本文主要是介绍ETL工具-nifi干货系列 第九讲 处理器EvaluateJsonPath,根据JsonPath提取字段,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、其实这一节课本来按照计划一起学习RouteOnAttribute处理器(相当于java中的ifelse,switch case 控制语句),但是在学习的过程中遇到了一些问题。RouteOnAttribute 需要依赖处理器EvaluateJsonPath,所以本节课我们一起来学习下EvaluateJsonPath处理器。如下图所示:
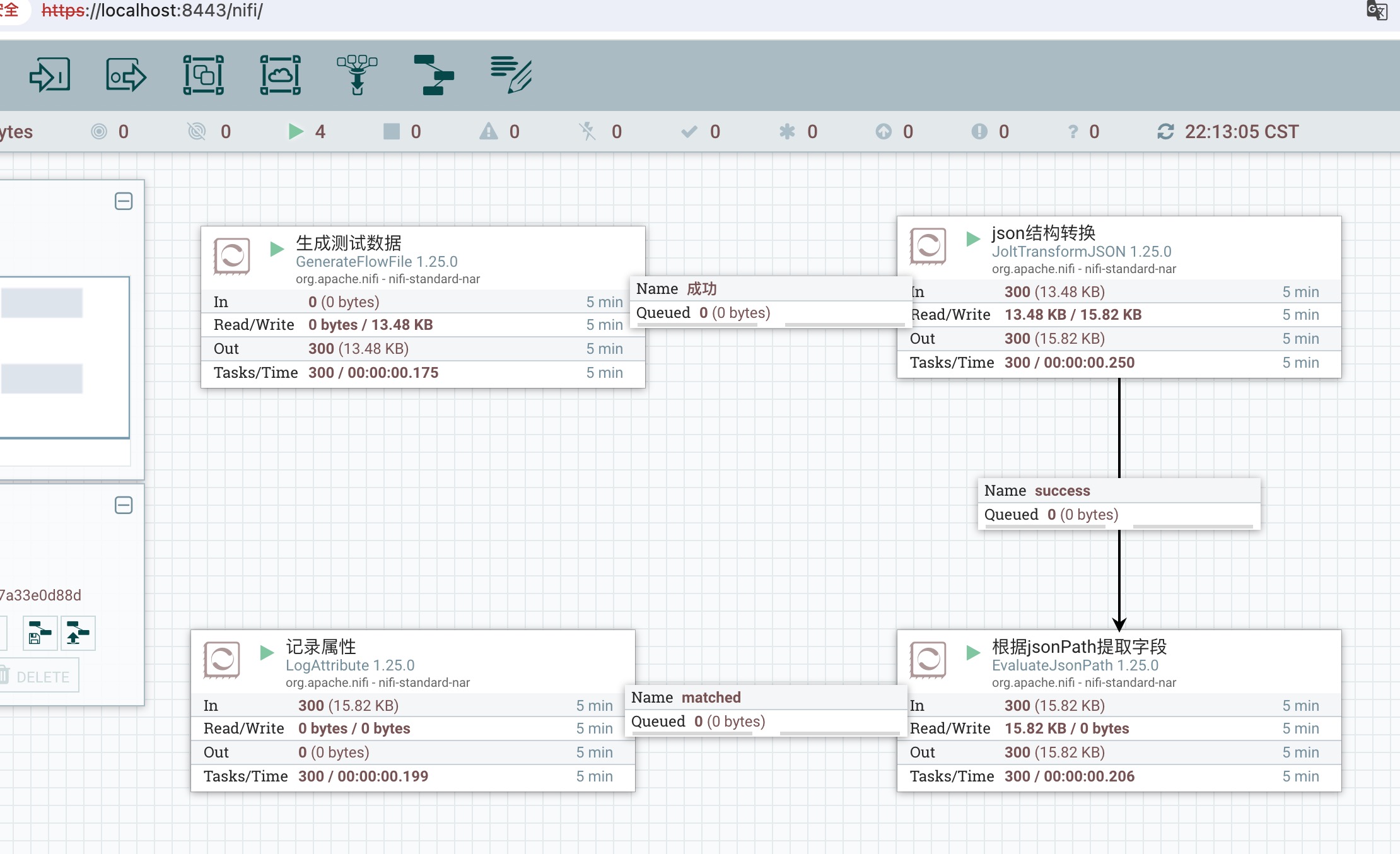
本节课的示例依然很简单:
GenerateFlowFile 产生测试json字符串:{"name":"Javax 小金刚","id":"2"}
JoltTransformJSON 转换json结构:{"person":{"name":"Javax 小金刚","id":"2"}}
EvaluateJsonPath 提取指定字段(下一节课进行路由)
LogAttribute 打印属性到日志文件nifi-app.log
2、EvaluateJsonPath,此处理器的作用是根据jsonPath提取json数据中指定的属性

Destination:下拉选项有flowfile-content和flowfile-attribute,默认值flowfile-content,用于指示 JsonPath 提取结果是写入到 FlowFile 内容还是 FlowFile 属性中。如果选择属性,必须指定属性名称。如果设置为 flowfile-content,则只能指定一个 JsonPath,属性名称会被忽略。这里选择flowfile-attribute进行演示。
Return Type:下拉选项有auto-detect、json、scalar,默认值为auto-detect,用于指示 JSON Path 表达式的期望返回类型属性。选择 'auto-detect' 会根据目标的设置来确定返回类型:对于目标为 'flowfile-content' 的情况,返回类型将设置为 'json';对于目标为 'flowfile-attribute' 的情况,返回类型将设置为 'scalar'。
Path Not Found Behavior:下拉选项有warn、ignore、skip,默认值为ignore,目标设置为 'flowfile-attribute' 时,如何处理缺失的 JSON Path 表达式的方式。选择 'warn' 会在找不到 JSON Path 表达式时生成警告。选择 'skip' 会忽略任何未匹配的 JSON Path 表达式,不生成对应的属性。
Null Value Representation:下拉选项有empty string、the string 'null',默认值empty string,对于 JSON Path 表达式返回空值时的期望表示方式。
Max String Length:默认值20 MB,这解析 JSON 文档时字符串值的最大允许长度的描述。
userId:$.person.userId,此处为自定义属性名称,json path。
3、LogAttribute ,在指定的日志级别上记录 FlowFile 的属性,如下所示,此处理器在debug的时候比较有用。比较简单不做介绍。



这篇关于ETL工具-nifi干货系列 第九讲 处理器EvaluateJsonPath,根据JsonPath提取字段的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






