本文主要是介绍YOLOV8注意力改进方法:DilateFormer多尺度空洞 Transformer(附改进代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原论文地址:原论文下载地址
即插即用的多尺度全局注意力机制
本文提出了一种新颖的多尺度空洞 Transformer,简称DilateFormer,以用于视觉识别任务。原有的 ViT 模型在计算复杂性和感受野大小之间的权衡上存在矛盾。众所周知,ViT 模型使用全局注意力机制,能够在任意图像块之间建立长远距离上下文依赖关系,但是全局感受野带来的是平方级别的计算代价。同时,有些研究表明,在浅层特征上,直接进行全局依赖性建模可能存在冗余,因此是没必要的。为了克服这些问题,作者提出了一种新的注意力机制——多尺度空洞注意力(MSDA)。MSDA 能够模拟小范围内的局部和稀疏的图像块交互,这些发现源自于对 ViTs 在浅层次上全局注意力中图像块交互的分析。作者发现在浅层次上,注意力矩阵具有局部性和稀疏性两个关键属性,这表明在浅层次的语义建模中,远离查询块的块大部分无关,因此全局注意力模块中存在大量的冗余。
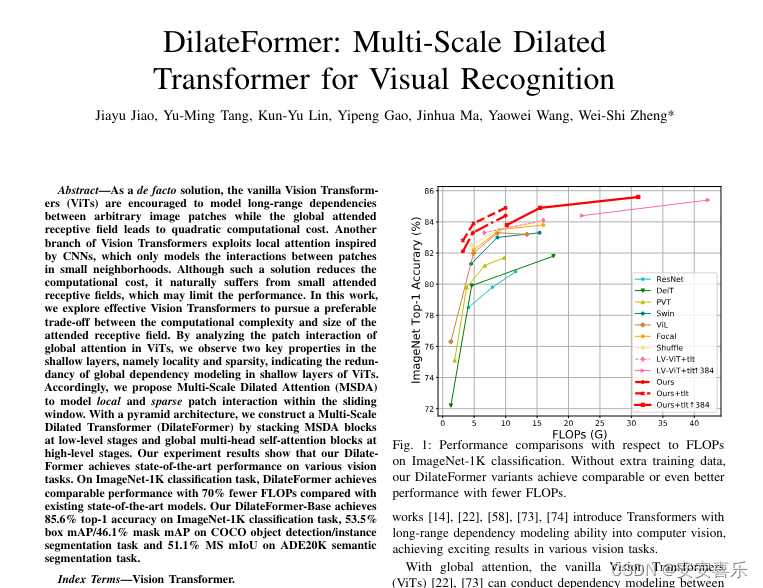

DilateFormer 是一个以金字塔结构为基础的深度学习模型,它主要设计用来处理基础的视觉任务。DilateFormer 的关键设计概念是利用多尺度空洞注意力(Multi-Scale Dilated Attention, MSDA)来有效捕捉多尺度的语义信息,并减少自注意力机制的冗余。
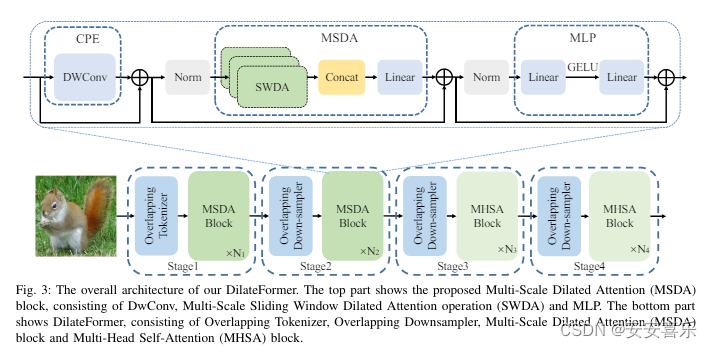 如上图所示,
如上图所示,DilateFormer的整体架构主要由四个阶段构成。在第一阶段和第二阶段,使用 MSDA,而在后两个阶段,使用普通的多头自注意力(MHSA)。对于图像输入,DilateFormer 首先使用重叠的分词器进行 patch 嵌入,然后通过交替控制卷积核的步长大小(1或2)来调整输出特征图的分辨率。对于前一阶段的 patches,采用了一个重叠的下采样器,具有重叠的内核大小为 3,步长为 2。整个模型的每一部分都使用了条件位置嵌入(CPE)来使位置编码适应不同分辨率的输入。
2.MSDA引入到YOLOv8的步骤:
2.1 MSDA加入ultralytics/nn/attention/dilateformer.py
import torch
import torch.nn as nn
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass DilateAttention(nn.Module):"Implementation of Dilate-attention"def __init__(self, head_dim, qk_scale=None, attn_drop=0, kernel_size=3, dilation=1):super().__init__()self.head_dim = head_dimself.scale = qk_scale or head_dim ** -0.5self.kernel_size=kernel_sizeself.unfold = nn.Unfold(kernel_size, dilation, dilation*(kernel_size-1)//2, 1)self.attn_drop = nn.Dropout(attn_drop)def forward(self,q,k,v):#B, C//3, H, WB,d,H,W = q.shapeq = q.reshape([B, d//self.head_dim, self.head_dim, 1 ,H*W]).permute(0, 1, 4, 3, 2) # B,h,N,1,dk = self.unfold(k).reshape([B, d//self.head_dim, self.head_dim, self.kernel_size*self.kernel_size, H*W]).permute(0, 1, 4, 2, 3) #B,h,N,d,k*kattn = (q @ k) * self.scale # B,h,N,1,k*kattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)v = self.unfold(v).reshape([B, d//self.head_dim, self.head_dim, self.kernel_size*self.kernel_size, H*W]).permute(0, 1, 4, 3, 2) # B,h,N,k*k,dx = (attn @ v).transpose(1, 2).reshape(B, H, W, d)return xclass MultiDilatelocalAttention(nn.Module):"Implementation of Dilate-attention"def __init__(self, dim, num_heads=4, qkv_bias=False, qk_scale=None,attn_drop=0.,proj_drop=0., kernel_size=3, dilation=[1, 2]):super().__init__()self.dim = dimself.num_heads = num_headshead_dim = dim // num_headsself.dilation = dilationself.kernel_size = kernel_sizeself.scale = qk_scale or head_dim ** -0.5self.num_dilation = len(dilation)assert num_heads % self.num_dilation == 0, f"num_heads{num_heads} must be the times of num_dilation{self.num_dilation}!!"self.qkv = nn.Conv2d(dim, dim * 3, 1, bias=qkv_bias)self.dilate_attention = nn.ModuleList([DilateAttention(head_dim, qk_scale, attn_drop, kernel_size, dilation[i])for i in range(self.num_dilation)])self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)def forward(self, x):x = x.permute(0, 3, 1, 2) # B, C, H, WB, C, H, W = x.shapeqkv = self.qkv(x).reshape(B, 3, self.num_dilation, C //self.num_dilation, H, W).permute(2, 1, 0, 3, 4, 5)#num_dilation,3,B,C//num_dilation,H,Wx = x.reshape(B, self.num_dilation, C//self.num_dilation, H, W).permute(1, 0, 3, 4, 2 )# num_dilation, B, H, W, C//num_dilationfor i in range(self.num_dilation):x[i] = self.dilate_attention[i](qkv[i][0], qkv[i][1], qkv[i][2])# B, H, W,C//num_dilationx = x.permute(1, 2, 3, 0, 4).reshape(B, H, W, C)x = self.proj(x)x = self.proj_drop(x)return xclass DilateBlock(nn.Module):"Implementation of Dilate-attention block"def __init__(self, dim, num_heads=4, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0., attn_drop=0.,drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm, kernel_size=3, dilation=[1, 2],cpe_per_block=False):super().__init__()self.dim = dimself.num_heads = num_headsself.mlp_ratio = mlp_ratioself.kernel_size = kernel_sizeself.dilation = dilationself.cpe_per_block = cpe_per_blockif self.cpe_per_block:self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)self.norm1 = norm_layer(dim)self.attn = MultiDilatelocalAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop=attn_drop, kernel_size=kernel_size, dilation=dilation)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):x = x.permute(0, 3, 2, 1)x = x + self.drop_path(self.attn(self.norm1(x)))x = x.permute(0, 3, 2, 1)#B, C, H, Wreturn xdef autopad(k, p=None, d=1): # kernel, padding, dilation# Pad to 'same' shape outputsif d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class C2f(nn.Module):# CSP Bottleneck with 2 convolutionsdef __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))def forward(self, x):y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expandsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C2f_MultiDilatelocalAttention(nn.Module):# CSP Bottleneck with 2 convolutionsdef __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(DilateBlock(self.c) for _ in range(n))def forward(self, x):y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))2.2 注册ultralytics/nn/tasks.py
在tasks.py文件的上面导入部分粘贴下面的代码
DilateBlock,C2f_MultiDilatelocalAttention进行注册
from ultralytics.nn.attention.dilateformer import DilateBlock,C2f_MultiDilatelocalAttention修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3):
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,BottleneckCSP, C1, C2, DilateBlock,C2f_MultiDilatelocalAttention):c1, c2 = ch[f], args[0]if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)c2 = make_divisible(min(c2, max_channels) * width, 8)args = [c1, c2, *args[1:]]if m in (KWConv, C2f_KW):args.insert(2, f'layer{i}')args.insert(2, warehouse_manager)if m in (BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, C3x, DilateBlock,C2f_MultiDilatelocalAttention):args.insert(2, n) # number of repeatsn = 12.3 yolov8_C2f_MultiDilatelocalAttention
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f_MultiDilatelocalAttention, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f_MultiDilatelocalAttention, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f_MultiDilatelocalAttention, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f_MultiDilatelocalAttention, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)2.4 yolov8_DilateBlock.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, DilateBlock, [1024]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
这篇关于YOLOV8注意力改进方法:DilateFormer多尺度空洞 Transformer(附改进代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




