exploration but less exploitation.
如何将 ε \varepsilon ε -greedy嵌入到MC-Basic的强化学习算法中?现在,将策略改进步骤改为:
π k + 1 ( s ) = arg max π ∈ Π ε ∑ a π ( a ∣ s ) q π k ( s , a ) , \pi_{k+1}(s)=\arg \max _{\pi \in \Pi_{\varepsilon}} \sum_a \pi(a \mid s) q_{\pi_k}(s, a), πk+1(s)=argπ∈Πεmaxa∑π(a∣s)qπk(s,a),
其中 Π ε \Pi_{\varepsilon} Πε表示所有 ε \varepsilon ε -greedy策略的集合,其固定值为 ε \varepsilon ε。这里的最佳策略是
π k + 1 ( a ∣ s ) = { 1 − ∣ A ( s ) ∣ − 1 ∣ A ( s ) ∣ ε , a = a k ∗ , 1 ∣ A ( s ) ∣ ε , a ≠ a k ∗ . \pi_{k+1}(a \mid s)= \begin{cases}1-\frac{|\mathcal{A}(s)|-1}{|\mathcal{A}(s)|} \varepsilon, & a=a_k^*, \\ \frac{1}{|\mathcal{A}(s)|} \varepsilon, & a \neq a_k^* .\end{cases} πk+1(a∣s)={1−∣A(s)∣∣A(s)∣−1ε,∣A(s)∣1ε,a=ak∗,a=ak∗.
- MC ε \varepsilon ε -greedy与MC Exploring Starts相同,只是前者使用 ε \varepsilon ε -greedy策略。
- 它不需要从每个(s,a)出发开始得到episode,但仍然需要以不同的形式访问所有状态-动作对。
算法伪代码如下图所示:

五、参考资料
- Zhao, S… Mathematical Foundations of Reinforcement Learning. Springer Nature Press and Tsinghua University Press.
- Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
这篇关于蒙特卡洛方法【强化学习】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



