本文主要是介绍Selenium+Chrome Driver 爬取搜狐页面信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
进行selenium包和chromedriver驱动的安装
安装selenium包
在命令行或者anaconda prompt 中输入 pip install Selenium
安装 chromedriver
先查看chrome浏览器的版本
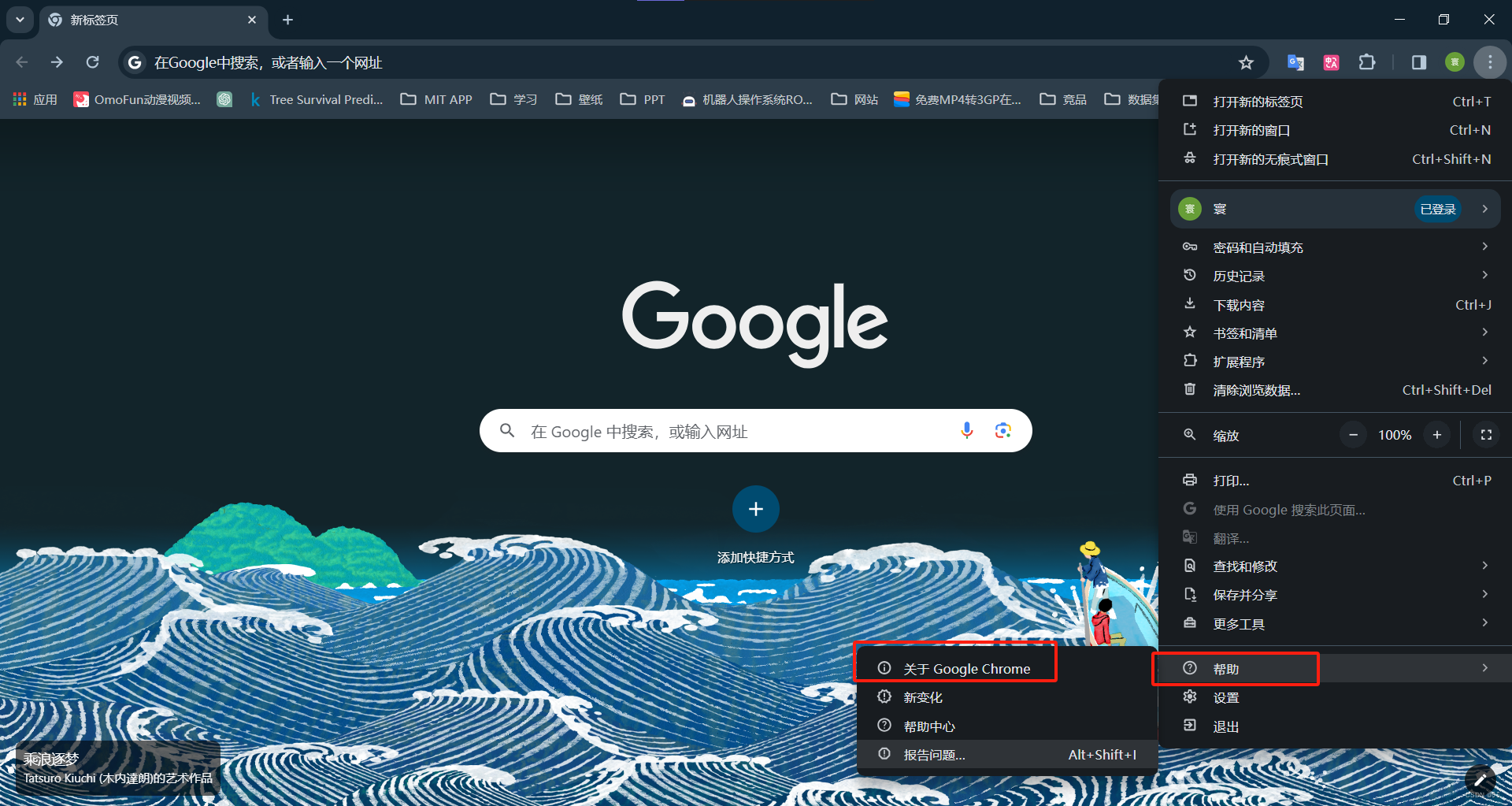

这里是 123.0.6312.106 版
然后在http://npm.taobao.org/mirrors/chromedriver/或者https://googlechromelabs.github.io/chrome-for-testing/
中下载对应版本的chromediver
由于没有106版的这里下的是105版

下载解压后
把exe文件复制到chrome浏览器的安装目录和
python的安装目录scripts文件夹下 或者 放到Anaconda的scripts文件夹下
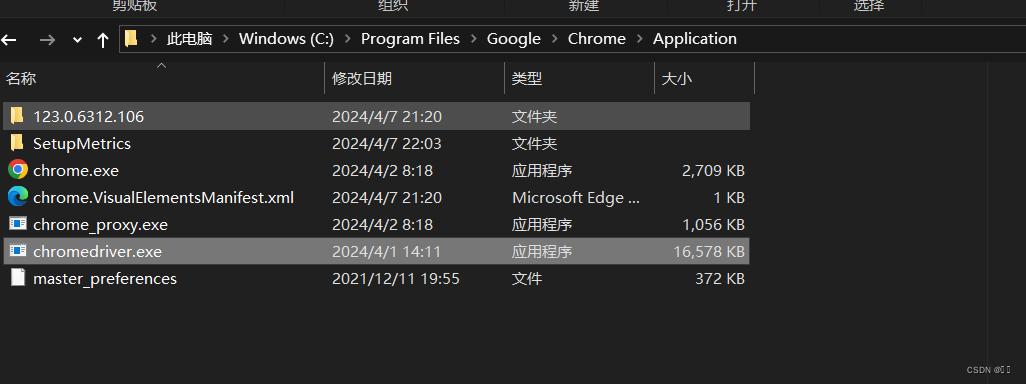
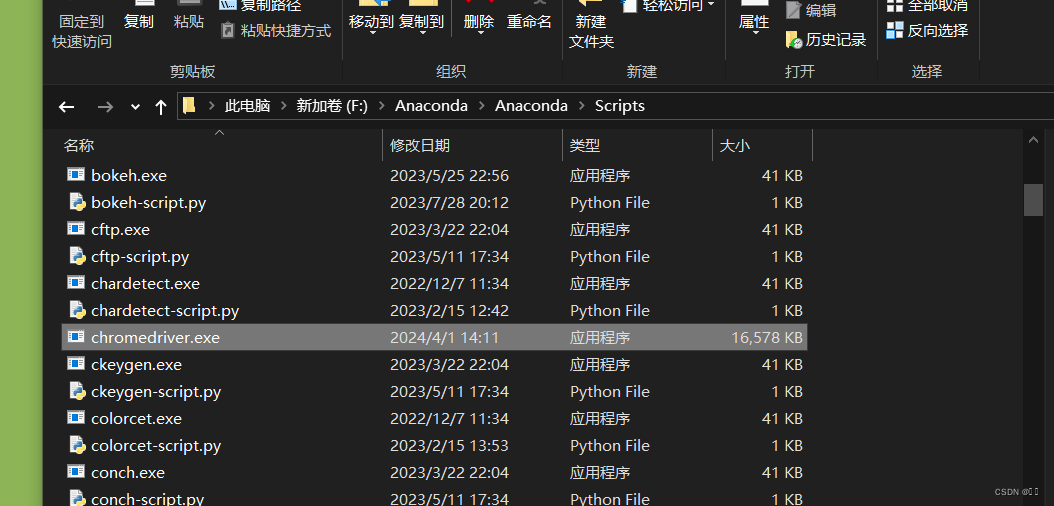
或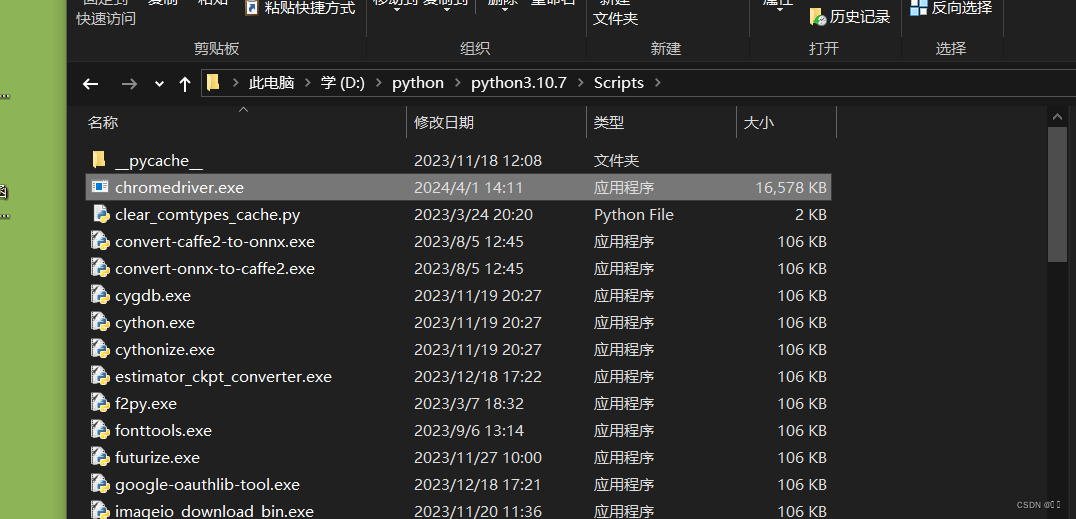
测试
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.sohu.com/')
自动打开搜狐页面即可

注: 浏览器自动更新后,chromediver 也需要重新下载,并按以上路径配置
Selenium+Chrome Driver 爬取搜狐页面信息
在selenium中不同的版本,语法的用法具有差异
按照书上的用chromedriver访问搜狐页面代码报错如下
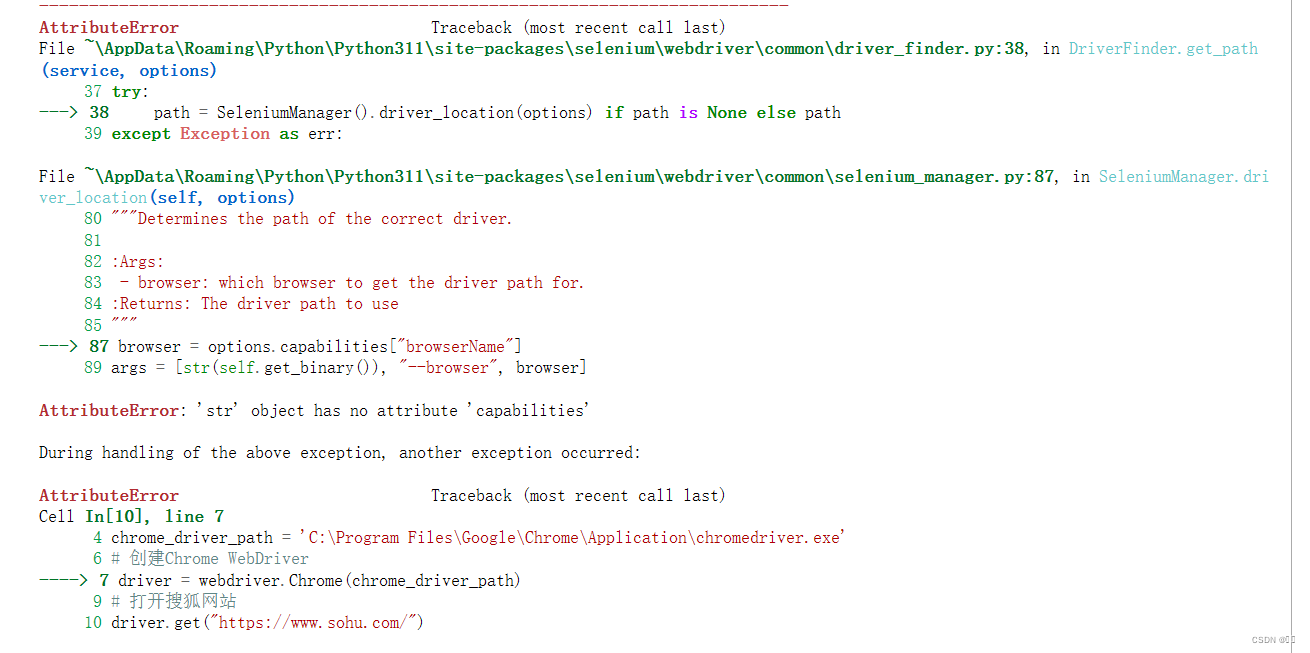
chrome_driver_path传给webdriver.Chrome()时方式不对
可参考下面这位博主的语法进行修改
http://t.csdnimg.cn/xxGhp
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
chrome_driver_path = 'F:/chromedriver/chromedriver-win64/chromedriver.exe'# 创建 Chrome WebDriver
service = Service(chrome_driver_path)
driver = webdriver.Chrome(service=service)
代码实现
导入包
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium import webdriver:
导入了Selenium库中的webdriver模块,它包含了各种WebDriver的实现,用于模拟不同的浏览器行为。
from selenium.webdriver.chrome.service import Service:
导入了Service类,它用于配置和启动ChromeDriver服务。
from selenium.webdriver.chrome.options import Options:
导入了Options类,它用于配置Chrome浏览器的选项,例如设置浏览器的头less模式等。
from selenium.webdriver.common.by import By:
导入了By类,它定义了一些用于查找元素的方法,例如通过class name、id等。
配置ChromeDriver 的路径并启动浏览器
# 设置 ChromeDriver 的路径
chrome_driver_path = 'F:/chromedriver/chromedriver-win64/chromedriver.exe'# 创建 Chrome WebDriver# # 创建 Chrome Options 对象
# chrome_options = Options()
# chrome_options.add_argument('--headless') # 无头模式,即不显示浏览器窗口service = Service(chrome_driver_path)
driver = webdriver.Chrome(service=service)# 打开搜狐网站
driver.get("https://www.sohu.com/")
获取当前页面的Html源码
# 获取当前网页的 HTML 源码
html_source = driver.page_source
print("HTML 源码:")
print(html_source)
运行结果如图所示

获取当前页面的URL
# 获取当前网页的 URL
current_url = driver.current_url
print("\n当前网页的 URL:")
print(current_url)
运行结果如图所示

获取classname为‘txt’的页面元素
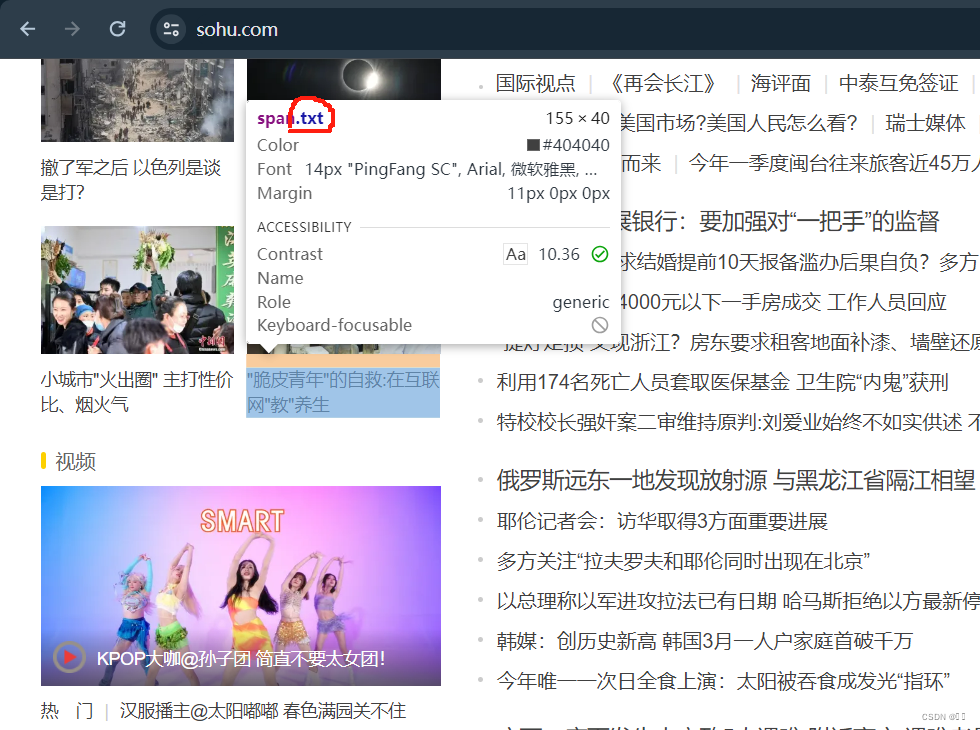

# 使用 find_elements 方法查找 class 属性为 'txt' 的元素
txt_elements = driver.find_elements(By.CLASS_NAME, "txt")# 遍历输出每个元素的文本内容
for element in txt_elements:print(element.text)
运行结果如图所示

获取 标签 属性为 ‘footer’ 的元素文本
# 使用 find_elements 方法查找 标签 属性为 'footer' 的元素
txt_elements = driver.find_elements(By.TAG_NAME, "footer")# 遍历输出每个元素的文本内容
for element in txt_elements:print(element.text)
运行结果如下图所示

获取 class 属性为 ‘titleStyle’ 的元素的文本及href链接
# 使用 find_elements 方法查找 class 属性为 'titleStyle' 的元素
title_elements = driver.find_elements(By.CLASS_NAME, "titleStyle")# 遍历输出每个元素的文本内容
for element in title_elements:text = element.texthref = element.get_attribute("href")print(f"Text: {text}, Href: {href}")
运行结果如下图所示

获取 xpath 搜狐首页的导航栏标签 及 href链接
# 使用 find_elements 方法查找 xpath 搜狐首页的导航栏标签
title_elements = driver.find_elements(By.XPATH, "/html/body/div[2]/div/nav[@class='nav area']//a")# 遍历输出每个元素的文本内容
for element in title_elements:text = element.get_attribute("innerHTML").strip()if text:href = element.get_attribute("href")print(f"Text: {text}, Href: {href}")
运行结果如下图示
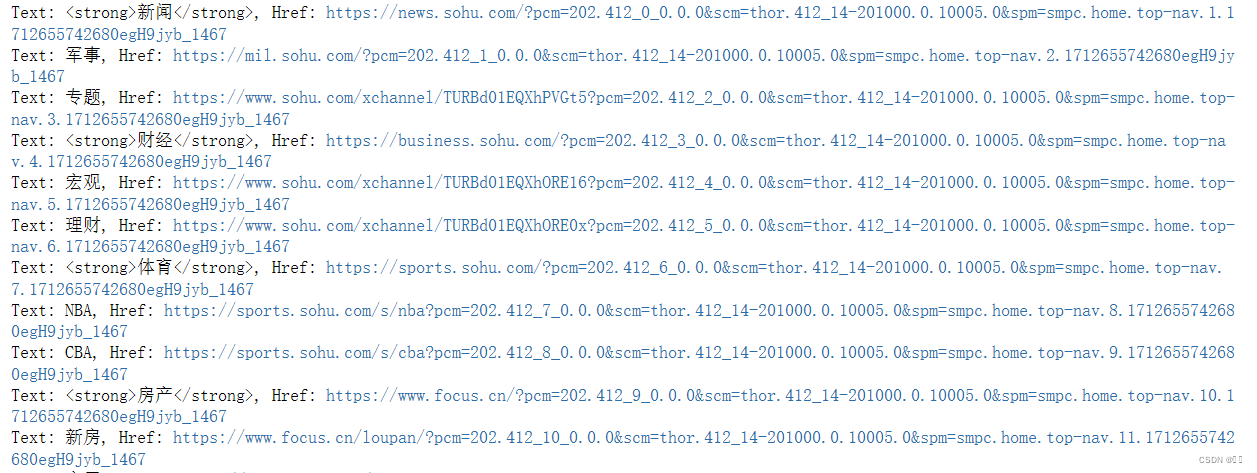
这里运行出来后大的标签会有<strong></strong>
可以通过正则表达式进行优化
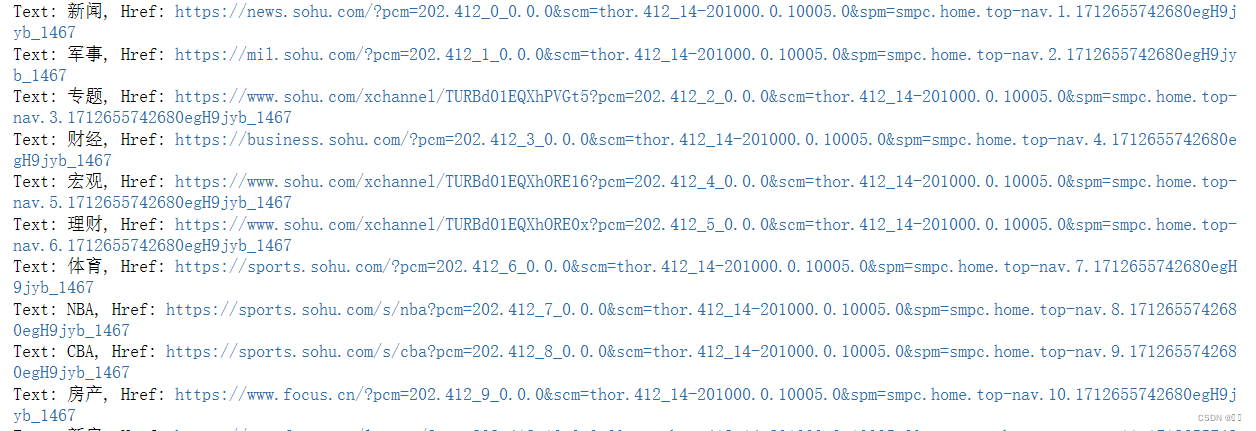
优化代码如下
import re# 使用 find_elements 方法查找 xpath 搜狐首页的导航栏标签
title_elements = driver.find_elements(By.XPATH, "/html/body/div[2]/div/nav[@class='nav area']//a")# 遍历输出每个元素的文本内容
for element in title_elements:inner_html = element.get_attribute("innerHTML")text = re.sub(r'<[^>]*>', '', inner_html).strip()if text:href = element.get_attribute("href")print(f"Text: {text}, Href: {href}")
<:匹配左尖括号,表示 HTML 标签的开始。
[^>]:匹配除了右尖括号之外的任何字符。
*:匹配前面的字符零次或多次,即匹配任意数量的除右尖括号之外的字符。 >:匹配右尖括号,表示 HTML 标签的结束。
re.sub(pattern, repl, string)
pattern:要匹配的正则表达式模式。
repl:用于替换匹配文本的字符串。
string:要进行替换操作的原始字符串。
运行结果如下图所示
关闭 WebDriver
# 关闭 WebDriver
driver.quit()
完整代码
import re
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By# 设置 ChromeDriver 的路径
chrome_driver_path = 'F:/chromedriver/chromedriver-win64/chromedriver.exe'# 创建 Chrome WebDriver# # 创建 Chrome Options 对象
# chrome_options = Options()
# chrome_options.add_argument('--headless') # 无头模式,即不显示浏览器窗口service = Service(chrome_driver_path)
driver = webdriver.Chrome(service=service)# 打开搜狐网站
driver.get("https://www.sohu.com/")# 获取当前网页的 HTML 源码
html_source = driver.page_source
print("HTML 源码:")
print(html_source)# 获取当前网页的 URL
current_url = driver.current_url
print("\n当前网页的 URL:")
print(current_url)# 使用 find_elements 方法查找 class 属性为 'txt' 的元素
txt_elements = driver.find_elements(By.CLASS_NAME, "txt")# 遍历输出每个元素的文本内容
for element in txt_elements:print(element.text)# 使用 find_elements 方法查找 标签 属性为 'footer' 的元素
txt_elements = driver.find_elements(By.TAG_NAME, "footer")# 遍历输出每个元素的文本内容
for element in txt_elements:print(element.text)# 使用 find_elements 方法查找 class 属性为 'titleStyle' 的元素
title_elements = driver.find_elements(By.CLASS_NAME, "titleStyle")# 遍历输出每个元素的文本内容
for element in title_elements:text = element.texthref = element.get_attribute("href")print(f"Text: {text}, Href: {href}")# # 使用 find_elements 方法查找 xpath 搜狐首页的导航栏标签
# title_elements = driver.find_elements(By.XPATH, "/html/body/div[2]/div/nav[@class='nav area']//a")# # 遍历输出每个元素的文本内容
# for element in title_elements:
# text = element.get_attribute("innerHTML").strip()
# if text:
# href = element.get_attribute("href")
# print(f"Text: {text}, Href: {href}")# 使用 find_elements 方法查找 xpath 搜狐首页的导航栏标签
title_elements = driver.find_elements(By.XPATH, "/html/body/div[2]/div/nav[@class='nav area']//a")# 遍历输出每个元素的文本内容
for element in title_elements:inner_html = element.get_attribute("innerHTML")text = re.sub(r'<[^>]*>', '', inner_html).strip()if text:href = element.get_attribute("href")print(f"Text: {text}, Href: {href}")# 关闭 WebDriver
driver.quit()
这篇关于Selenium+Chrome Driver 爬取搜狐页面信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






